

无人车(UGV)可替代人类自主地执行民用和军事任务,对未来智能 交通及陆军装备发展有重要战略意义。随着人工智能技术的日益成熟, 采用强化学习技术成为了无人车智能决策领域最受关注的发展趋势之 一。本文首先简要概述了强化学习的发展历程、基础原理和核心算法;随后,分析总结了强化学习在无人车智能决策中的研究进展,包括障碍 物规避、变道与超车、车道保持和道路交叉口通行四种典型场景;最后, 针对基于强化学习的智能决策面临的问题和挑战,探讨并展望了未来的 研究工作与潜在的研究方向。
1. 引言
无人车是指不具有人类驾驶机构并可以自主执 行运输、公交、物流、清扫、巡逻、救援、作战、侦 察等民用或军用任务的智能车辆。在民用领域,无 人车已成为未来智能交通与智慧城市建设的核心要素。在军用领域,无人车也已成为各军事大国竞相 角逐的新一代陆军装备。无人车的核心技术主要有 环境感知、智能决策、路径规划、动力学控制、集 群调度等相关技术。其中,智能决策是无人车的关 键核心技术之一,其性能是衡量无人车智能化水平 的重要标准。智能决策系统根据任务调度信息、环 境感知信息和无人车状态信息等,做出合理、安全 的驾驶决策,并输出车辆控制指令,以控制车辆完 成指定任务。 无人车智能决策系统的算法主要包含规则驱 动[1-2] 和数据驱动两类算法[3-4] 。由规则驱动的决 策系统基于既定规则构建,其根据人类驾驶经验及 交通规则等建立相应的驾驶行为决策库,结合感知 系统得到的环境信息进行车辆状态的划分,依据预 设的规则逻辑确认车辆行为[5] 。这类基于规则的 决策系统无法枚举和覆盖所有交通场景,且在交通 复杂、不确定性强的路况中,常因规则数目冗杂和 行为决策库触发条件的重叠而导致决策无法求解、 决策系统的自适应性和鲁棒性不足等问题。基于强 化学习的决策方法是数据驱动的无人车决策系统的 代表,该方法将无人车决策过程视为黑箱,利用机 器学习建立由传感器到转向系统、驱动系统、制动 系统等执行机构的映射,实现基于高维度感知数据 对执行机构的直接控制。这类决策算法把整个自动 驾驶过程与神经网络深度融合,通过由数据驱动的 仿真训练使神经网络学习在不同交通场景下的智能 决策能力。
强化学习技术是人工智能领域的研究热点,适 用于 解 决 复 杂 的 序 贯 决 策 问 题,在 机 器 人 控 制[6-7] 、调度优化[8-9] 、多智能体协同[10-11] 等领域 中,取得了令人瞩目的成果。强化学习的基本思路 是智能体依靠探索试错以及环境交互的方式,结合 反馈信号学习最优策略。近些年,随着强化学习的 广泛研究和应用,特别是综合了深度学习的特征提 取能力和强化学习的策略优化能力的深度强化学习 (deepreinforcementlearning,DRL)取得突破性进展 之后,采用强化学习技术解决无人车智能决策问题 成为无人车领域最受关注的研究方向之一。
本文旨在综述强化学习在无人车领域的应用。首先介绍了强化学习的发展历史、基础原理和核心 算法;然后分析总结了强化学习在无人车智能决策 问题中的研究现状,包括避障、变道与超车、车道 保持及道路交叉口通行四个典型的决策场景;最后 探讨并展望了未来的研究工作和潜在的研究方向。
1 强化学习的基本理论
