计算机视觉方向简介 | 基于自然语言的跨模态行人re-id的SOTA方法(上)
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
本文将介绍一种特殊的行人re-id任务,也就是利用自然语言文本信息来检索大规模数据集中的行人图片,这其实是跨模态检索的一个更加细粒度的应用领域。
通常来说,多模态学习包含模态间的映射,模态间对齐,多模态信息融合等子问题,例如,我们常见的看图说话(Image Captioning)属于模态间的映射问题,视觉问答(Visual Question Answering)就包含多模态信息融合问题,而本文的任务属于模态间对齐的问题。
由于在某些场景下,我们无法获取可靠的待搜索对象的视觉信息。譬如在安防领域,在得不到犯罪分子照片的情况下,我们只能根据目击证人通过自然语言描述犯罪分子的外貌特征去在数据集中搜索对应的人。
又或者在搜索引擎中搜索图片时,通常会遇到在不知道待搜索对象的确切信息的情况,所以我们只能使用模糊的语言描述来作为搜索信息。
这就需要我们的算法和模型在训练中能对自然语言和视觉这两种信息进行恰当地处理,以求在只有自然语言作为检索信息的情况下,模型能够搜索到对应的行人图片。
相比直接用图片或视频作为搜索信息的传统行人re-id问题,基于自然语言的跨模态行人re-id这项任务更加具有挑战性,需要研究者同时对CV和NLP问题有着更深的理解。本文将以解读论文的方式和读者一同学习该领域的主流方法。
数据集
CUHK_PEDES
这项任务在CVPR 2017年大会中由商汤科技首次提出(Person Search with Natural Language Description),并构建了一个数据集CUHK_PEDES,目前学术界能获取到的跨模态行人re-id数据集也只有这个。
其中训练集包含34054张图片, 11,003个id和68,126条文本描述,验证集包含3,078张图片, 1,000个id和6,158条文本描述. 以及测试集包含3,074张图片, 1,000个id和6,156条文本描述。平均每张图片大概对应2条文本描述,每条文本描述平均大约23个单词,整个数据集共大约9,408个不同的单词。

主流方法
GNA-RNN(CVPR 2017)
论文:Person Search with Natural Language Description
代码:github.com/ShuangLI59/P
该方法就出自CUHK_PEDES数据集的论文中,论文基于在视觉与NLP相关交叉领域的一些工作(Image Captioning,Visual Question Answering等)搭建了几个baseline,然后作者在亚马逊众包平台进行了user study来调研对于人类而言,有哪些影响因素会对基于NLP的行人re-id结果产生影响,作者提出了Recurrent Neural Network with Gated Nueral Attention(GNA-RNN),网络结构如下图所示。
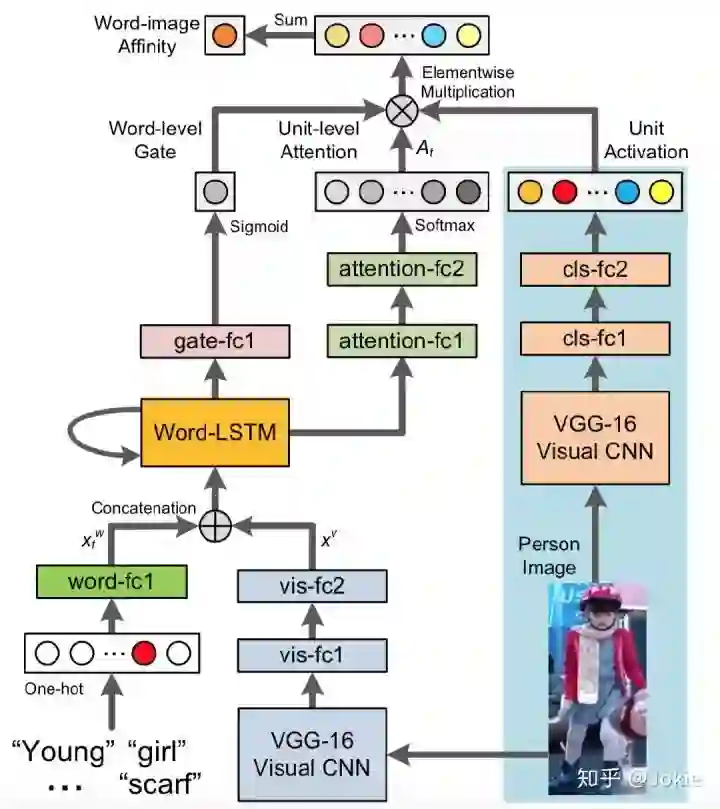
