

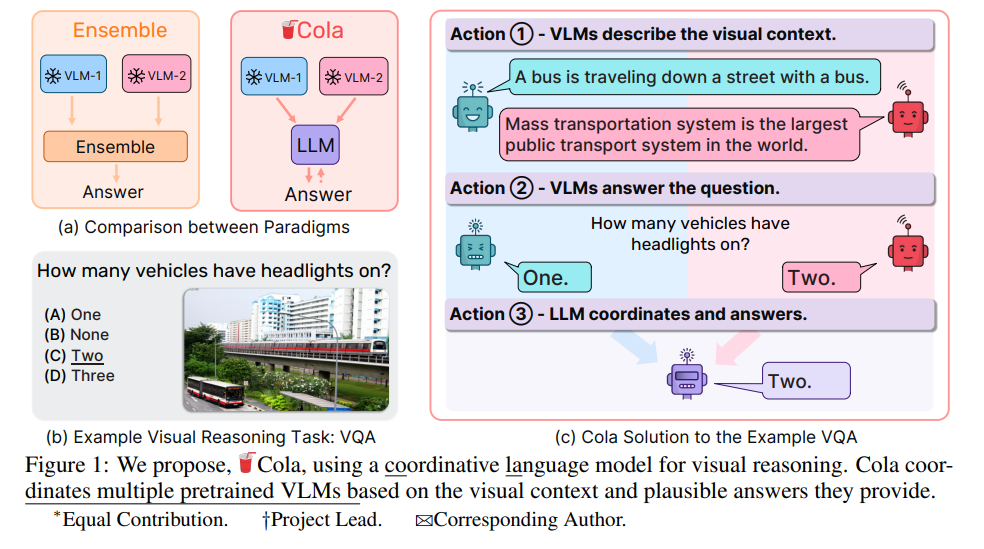
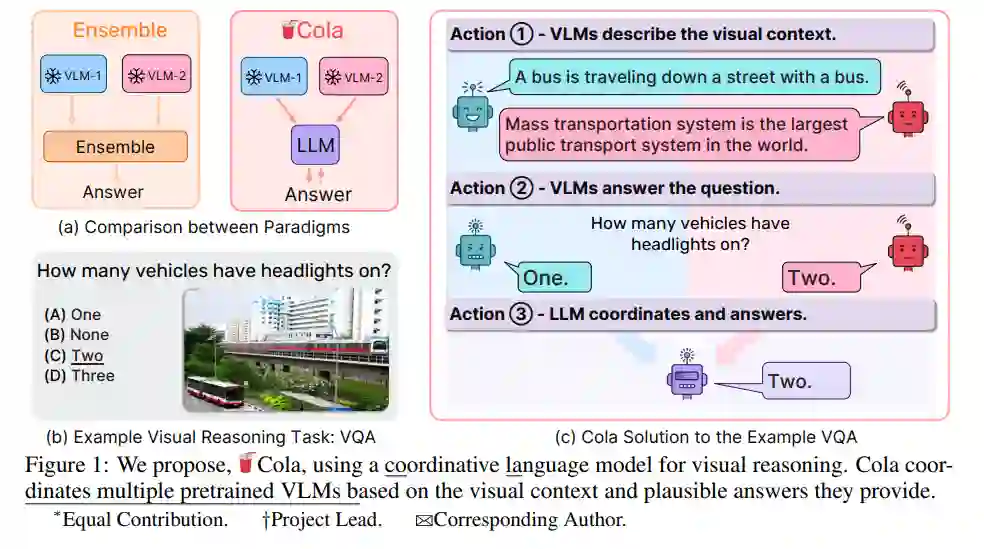
视觉推理需要多模态感知和对世界的常识认知。近期,有多个视觉-语言模型(VLMs)提出,它们在各个领域都表现出出色的常识推理能力。但如何利用这些互补的VLMs的集体能力却鲜有探讨。现有的方法,如集成,仍难以以期望的高阶通信来聚合这些模型。在这项工作中,我们提出了一种新的范例Cola,用于协调多个VLMs进行视觉推理。我们的关键见解是,大型语言模型(LLM)可以通过促进自然语言通信来有效地协调多个VLMs,利用它们的独特和互补能力。大量实验表明,我们的指令调整变体,Cola-FT,在视觉问题回答(VQA),外部知识VQA,视觉蕴涵和视觉空间推理任务上都达到了业界领先的性能。此外,我们证明,我们的上下文学习变种,Cola-Zero,在零和少样本设置中表现出竞争性的性能,无需微调。通过系统的消融研究和可视化,我们验证了协调器LLM确实理解了指令提示以及VLMs的单独功能;然后协调它们,实现了令人印象深刻的视觉推理能力。
成为VIP会员查看完整内容

相关内容
Arxiv
224+阅读 · 2023年4月7日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日