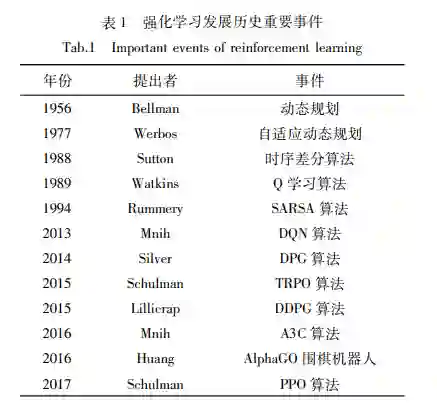
强化学习是动物心理学、最优控制理论和时序 差分学习等学科交叉的产物[12] 。强化学习的“试 错”思想源于动物心理学家对试错行为的研究,最 早可追溯到 Pavlov的条件反射实验。1911年美国 心理学家 Thorndike提出效应定律,第一次明确地 阐述了试错行为的本质是学习。最优控制理论,是 现代控制体系的关键分支之一。在 20世纪 50年代 初,美国数学家 Bellman等提出求解最优控制的动 态规划法(dynamicprogramming,DP),该方法衍生 出了强化学习试错迭代求解的机制。时序差分学习 (temporaldifferencelearning,TDL)是 DP和蒙特卡 洛方法结合的产物。1959年 Samuel首次提出并实 现一个包含时序差分思想的学习算法。1989年 Watkins在他的博士论文将最优控制和 TDL整合, 并提出 Q学习算法,这项工作正式标志着强化学习 的诞生,该算法通过优化累积未来奖励信号学习最 优策略。随后,Watkins和 Dayan共同证明 Q学习 算法的收敛性。表 1总结了强化学习发展历程中的 若干重要事件。
2 强化学习在自动驾驶领域的应用
2.1 在避障问题中的应用
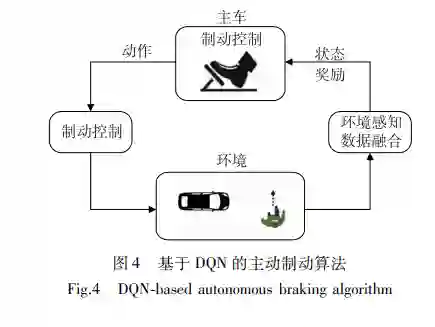
在避障问题中无人车根据自车和障碍物的位置 和状态信息,在满足乘坐舒适性和行驶安全性的条 件下,输出转向、制动和油门指令控制车辆规避障 碍物。 Arvind等[22-23]提出基于 MLPSARSA和基于 MLPQ学习的避障算法。设计了以车载的 7个超 声波雷达的感知数据为输入量,输出离散的制动、 转向和加速动作的端对端决策模型,将多层感知机 (multilayerperceptron,MLP)引入到对 Q函数的预 测中,以提高避障策略的收敛速度。车辆在包含多 个动态障碍物的仿真环境下实现自主避障,且无碰 撞通行的成功率达 96%。 Chae等[24] 提出复杂城市场景下基于 DQN的主 动制动算法,如图 4所示。使用 6层的深度神经网 络架构,采用障碍物相对于主车的横向和纵向的位 置和速度作为 DQN网络输入,输出无制动、弱制 动、中制动和强制动四个不同强度等级的制动动 作。在奖励函数的设计中,考虑车辆的乘坐舒适性 和安全性,对过早的制动行为和与障碍物发生碰撞 进行惩罚。经过 2000次的迭代训练,无人车能有 效地处理行人横穿马路等随机突发事件,但面对碰 撞时间(timetocollision,TTC)等于 1.4s的紧急工 况仅有 74%的避障成功率。
虽然上述基于值函数的避障算法通过将动作离 散化取得较好的避障效果,但在执行动作的精度和 紧急情况下的避障成功率上仍然有待提高。部分学 者考虑将用于高维连续空间的基于策略的强化学习 方法应用于避障问题中。 Zong等[25-26] 设计基于 DDPG的避障算法,策 略网络以车载的多类型传感器融合感知数据作为状 态输入,输出动作空间连续的转向、油门、制动动 作。相比于文[24],该算法解决了连续动作空间下 避障决策所引发的维数灾难,实现动作空间连续的 车辆动作输出,提高了决策模型输出动作的精度。 