整体框架由2个子网络组成,分别为visual sub-network (VSN)和 language sub-network(LSN)。主体思路是将视觉子网络(VSN)输出的unit activation和文本子网络(LSN)对每个单词提取特征并输出的 word-level gate (类似每个word对于检索结果的影响的权重) 和 unit-level activation三者得到的特征进行element-wise乘积作为每个单词和图片的相关度,最后把一个句子所有word对应的相关度求和得到文本和图片的相关度。
1.Visual Sub-Network
使用VGG-16作为图像的特征提取器,在最后加了2个512维的全连接层,最终产生的是一个512维的视觉向量,也就是输出的Unit Activation。整个visual子网络先在CUHK_PEDES数据集上使用行人ID分类任务进行了预训练,但是在跟LSN联合训练时只更新两个全连接层的参数以提高训练效率。这2个全连接层能在联合训练过程中学习到视觉单元的语义信息。
2.Language Sub-Network
Attention over Visual Units
对于一个description,每个word先被编码成K维的one-hot vector,K是vocabulary size。
给定一个描述语句,有一个可学习(参数会更新)的word-fc1全连接层将word进行word embedding成一个feature,WORD-LSTM每一步的输入是word-fc1和vis-fc2输出的两个feature进行cancat后的vector,输出的hidden state依次经过带Relu层的全连接层attention-fc1和带softmax层的全连接层attention-fc2得到一个512维的Unit-level attention vector,通过这一支路的attention机制,获得了对VSN网络输出的512维度的visual unit vector的attention weights,512个attention weights的加和为1,通过训练能让网络学习并关注到视觉分支(VSN)中与检索任务更相关的视觉语义特征(也就是VSN输出的Visual Units)。下图就表示此时一个description中第t个word文本信息和经过attention后行人图片视觉信息的相关度at。
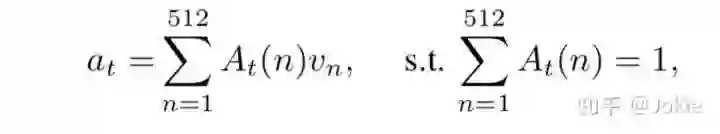
Word-level gates for Visual Units
由于文中user study发现,在亚马逊众包平台对该任务使用人工检索,并按照词性(名词、动词、形容词等)对description进行化简,发现每个word对检索的重要程度不一样(名词>形容词>动词),因此作者认为每个word对相似度的贡献程度应该也要赋予不同的权值。
所以在WORD-LSTM输出的hidden state经过一个带sigmoid的全连接层gate-fc1得到一个标量值作为word的权值gt,gt就代表了每个word对相似度的贡献程度,类似于对word使用了一次attention机制。因此,最终一个description中第t个word文本信息和行人图片视觉信息的相关度就可以表示为下图。
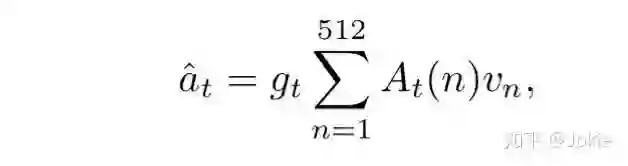
