大型语言模型(LLMs)已广泛应用于聊天机器人、代码生成器和搜索引擎等领域。链式思维(chain-of-thought)、复杂推理、智能体服务(agent services)等工作负载往往需要多次调用模型,从而显著增加了推理成本。为降低成本,业界采用了并行化、模型压缩和缓存等优化方法,但由于服务需求多样,难以统一选用最合适的优化策略。近年来,专门面向LLM的推理引擎逐渐成为集成这些优化方法并支撑面向服务架构的关键组件。然而,目前仍缺乏对推理引擎的系统性研究。 本文对25个开源及商用推理引擎进行了全面评估。我们从易用性、部署便利性、通用性支持、可扩展性,以及面向吞吐量与延迟感知计算的适用性等多个维度对各推理引擎进行了深入分析。此外,我们通过调查各引擎所采用的优化技术,探讨其设计目标。对于开源引擎,我们评估了其生态系统的成熟度;对于商用方案,则分析了其性能表现及成本策略。 本文还指出了未来的研究方向,包括对复杂LLM服务的支持、对多样化硬件的兼容性,以及增强的安全性等,以期为研究人员和开发者在选择与设计优化的LLM推理引擎时提供实用指导。我们还提供了一个公共代码库,以持续追踪该快速演进领域的最新进展:https://github.com/sihyeong/Awesome-LLM-Inference-Engine。
1 引言
大型语言模型(LLMs)正被广泛应用于聊天机器人、代码生成和搜索引擎等多种服务场景中,典型代表包括 OpenAI 的 ChatGPT [5]、GitHub Copilot [84] 和 Google Gemini [86]。随着这些成功案例的推动,众多新模型与服务迅速涌现;然而,这种扩张也带来了在大规模部署与服务 LLM 时的诸多挑战。 近年来,基于推理的测试时扩展(reasoning-centric test-time scaling)[124, 226] 与基于 LLM 的 AI 智能体 [92, 134] 成为趋势,显著提高了 LLM 应用的计算需求与推理调用次数。