Porav等[27] 在研究中运用变分自编码器(varia tionalautoencoder,VAE)对障碍物特征降维,将高 维语义图像映射到低维且保留原始语义信息的隐变 量,将低维的隐变量及其预测状态作为 DDPG网络 输入,有效剔除了环境无关因素对决策的影响,并 提高了决策模型训练收敛速度。此外,作者建立基 于 DeltaV模型的奖励函数,利用碰撞前后车辆速 度差值衡量车辆碰撞的严重程度,以量化危险驾驶 行为的惩罚。相比于文[24],该算法在 TTC为 1s 和 0.75s的极端紧急情况,仍能保持 100%和 95% 的避障成功率。
Fu等[28] 详细分析了车辆在紧急情况下的制动 过程和乘坐舒适性变化,提出包含多目标奖励函数 的 DDPG算法,可综合衡量制动触发时刻、事故严 重程度和乘坐舒适度等指标。在仿真试验中,所提 出算法在紧急情况下避障成功率相较于基于 DDPG 和 DQN的避障算法分别提高 4%和 12%。 余伶俐等[29] 针对无人车在避障过程中对周围 车辆驾驶意图预判不足的问题,设计了基于蒙特卡 洛预测—深度确定性策略梯度(MCPDDPG)的决策 方法。该方法假设车辆状态的转移满足马尔可夫 性,将周围车辆的位置和速度作为观测方程参数, 利用 MCP预测其他车辆的运动轨迹,有效地提高 决策模型在紧急情况下的响应时间。实车试验证明 该决策方法能够有效预估碰撞风险,降低无人车发 生碰撞的概率。 基于强化学习的方法虽然可通过增加避障场景 库的广度,以尽可能多地覆盖各种复杂避障工况。 但当面临 TTC过小等临近碰撞的极端工况,决策模 型的稳定性和安全性亟待提高。
2.2 在变道与超车问题中的应用
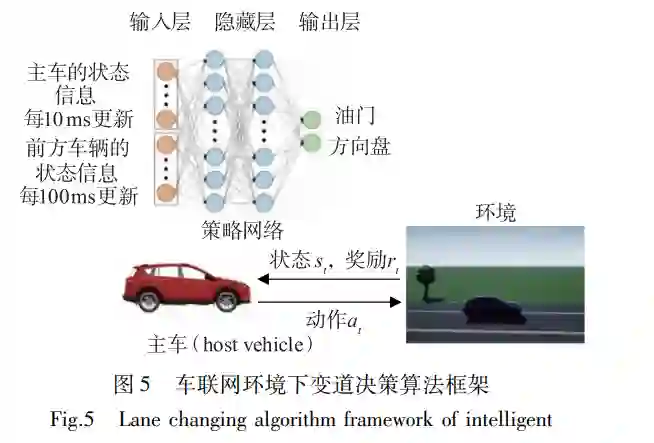
在变道与超车问题中,无人车根据自车和周围 车辆状态、自车的期望速度和交通规则约束等,做出变道及超车决策,指导车辆超越前方低速车辆, 以尽快地通过特定的交通流。 Loiacono等[30] 提出基于 Q学习的超车决策算 法,建立了包含主车和前方车辆相对距离、相对速 度,主车和车道边缘横向距离等在内的离散状态, 并以 有 限 的 离 散 动 作 驱 动 车 辆 完 成 超 车。在 TORCS赛车模拟器中验证了该算法在直线赛道和 弯道上的超车效果,在超车持续时间、超车时最高 车速和超车成功率等指标上明显优于人类驾驶员。 针对求解连续空间下超车决策问题时 Q学习 存在的计算效率低的问题。Liu等[31-32]提出基于 线性函数逼近强化学习的变道决策算法。作者将变 道场景建立为状态、动作空间连续的 MDP模型,将 基于多核的最小二乘策略迭代法(multikernelLSPI, MKLSPI)引入对 Q函数的拟合中,并基于国防科技 大学研制的红旗 HQ3无人车采集的实车感知数据, 对决策算法开展离线测试工作,论证了算法的有效 性和泛化能力。Min等[33]利用非线性值函数逼近 的方法,提出基于 DuelingDQN的超车决策算法, 构建以卷积神经网络(convolutionalneuralnetworks, CNN)和长短期记忆网络(Longshorttermmemory, LSTM)提取的视觉图像和雷达点云的特征作为状态 输入,输出横向的变道操作及纵向的车速变化的决 策模型。