最后一个description中所有的word对应的affinity求和就得到description和行人图片的相关度。
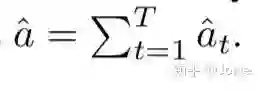
3.Training Scheme
除了上述提到的VGG-16骨架使用行人ID数据进行预训练后冻结权重外,GNA-RNN使用batch SGD进行端到端训练,将训练集的文本图片对随机打乱,batch设置为128,每个batch正负样本比例1:3,使用交叉熵损失进行训练。其中当文本description与行人图片是相关时ground truth标签为1,否则为0。
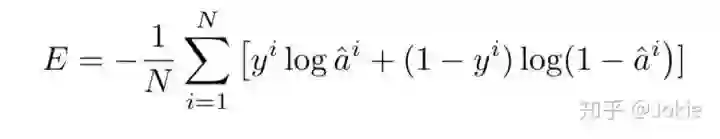
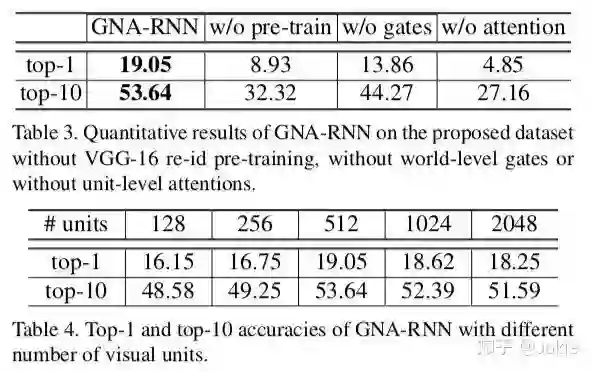
4.实验结果
文中对GNA-RNN与文中构建的一些baseline进行了性能对比,并对是否需要对VGG-16进行pretrain,是否添加word-level gates,是否进行visual unit-level attention以及对visual units的维度对性能的影响进行了ablation study。

Dual Path CNN
论文:Dual-Path Convolutional Image-Text Embedding with Instance Loss
代码:github.com/layumi/Image
这篇文章的motivation在于,作者希望解决一个instance-level细粒度的retrieval,而非class-level或category-level相对更粗粒度的retrieval,这就希望网络能提取到更detail的视觉和文本特征。为此,文中提出了以下贡献点:
除了使用在跨模态检索中work较好的Ranking Loss外,文中提出的Instance Loss进行联合训练,也就是把每个行人ID和相关的Text Descriptions看作一类,进行softmax分类,这样获得更加精细的约束,以使网络学到更加细粒度的特征。
与常见的RNN+CNN结构不同的是,文中采用了双路CNN结构来分别提取文本和视觉特征,通过并行训练,来fine-tune整个网络。
1.网络结构
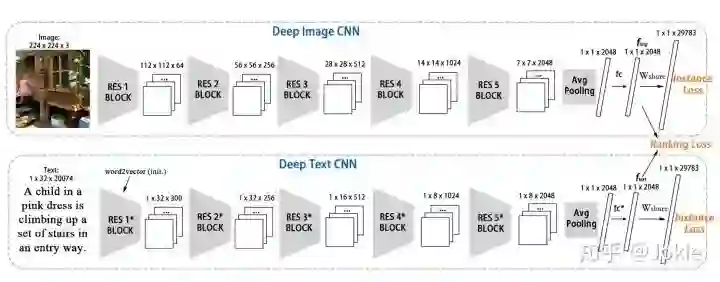
从上图可以看出,文中提出的网络结构非常简单明了,没有attention等“高大上”的机制,直接用2路CNN分别提取Image和Text的特征,最后接了2个全连接层分别得到2048维的视觉特征和文本特征,其中最后一个全连接层是权重共享的以使网络在权重更新中让Text和Image映射到同一个语义特征空间,Text CNN第一个conv层的权重使用了word2vec来初始化,结合Instance Loss和Ranking Loss来对整个网络进行end-to-end训练。
2.损失函数
Ranking Loss
Ranking Loss在检索问题中使用较多,通常使用cosine similarity来表示两个模态间的相似度,取值在[-1,1],值越大表示2个模态间的相似度越高,反之越低。为了更好地拉近两个模态间的相似度,Ranking Loss其实与Triplet Loss非常相似,同样是有Anchor和Negative等概念。由于存在2个模态的特征,因此输入变成了四元组(Ia, Ta, In, Tn),Ia和Ta表示Image Anchor和Text Anchor,也就是一组Image-Text pair正样本,而In和Tn则分别代表了2个模态的负样本。为此,Ranking Loss就可以表达为如下式子:
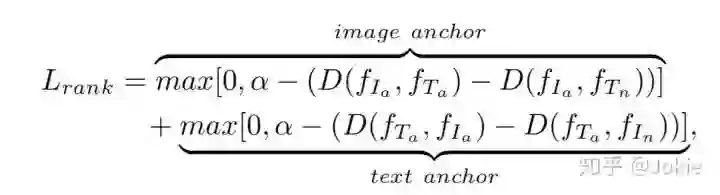
其中α是metric Learning的margin。通过训练,可以增大Image Anchor和text Anchor在特征空间上的cosine similarity,同时减小Image Anchor和Text Negative以及Text Anchor和Image Negative之间的cosine similarity。
Instance Loss
如上文所说,把每个行人ID和所有其相关的Text Descriptions看作一类,进行softmax分类,这样获得更加精细的约束,以使网络学到更加细粒度的特征。为了使网络在权重更新中让Text和Image的特征映射到同一个语义特征空间,最后一个全连接层是权重共享的。
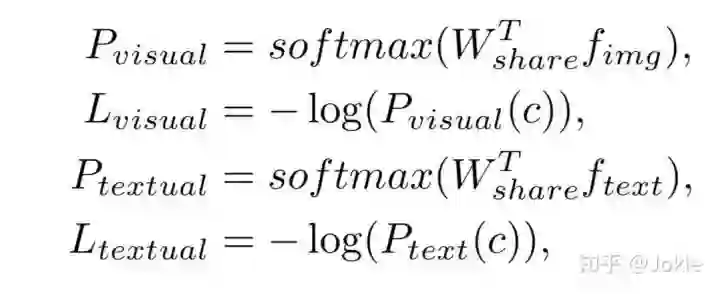
Total Loss
把Ranking Loss和Instance Loss作加权求和,得到最终的Loss。
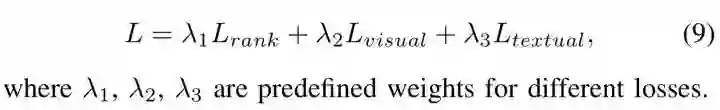
4.训练策略
网络采用2步(2-stage)训练方法对网络进行端到端训练。
Stage 1
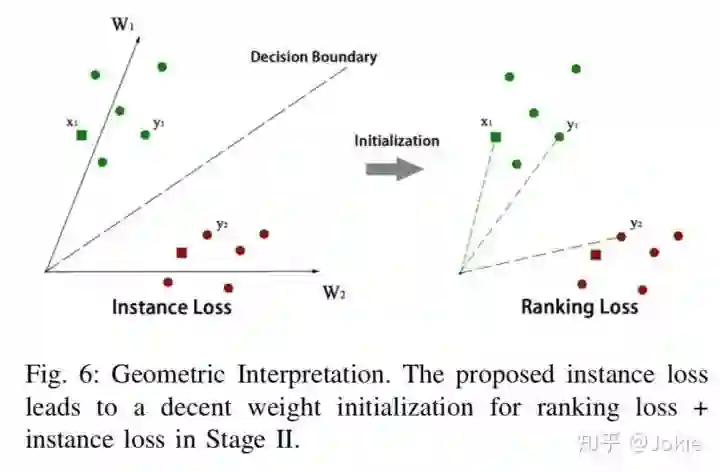
对Image CNN采用ImageNet预训练权重初始化并进行冻结,而Text CNN除了第一个conv层使用word2vec作为权重初始化之外,其他层使用随机初始化,然后仅仅使用Instance Loss对整个网络进行fine tune,文中称这么做的原因是Text CNN支路基本上是train from scratch,如果对2个支路同时训练,由于最后一个全连接层是权重共享的,Text CNN支路可能会对Image CNN支路产生妥协(compromise)。
并且此时仅使用Instance Loss对网络进行训练后可以为后续的Ranking Loss训练获得较好的初始化,因为此时相当于最后一个全连接层对每个Image-Text pair都有了一个类中心W,这样能让后续Ranking Loss进行Metric Learning时更好收敛,如下图所示。
Stage 2
在Stage 1收敛后,开始进行Stage 2的训练,也就是加入Ranking Loss,让Ranking Loss和Instance Loss一同进行训练 (λ1 = 1, λ2 = 1, λ3 = 1),这时不再对Image CNN的权重进行冻结,而是对整个网络进行端到端的fine-tuning,最后让网络收敛到一个更好的性能。
5.实验结果
除了CUHK_PEDES数据集,文中还在MSCOCO和Flickr30k数据集上进行了实验,由于本文主要关注跨模态行人re-id,故这里主要对CUHK_PEDES数据集的实验性能进行展示。
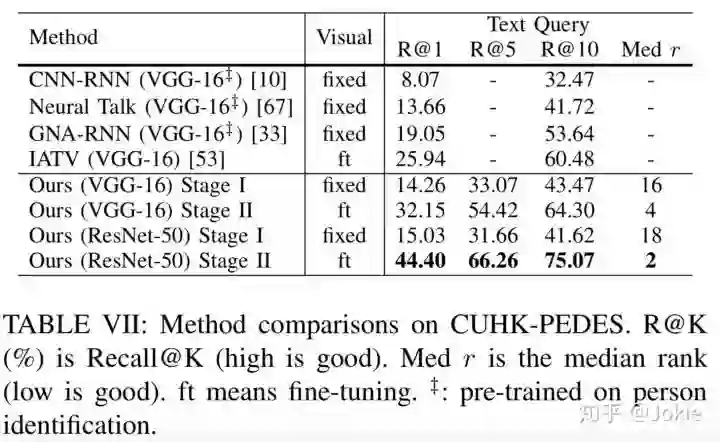