推理扩展方法通过多步推理或迭代式自我验证,替代一次性生成答案的方式,以提升输出质量。这类方法也被称为链式思维(Chain-of-Thought, CoT)[259]、自洽性(self-consistency)[45] 和测试时推理(test-time reasoning)[98],通过对单个查询多次调用模型以提升准确性,同时也带来了延迟与计算成本的增加。 与此同时,像 AutoGPT [26] 和 LangChain [126] 这样的基于 LLM 的 AI 智能体可自主规划一系列任务以满足单一用户请求,在单个会话中频繁调用模型。这些趋势使得推理效率成为部署以推理为导向的 LLM 和 AI 智能体服务的关键因素。
为控制 LLM 推理成本,研究者提出了诸多优化技术,如量化(quantization)[61]、轻量化模型架构 [268]、知识蒸馏(knowledge distillation, KD)[271] 等。但在大规模服务中,由于提示长度、查询类型及输出格式的多样性,单一优化策略往往难以覆盖所有场景。因此,LLM 推理引擎作为集成多种优化策略并负责推理流程的基础设施组件,成为影响服务质量与成本的核心要素。
尽管像 PyTorch [201] 和 TensorFlow [1] 等通用深度学习框架在 LLM 推理中被广泛使用,这些框架最初是为支持卷积神经网络(CNN)、循环神经网络(RNN)等多种模型设计的,强调的是对不同硬件和架构的广泛兼容性。因此,它们往往缺乏针对 LLM 或序列解码的专用优化。在这些框架上运行大规模模型可能导致性能下降与资源消耗增加,进一步凸显了专用推理方案的必要性。
为了应对这一需求,越来越多的专用 LLM 推理引擎应运而生。这些引擎支持批处理(batching)、流式传输(streaming)和注意力机制优化(attention optimization)等功能,通常不在通用框架中提供。然而,不同引擎的目标硬件(如 GPU 或 LLM 专用加速器)、优化范围(从模型压缩到内存卸载)、目标场景(从实时对话系统到大规模文本生成)各不相同,导致整个生态系统快速演化但高度碎片化。因而难以明确每个引擎所支持的优化技术及其在不同应用条件下的性能表现。这一现状促使人们迫切需要对现有 LLM 推理引擎及其优化能力进行系统性综述与对比分析。