该算法改进 DQN网络结构,利用 DNN输 出的状态值函数和动作优势函数近似拟合 Q函数, 提高了策略学习的收敛速度。 An等[34] 提出车联网环境下基于 DDPG的变道 决策算法,网络结构如图 5所示。该算法策略网络 输入包含两部分,分别为由车载传感器获得的主车 状态信息和由 V2X通信获得的前方车辆状态信息, 并通过 2个全连接的隐藏层输出对主车油门和方向 盘的控制。在 Airsim软件中的仿真实验验证该算 法的有效性,但由于输入层网络结构固定,其仅能 处理 2个车辆交互这种简单场景,缺少对更为复杂 交通场景的适应性。
针对文[34]无法处理无人车在复杂的包含多 车交互场景下变道的问题。Wolf等[35]提出一种基 于通用语义状态模型的超车决策算法。该算法将驾 驶场景抽象映射到一个包含交通参与者列表(车 辆、行人、车道等)并叠加场景关系描述(交通参与 者相对于主车的速度、位置、相对车道信息等)的 跨场景、通用的语义状态模型,实时地输入到基于 DQN的决策模型中。在 SUMO仿真环境中,该算 法可处理存在 7辆交互车辆场景下的超车决策问题。Huegle等[36-37]提 出 基 于 DeepSetQ 学 习 和 Set2SetQ学习的超车决策算法。作者分别利用深 度集(deepsets,DS)和图卷积网络(graphconvolu tionalnetwork,GCN)提取无人车感知域内多车的状 态特征,作为 DQN网络输入,解决了基于 DQN的 决策算法因网络结构固定,无法处理数量可变的状 态输入的问题,提高超车决策算法在不同交通密度 场景应用的可移植性。
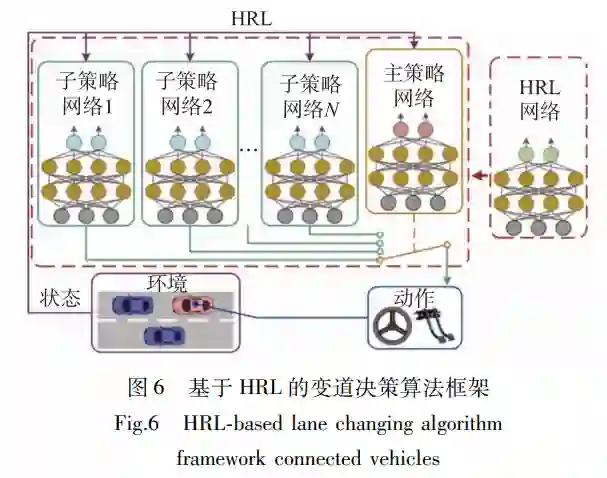
在变道与超车场景中,复杂的环境状态和车辆 动作空间,以及多车间的交互行为,导致训练过程 中策略难以收敛。有学者将分层思想和模仿学习 (imitationlearning,IL)引入到基于强化学习的决策 算法中。 Duan等[38] 提出高速公路场景下基于分层强化 学习(hierarchicalreinforcementlearning,HRL)的变 道决策算法,算法框架如图 6所示。决策网络包括 主策略和子策略两层,分别用于高层行为决策(车 道内驾驶、左/右车道变换)和底层运动控制(方向 盘转角、车辆速度等控制)。HRL将复杂的变道决 策任务分解为若干个简单的子任务,在不发生维数 灾难的情况下实现多任务学习,提高决策算法场景 遍历的广度。此外,受启发于 A3C算法多线程并 行的训练方式,作者利用异步并行训练的网络参数 的平均梯度更新共享网络参数,以加快 HRL训练 速度。 宋晓琳等[39] 提出 IL和强化学习结合的决策算 法,将变道决策划分为宏观决策层和细化决策层。 宏观决策层中,作者基于专家变道决策的示范数据 集构建极端梯度提升(eXtremeGradientBoosting, XGBoost)模型,模仿经验丰富的专家驾驶员做出宏 观决策。细化决策层中,作者构造多个基于 DDPG 算法的子模块,分别处理车道保持、左变道和右变道中具体执行的动作。在 Prescan软件中的仿真训 练,所提出方法策略收敛所需的步数较基于强化学 习的方法降低约 32%。Liang等[40] 提出基于可控模 仿 强 化 学 习 (controllable imitative reinforcement learning,CIRL)的变道决策算法。首先利用引入门 控机制的 IL网络学习专家提供的驾驶示范集,通 过网络权重共享的方式将预训练结果迁移到 DDPG 决策模型中,以初始化 DDPG动作探索策略,解决 了连续动作空间下 DDPG算法探索效率低、对超参 数敏感的问题。
