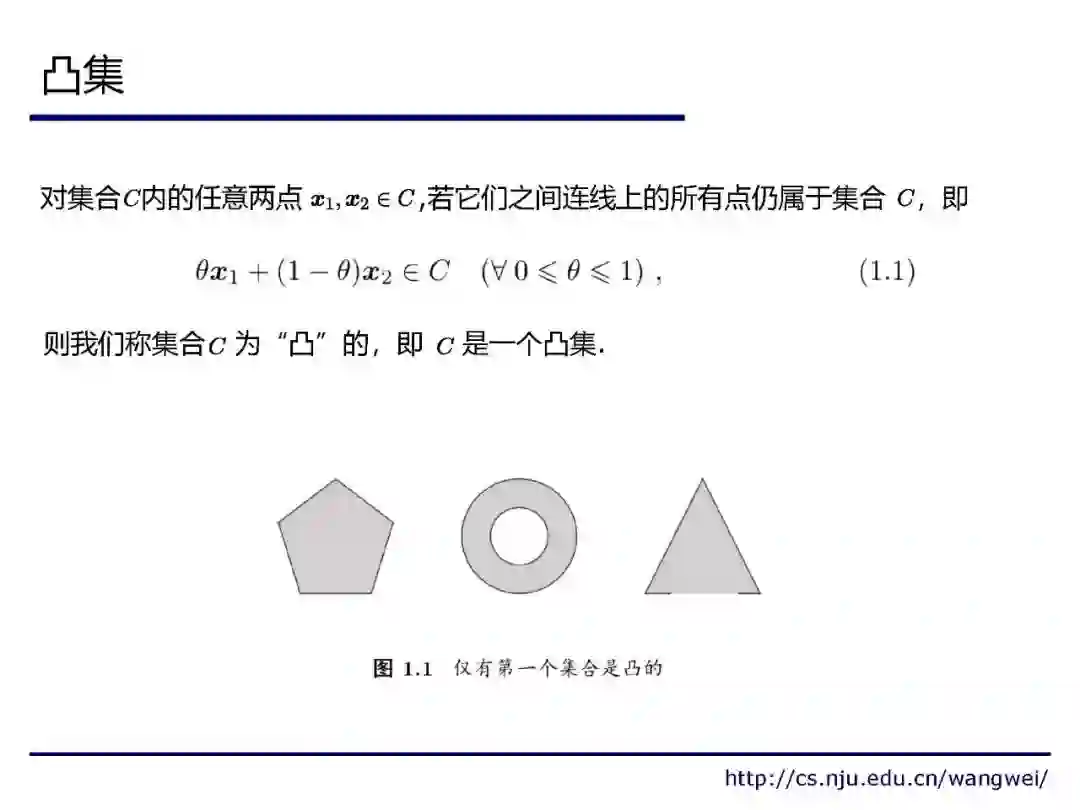
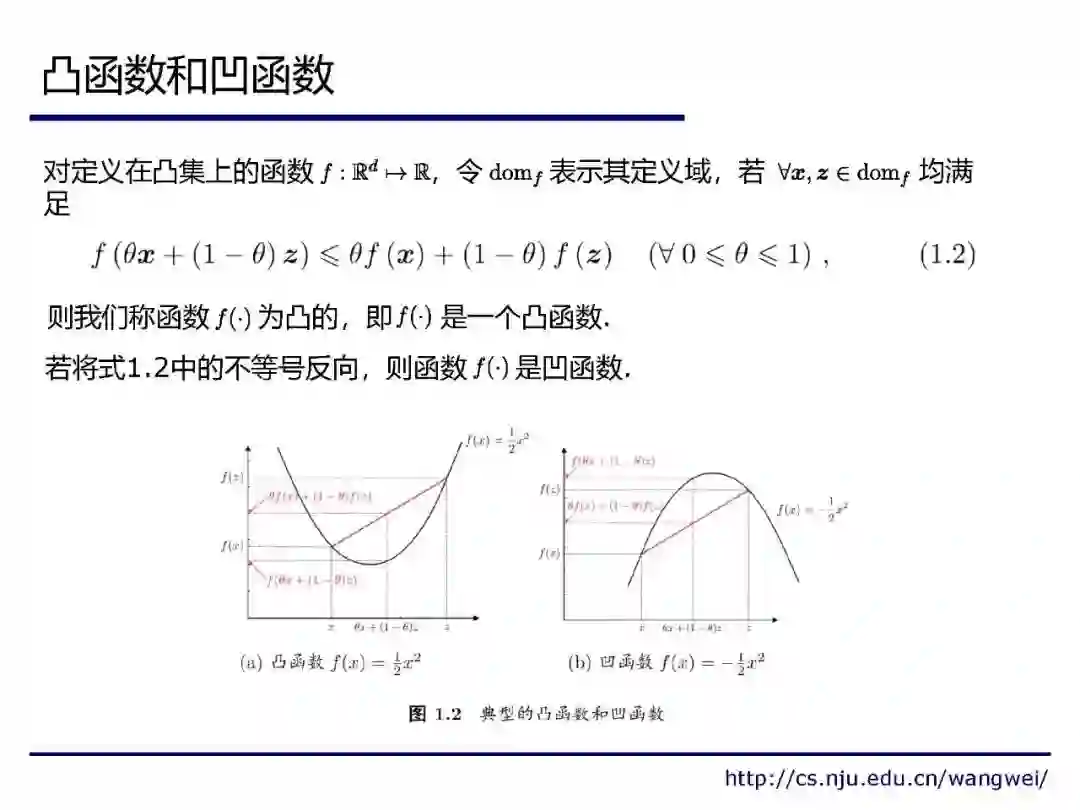
