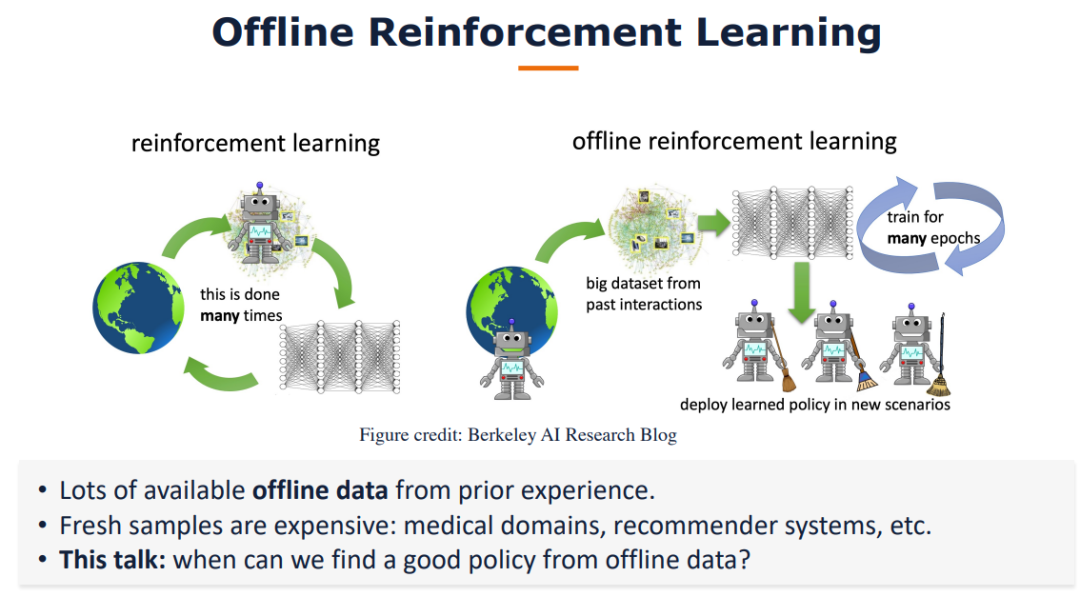
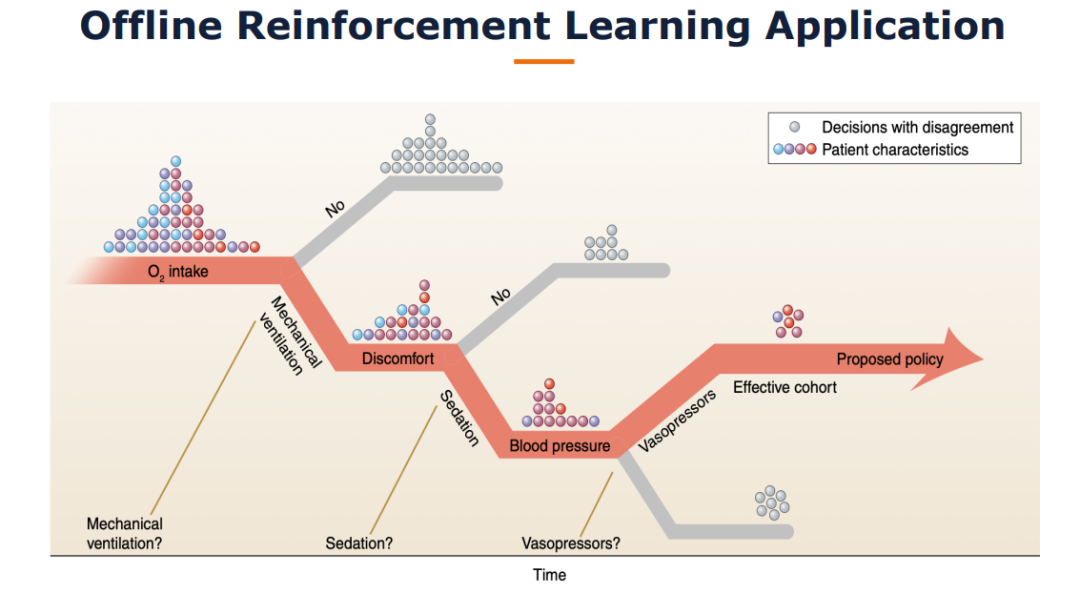
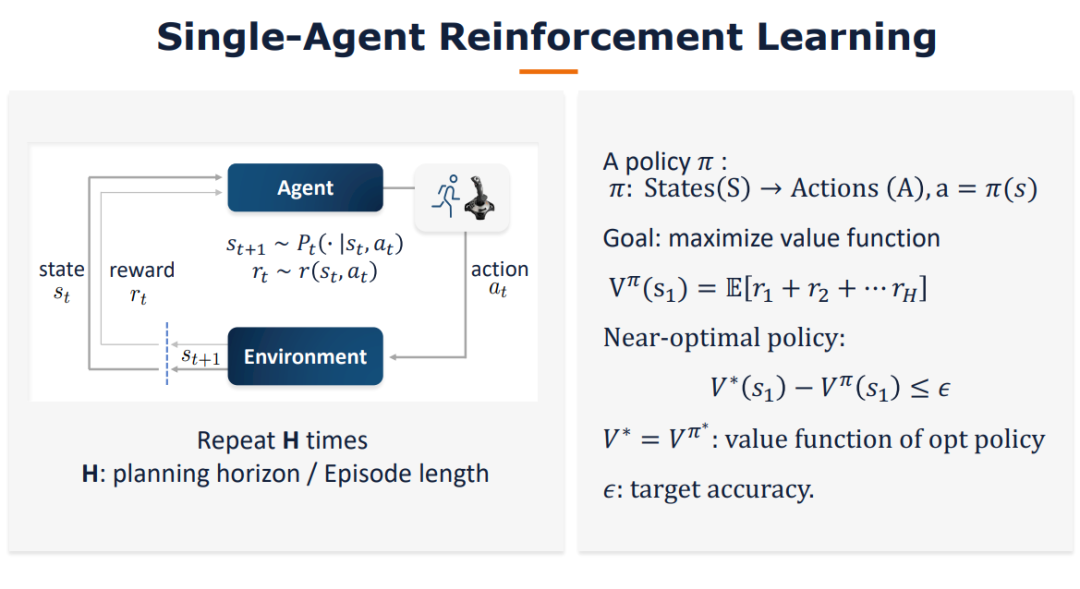
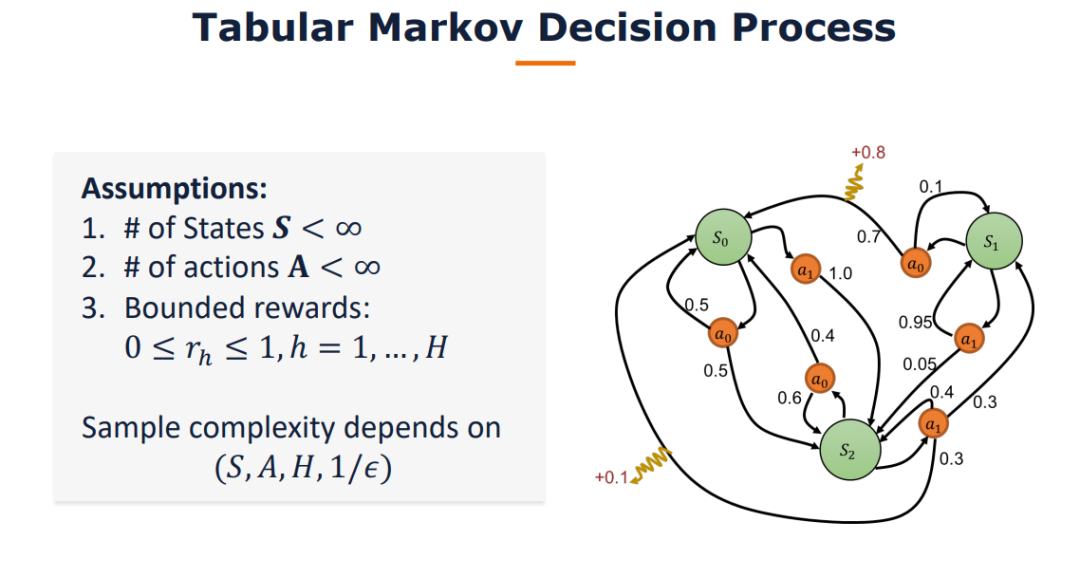
【华盛顿大学Simon S. Du】离线单智能体和多智能体强化学习

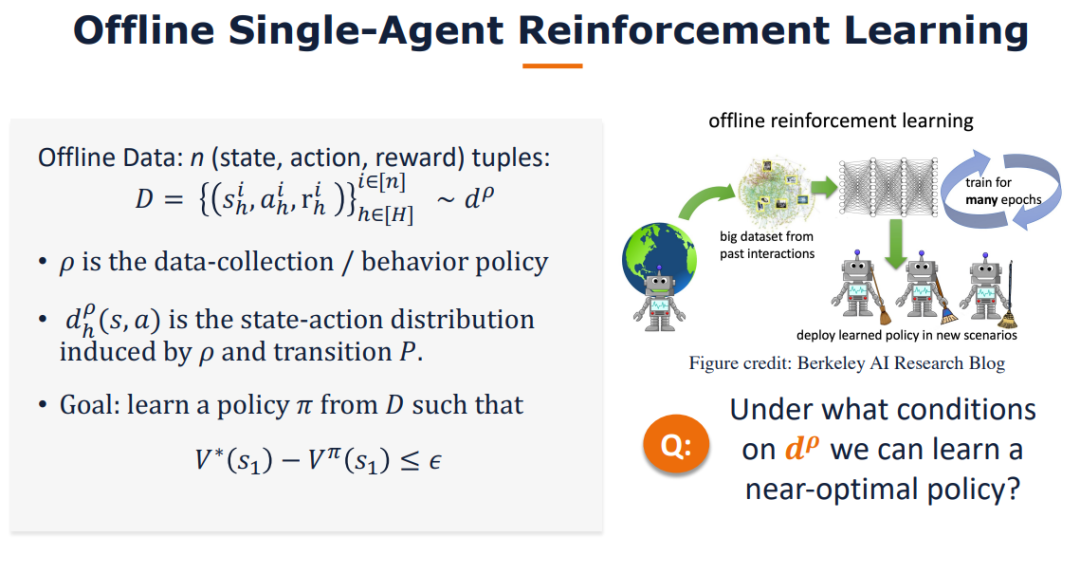
我们研究了怎样的数据集假设可以解决离线的二人零和马尔可夫博弈。与离线单智能体马尔可夫决策过程形成鲜明对比的是,我们证明了在离线二人零和马尔可夫博弈中,单一策略集中假设对于学习纳什均衡(NE)策略是不够的。另一方面,我们提出了一个新的假设——单边集中,并设计了一个在此假设下被证明是有效的悲观型算法。此外,我们还证明单边集中假设对于学习NE策略是必要的。此外,我们的算法可以在不做任何修改的情况下,在具有均匀浓度假设的数据集和基于回合的马尔可夫博弈两种广泛研究的设置下,获得极大极小样本复杂度。我们的工作为理解离线多主体强化学习迈出了重要的第一步。
https://simonsfoundation.s3.amazonaws.com/share/mps/symposia/2022/NDiTML/NDiTML2022-%20Du.pdf
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SORL” 就可以获取《【华盛顿大学Simon S. Du】离线单智能体和多智能体强化学习》专知下载链接



登录查看更多
相关内容

Arxiv
0+阅读 · 2023年1月13日
Arxiv
21+阅读 · 2021年5月25日
Arxiv
23+阅读 · 2019年12月12日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年1月13日
Arxiv
21+阅读 · 2021年5月25日
Arxiv
23+阅读 · 2019年12月12日