针对变道与超车过程中未知和不确定性因素对 无人车安全性的影响。Zhang等[41] 考虑前车异常驾 驶行为对超车安全性的影响,将模糊推理系统 (fuzzyinferencesystem,FIS)引入到变道决策中。 其主要思想是基于车载激光雷达获得的前方车辆的 位置、速度和航向角,利用 FIS分析前方车辆的驾 驶激进度,进而判断超车风险类型,以指导基于强 化学习的决策算法采取保守或激进的超车策略。 Althoff等[42-43] 考虑周围车辆驾驶意图未知、感知 系统观测不完整、传感器的扰动与噪音等不确定因 素,提出基于安全强化学习的变道决策算法。运 用可达性分析(reachabilityanalysis,RA)[44-46] 预测 周围车辆在满足物理约束和交通规则下,在设定时 间内所有可能的可达集,通过判断无人车和其他车 辆的可达集是否存在交集,来验证变道决策的安 全性。 从上文综述可知,基于强化学习的决策算法在 处理动态多车交互、策略收敛速度、决策安全性方 面有较大的局限性,且难以从强化学习模型本身加 以改进。与安全验证、行为分析及其他机器学习方 法相结合,可显著地提高基于强化学习的变道和超车决策算法的性能。
2.3 在车道保持问题中的应用
在车道保持问题中,无人车根据车载传感器获 得的车道线信息,输出车辆方向盘转角控制指令, 以使车辆在车道中心线附近行驶。 视觉感知是检测车道线的最有效手段。方 川[47] 提出基于 DoubleDQN的车道保持算法,以原 始的 RGB图像作为网络输入,分别利用当前 Q网 络和目标 Q网络处理方向盘控制动作选择和目标 Q 函数预测。在仿真试验中,车辆在直线车道及大曲 率弯道的车道保持任务中均表现出良好的性能。 Kendall等[48]提出视觉感知数据输入下基于 DDPG 的车道保持算法(如图 7),并将在虚拟环境中训练 好的算法网络结构和参数迁移到实车上,车辆仅依 靠单目相机的 RGB图像完成了 250m的车道保持 路测。然而该方法忽略视觉传感器抗干扰能力差、 易受光照影响等缺点,且决策模型场景遍历的深度 不足,难以完成特殊天气条件下的车道保持任务。
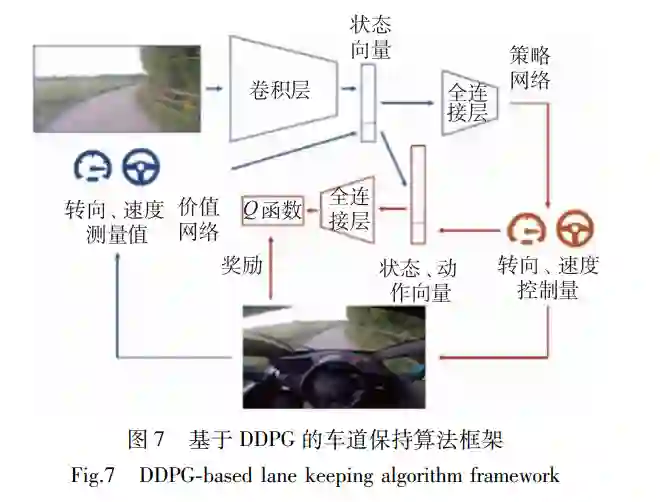
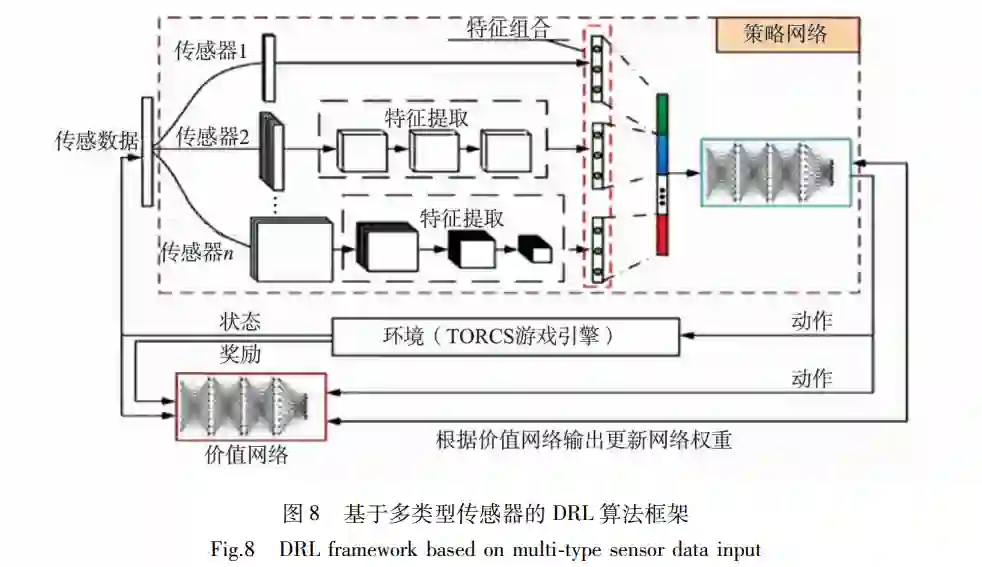