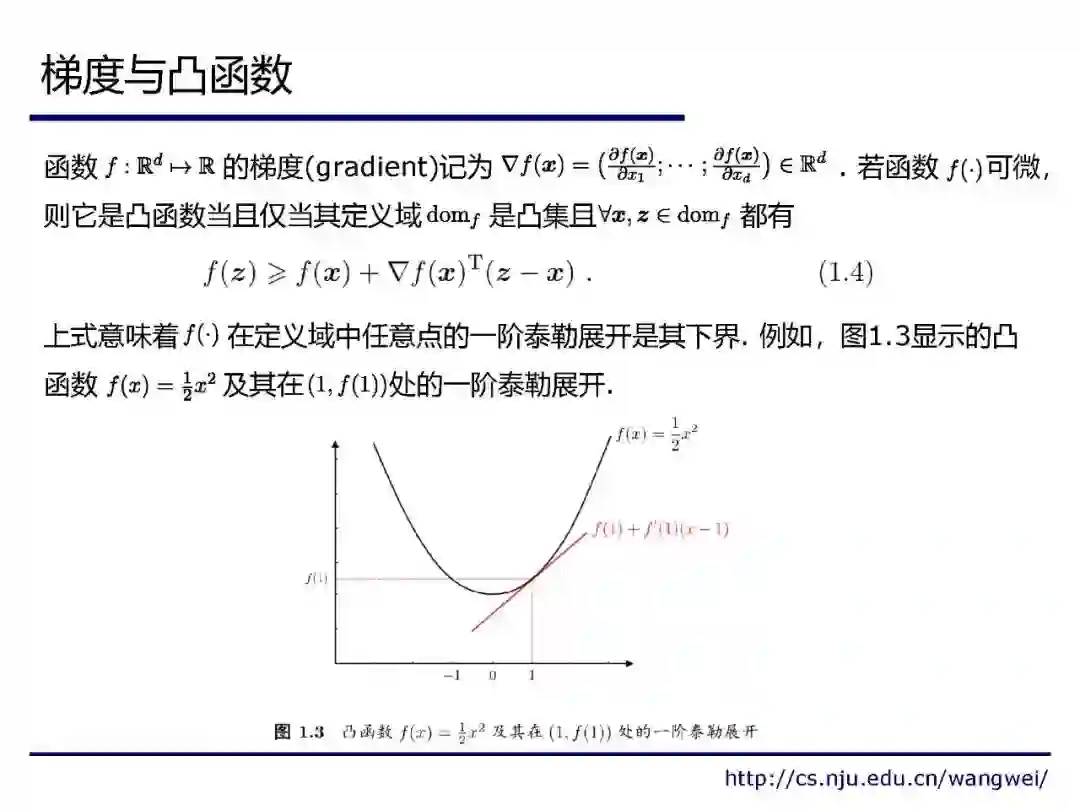
来自南京大学《机器学习理论研究导引》课程,不可错过!