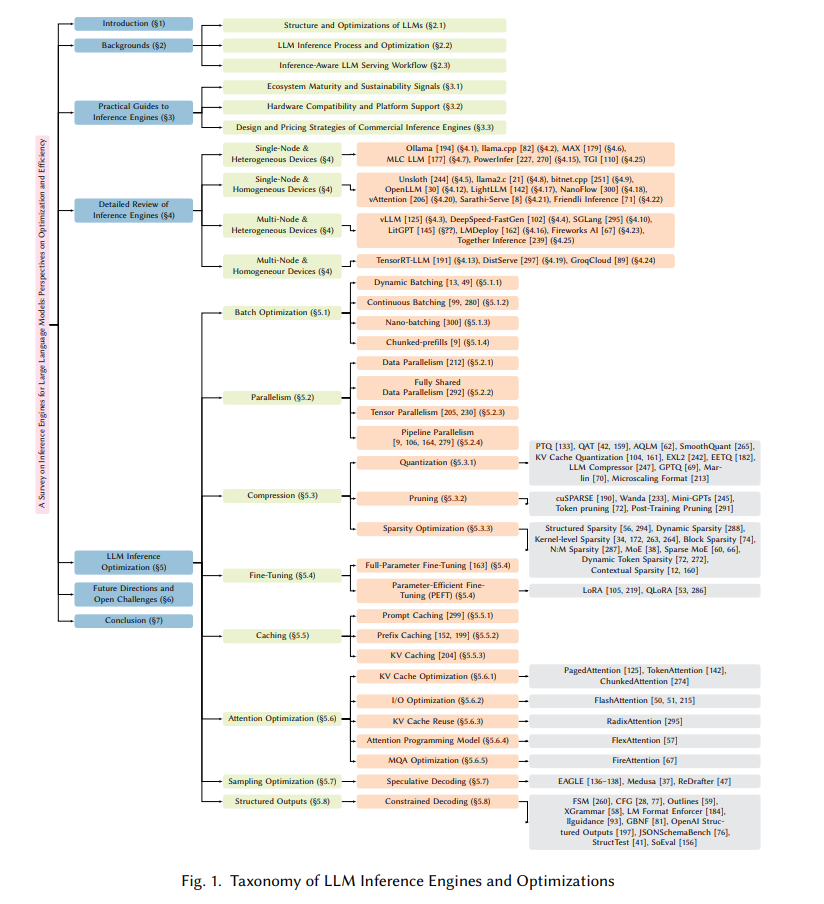
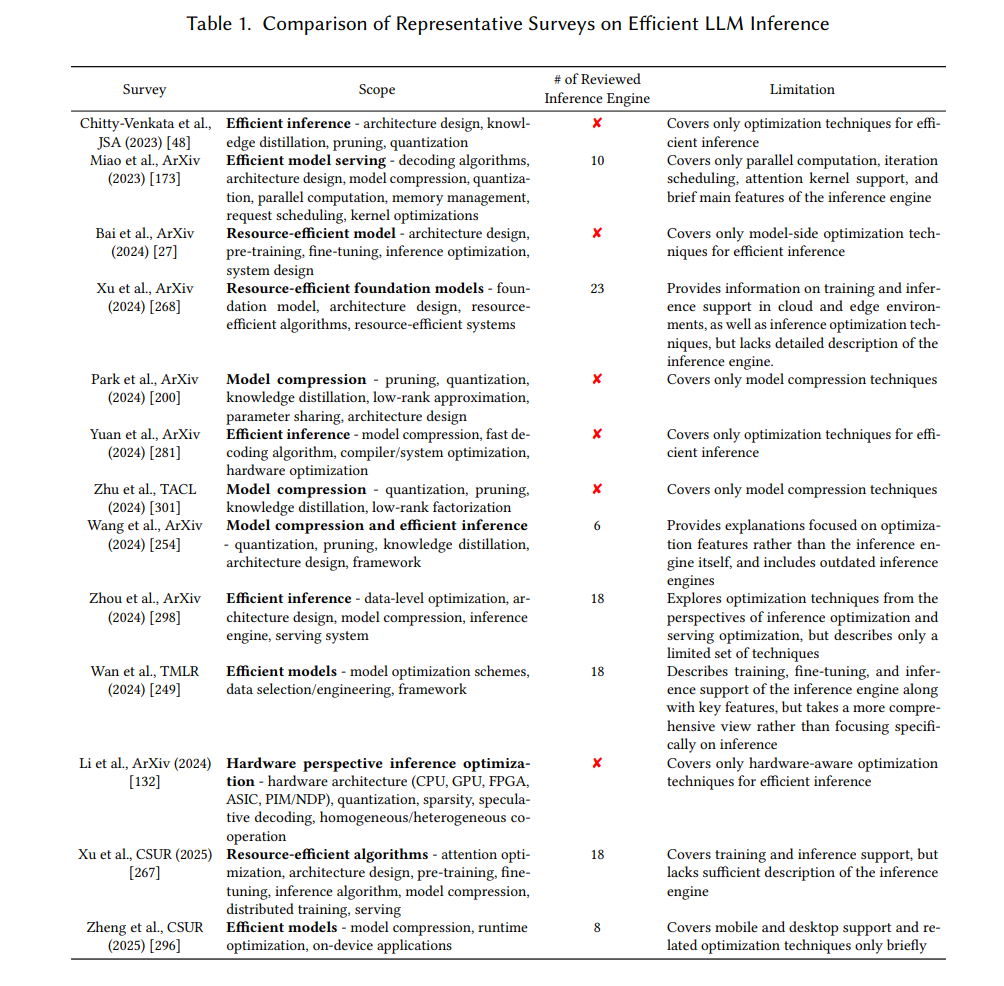
目前已有的一些关于 LLM 优化的综述(见表 1)多聚焦于具体技术,如模型压缩或硬件加速,因此未能全面探讨各个推理引擎所支持的优化方法。此外,这些研究也往往未涵盖近期发布的商用推理引擎。例如,Chitty-Venkata 等人 [48] 与 Yuan 等人 [281] 主要关注基于 Transformer 的模型压缩;而 Park 等人 [200] 和 Zhu 等人 [301] 则对压缩方法进行了深入研究。类似地,Xu 等人 [268, 267] 以及 Wang 等人 [254] 探讨了 LLM 推理与服务的优化策略。
现有的一些研究尽管探讨了云端或边缘环境中的推理系统,但普遍缺乏对各类引擎在设计与实现层面的深入分析。因此,当前文献中仍存在空白,尚无一篇综述能够系统性地呈现 LLM 推理引擎的整体发展现状,并将其特有功能与所实现的优化技术有效对应起来。
为填补这一空白,本文从“以框架为中心”(framework-centric)的视角出发,对多个 LLM 推理引擎进行深入剖析,并对其实现的优化技术进行分类整理。特别地,本文系统梳理了各引擎在处理量化(quantization)、知识蒸馏(KD)、缓存(caching)与并行化(parallelization)等方法方面的实现方式,从而帮助读者快速识别与其特定需求相匹配的引擎。
此外,本文还纳入了许多近期发布的商用推理引擎,这些内容在以往的综述中尚未被覆盖。我们比较了这些引擎的架构设计目标、支持的硬件平台以及关键特性,旨在为构建或部署高性能、低成本的 LLM 服务的研究人员与工程师提供切实可行的参考依据。