原始视觉图像包含大量与决策无关的环境细 节,而细微的环境变化易导致决策模型错误,进而 引发车辆驶出车道等危险驾驶行为。针对此问题, Wolf[49] 利用机器视觉剔除无关环境信息,提取车道 线的灰度化图像,构建由灰度化的视觉图像到车辆 方向盘的端对端决策,降低细微的环境亮度变化及 无关环境细节对决策模型的影响。并利用经验回放 机制降低训练样本的相关性,以减轻 DQN算法处 理高维图像数据时存在的不稳定性。 视觉感知缺少车辆与道路边缘的距离信息,而 其他具有目标距离测量功能的传感器对提取车道线 信息具有重要的补充作用。杨顺等[50]研究了多源 感知数据输入下基于 DDPG的车道保持算法,如图 8所示。策略网络分别利用一维和二维 CNN提取低 维目标级感知数据和高维视觉图像数据的特征,并 输出每一时间步长内车辆的动作,价值网络根据策 略网络提取的低维特征和输出的车辆动作预测 Q 函数。作者构建包含期望车速、车辆偏离中心距 离、车辆与车道中心线的夹角在内的奖励函数,指导车辆与环境交互。在直线车道和弯道下的仿真实 验中,车辆的横向偏移量和车辆与车道中心线的夹 角均保持在理想的范围内。作者利用不同 CNN对 多类型传感器数据进行特征提取,并通过特征组合 的方式,解决了视觉传感器获取车道线信息不完 备、信息冗余性差的问题。
基于强化学习的车道保持算法具有重大的应用 潜力,但是视觉传感器作为主要的车道线检测手 段,其感知图像包含丰富的环境细节,且图像细节 随光照、天气等环境因素显著变化,给决策模型的 稳定性和泛化能力带来巨大的影响。引入能稳定地 在复杂多变环境下提取车道线特征的方法,并有效 地利用和融合其他类型传感器数据,对提高决策性 能有着重要意义。
2.4 在道路交叉口通行问题中的应用
在道路交叉口通行问题中,无人车根据交叉口 各车道上车辆位置、速度及交通规则等,输出执行 机构控制指令,以控制车辆无碰撞地通过交叉口。 无交通信号灯的交叉口通行是最具挑战性的交 通场景,学者们对基于强化学习的通行决策方法进 行大量研究。Saxena等[51]设计基于近端策略优化 (proximalpolicyoptimization,PPO)的通行决策算 法。作者利用由数据驱动的仿真训练建立交叉口中 无人车周围车辆间交互的隐式模型,并通过设置车 辆的加速度和转向角度阈值,减少不良的加速和转 向动作,提高乘坐舒适性。Qiao等[52]提出课程式 学习(curriculumlearning,CL)和 DRL结合的交叉 口决策算法。作者利用 CL自动生成若干由简单到 复杂的样本,引导 DRL学习驶入并通过城市交叉路口的策略,仿真实验中通过交叉口的成功率达 98.7%。 Müller等[53]提出基于视觉场景理解的决策算 法,引入编码器—解码器网络来提取 RGB视觉图 像更细化的语义特征,实现原始图像到多场景通用 的语义分割图像的映射,将语义图像作为决策模型 输入,输出车辆期望的轨迹。其后,作者将训练好 的决策模型迁移至小型卡车上,车辆可在多个驾驶 场景(晴朗、阴天、雨雪)自主地通过交叉路口。该 方法通过模块化和抽象语义分割的方法降低真实场 景传感器噪声等对决策的影响,提高决策算法的迁 移能力。 无交通信号灯的交叉口中车辆缺少交通规则约 束。无人车无法获悉其他车辆的驾驶意图,因而无 法预判其行驶轨迹,且因车辆间的相互遮挡易造成 无人车的感知盲区,给决策的安全性带来巨大隐 患。Isele等[54-55]利用卡尔曼滤波 (Kalmanfilte ring,KF)预测可能与无人车发生碰撞车辆的行驶 轨迹,并根据预测结果约束 DQN决策算法的动作 空间,提高车辆在交叉口通行的安全裕度。Gruber 等[56] 设计基于 RA的在线安全验证方法,利用 RA 建立其他车辆未来时间在交叉口所有可达集,以验 证决策的安全性。