可学习性
机器学习理论研究的是关于机器学习的理论基础, 主要内容是分析学 习任务的困难本质, 为学习算法提供理论保证, 并根据分析结果指导 算法设计. 对一个任务, 通常我们先要考虑它是不是“可学习的(learnable)” 本章就是介绍关于可学习性的基本知识: PAC(概率近似正确), 可学习性, 不可知PAC可学习性, 概念类, 假设 空间.
复杂性
由PAC学习理论可以看出,PAC可学习性与假设空间 的复杂程度密切相关。 假设空间 越复杂,从中寻找到目标概念的难度越大。 对于有限的假设空间,可以用其中包含假设的数目 来刻画假设空间的复 杂度。在可分情形下,可以通过层层筛选的方式从有限的假设空间中寻找到目标 概念。 然而,对于大多数学习问题来说,算法 考虑的假设空间并非是有限的,直 接使用 来刻画假设空间的复杂度不再有意义。 为此,本章将介绍刻画无限假设空间复杂度的方法,包括与数据分布 无关 的 VC 维及其扩展 Natarajan 维,以及与数据分布相关的 Rademacher 复杂 度。 前者计算简单,适用于许多学习问题,但其未考虑具体学习问题的数据特点, 对假设空间复杂度的刻画较为粗糙;后者考虑了具体学习问题的数据特点,对假 设空间复杂度的刻画较为准确,但计算复杂度较高,有时甚至是 NP-难问题。
泛化性
对于学习算法来说, 判断其性能好坏的依据是泛化误差, 即学习 算法基于训练数据学习得到的模型在未见数据上的预测能力. 由第2章介绍的PAC学习理论可知, 泛化误差的大小会依赖于学 习算法所考虑的假设空间及训练集的大小, 这使得评估学得模型 的泛化误差较为困难. 一般来说, 泛化误差与学习算法 所考虑的假设空间 、 训练 集大小 以及数据分布 有关. 到底是如何相关的呢? 本章就来讨论这一重要问题. 下面将按照 泛化误差上界和下界分别展开讨论.
稳定性
第4章介绍的泛化误差界主要基于不同的假设空间复杂度, 如增长函数, VC维和 Rademacher复杂度等, 与具体的学习算法无关. 为此, 本章介绍一种新的分析工具: 算法的稳定性(stability). 直观而言, 稳定性 刻画了训练集的扰动对算法结果的影响. 这些泛化误差界有效保证了有限VC维学习方法的泛化性, 但不能应用于无限VC 维的学习方法, 例如, 最近邻方法的每个训练集可看作一个分类函数, 因此其 VC维是无限的[Devroye and Wagner, 1979a], 然而最近邻方法在现实应用中表现 出良好的泛化性.
一致性
一致性 (consistency) 关注的是随着训练数据的增多,甚至趋于无穷 的极限过程中,学习算法通过训练数据学习得到的分类器是否趋于贝叶 斯最优分类器,这里的贝叶斯最优分类器指在未见数据分布上所能取得 性能最好的分类器 [周志华,2016]。