其后,Lauer等[57]提出基于 RA和责任敏感安全模型(responsibilitysensitivesafety, RSS)的验证方法,解决了 RA因考虑最危险情况下 周围车辆的占用空间而导致的无人车在交叉口驾驶 策略过度保守的问题。Stiller等[58] 提出一种风险认 知 DQN的交叉口决策算法,在奖励函数中引入风 险项度量感知盲区内的车辆对决策安全性的程度, 减少无人车采取冒进决策行为的概率。 无交通信号灯的交叉口的复杂程度高,且事故 风险隐患多,给无人车决策的安全性带来巨大挑 战。基于强化学习的决策模型无法有效预估事故风 险,结合行驶轨迹预测、安全性验证等方法对提高 决策安全性具有重要意义。
3 强化学习在无人车领域的应用展望
无人车可自主执行运输、物流、清扫、巡逻、 救援、作战、侦察等民用或军用任务,是未来智能 交通与新一代陆军装备发展的核心要素,对汽车产 业发展与国防安全建设具有重要意义。面向未来无 人车技术发展需求,高效、准确、稳定的智能决策 技术已经成为限制无人车行业水平提升与大规模产 业应用的关键技术瓶颈。强化学习技术是实现无人 车智能决策技术水平提升的最重要突破口之一。但 是,基于强化学习的智能决策存在泛化能力弱、可 解释性差,缺少安全验证等问题,限制了其在实车 上的应用。此外,云控制、车联网及大数据等先进 技术在无人车领域的应用极大程度拓宽了强化学习 技术的应用内涵,带来了全新的挑战与不确定性。 下面指出未来强化学习技术在无人车领域的研究 重点:
1)提高强化学习在无人车决策上的泛化能力当前研究多利用强化学习构建从无人车的传感 器到执行机构的端对端决策。而以复杂高维的图 像、雷达点云等原始感知数据作为决策模型的输 入,使得表征环境状态的特征维度过多,导致决策 模型过拟合于特定的训练环境,难以迁移至新的驾 驶场景。此外,模型训练中常忽略光照变化、背景 干扰等敏感环境细节以及传感器噪音和自身扰动的 影响,使得训练好的决策模型需要人工调参后才能 迁移到实车上。提高强化学习在无人车决策上的泛 化能力,已经成为其在无人车应用亟需解决的关键 问题之一。为突破决策算法在新场景中泛化能力弱 的瓶颈:(1)可借鉴虚拟到现实(Sim2Real)领域的 研究成果,利用领域自适 应 (domainadaptation, DA)等方法将虚拟训练环境映射到真实行驶环境[59] ,以在训练过程中最大限度地模拟无人车与 真实场景的交互过程。(2)从原始感知数据中提取 或抽象出面向通用场景的低维环境状态表征,替代 复杂高维的原始数据作为决策模型的输入[60] ,可 以降低决策模型精度对行驶环境的依赖性。
2)提升强化学习在无人车决策上的可解释性
当前研究多利用基于复杂深度神经网络的深度 强化学习学习驾驶策略。而训练好的决策模型因其 复杂的网略结构及庞大的网略参数,导致人们难以 理解模型内部的决策过程。在决策模型出现偏差和 故障时,难以对错误源头进行排查和分析。提高强 化学习在无人车决策上的可解释性,已成为提高其 决策合理性与安全性的关键挑战之一。为解决决策 算法的内部运行机制可解释性差的弱点:(1)利用 概率图模型(probabilisticgraphicalmodel,PGM)深 度综合表征无人车行驶环境、行驶轨迹、交通参与 者等的时序特征,并将高度可解释化的隐含状态作 为模型输入[61-63] ,可显著地提高模型的可解释性。 (2)利用神经网络可视化技术以热力图的形式表征 决策模型内部每一层的权重参数、特征图等,以实 现模型决策过程的透明化[64] 。(3)也可借鉴机器人 领域的最新进展,根据人类经验将复杂的作业任务 分解为若干子任务,决策模型输出子任务的序贯组 合,以组合的顺序表征无人车决策的合理性[65] ,也 是值得深入探讨的话题。
3)提高强化学习在无人车决策上的安全性
当前研究多围绕感知完备等理想工况下的决策 任务,且对车辆行驶中的不确定性因素考虑不足。 而强化学习通过探索试错的机制学习驾驶策略,其 随机性的探索策略常导致不安全的驾驶行为,给决 策模型带来潜在的安全风险。此外,无人车行驶环 境具有高度的不确定性,具体表现为周围车辆行驶 意图和驾驶风格的不确定性,因遮挡和感知盲区造 成的感知不完整性等,给决策模型的安全性带来巨 大挑战。提高强化学习在无人车决策上的安全性, 已经成为其在无人车应用亟需解决的重要技术瓶颈 之一。为提高决策算法在复杂动态场景下决策的安 全性:(1)可通过在奖励函数中引入风险项[66] ,在 动作探索策略中引入安全约束[67] ,在动作执行中 引入安全验证[68]等方法,降低决策模型做出激进 和危险决策的概率。(2)利用部分可观测 MDP (partiallyobservableMDP,POMDP)将环境的不确 定性因素作为隐变量[69] ,实现环境不完全观测下 周围车辆的轨迹预测,可有效地提高车辆感知能力受限下决策的安全性。(3)利用基于严格数学定义 的形式验证精确求解当前状态下无人车在预定时间 内不安全状态的可达范围[70] ,验证其决策行为的 安全性,以保证系统安全验证的完备性。
4)研究无人车大数据背景下基于强化学习的
云端决策技术 基于云控制、车联网、大数据等先进技术的云 控系统(cloudcontrolsystem,CCS)[71]在无人车领 域的应用为无人车产业化落地提供重要的技术支 撑,CCS扩大了无人车的感知域,并提供强大的算 力支持,实现无人车综合性能的显著提升。此外, CCS可实时地获取并存储各无人车的硬件和软件系 统海量的运行数据,并基于大数据分析建立云端的 无人车性能预测模型、故障预警模型、交通流量预 测模型、车辆集群调度模型等[72-73] ,以提高无人 车群体的安全性和效率。CCS在无人车中的应用是 未来无人车发展的重要趋势[74] ,并极大地丰富了 强化学习在无人车领域的应用场景。研究无人车大 数据背景下,云端决策系统利用强化学习技术,结 合多源的时空感知数据和云端的交通流量、车辆性 能等大数据预测结果,实现面向群体及单车层级的 决策,将是非常有意义的工作。
4 结论
本文综述了强化学习技术在无人车领域的研究 现状,重点介绍了基于强化学习技术的无人车智能 决策在避障、变道与超车、车道保持等典型场景下 的应用。其次,展望了强化学习技术在无人车领域 的应用前景。笔者看来,强化学习技术将极大程度 地提高无人车的智能决策能力,是实现无人车规模 化产业应用并服务于智能交通系统建设和新一代陆 军装备发展的重要支撑。