文中还对是否更深的Text CNN能获取更好的性能,是否无监督的聚类方法(如K means)与Instance Loss能获得类似的效果,Text CNN首个conv层是否使用word2vec能获得更好的性能,是否进行Text的Position Shift(文中前面随机空几个位置)能获得更好的性能等等做了详尽的Abalation Study,感兴趣的同学可查看原文。
GALM
论文:Pose-Guided Joint Global and Attentive Local Matching Network for Text-Based Person Search
这篇文章在Dual CNN基础上进行了系列完善,主要的贡献点有:
引入了人体姿态作为监督信息,并结合名词描述特征和视觉特征获得Pose attention相关的特征图,并可视化验证其效果。
对Visual CNN获得的特征应用hard attention机制。

1.网络结构
乍一看网络有些复杂,网络主要分为了3个部分,分别是Global Image-Text Matching,Uni-Local Image-Text Matching和Bi-Local Image-Text Matching。下面将具体介绍网络的各模块。
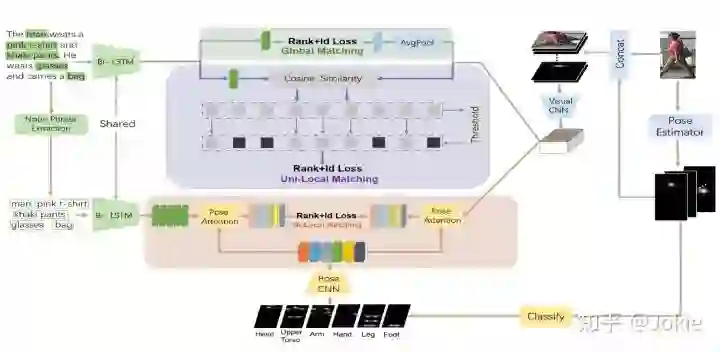
2.特征提取
视觉特征
文中观点认为,人体姿态点与人体的身体部分高度相关,获取并利用行人的人体姿态点能监督跨模态的局部信息matching,网络中的Pose Estimator采用实时高精度的PAF算法[3],并在AI challenge上重新训练,最终对每个行人图片获得14个confidence maps。
这14个confidence maps有2个用途,一是和原始行人3通道RGB图片进行concat获得一个17通道的maps,用于增强视觉信息的表达,然后再输入到Visual CNN(VGG-16,ResNet-50等)中进行提取特征;另外就是用于Bi-Local Matching支路来学习文本名词短语和视觉区域的潜在的语义匹配。
图片样本经过Visual CNN后输出得到一个12x4x512维的特征图,然后对第一维的shape切成6份并对每份求均值得到一个6x4x512维的特征图,这就对应着原图的6x4=24个local视觉特征,每个local视觉特征用一个512维的vector表示。对第二维进行均值池化可以获得global的视觉特征表达。
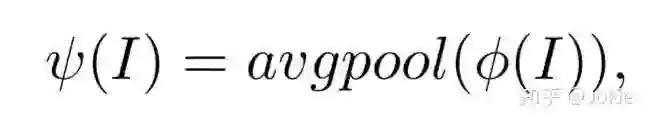
文本特征
使用one-hot vector来表示每个单词tj,再用一个Wt来把单词嵌入到一个特征空间并表示为xj。
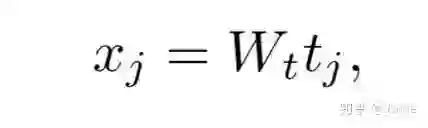
然后使用一个bi-LSTM来学习整个text description所有单词的特征表达
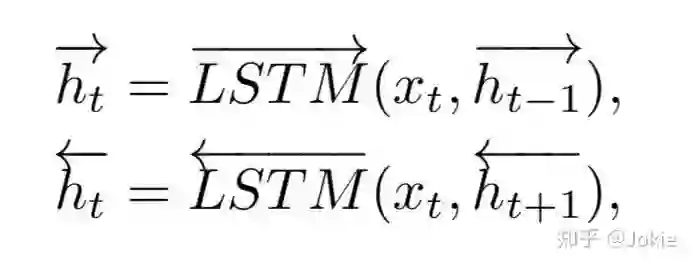
最后把首尾两个隐层空间表达来作为整个text description的特征。
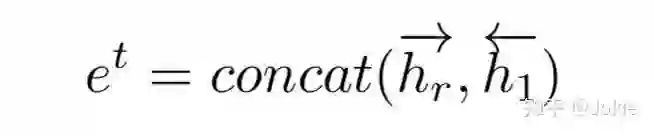
除此之外,作者还使用了NLTK工具包来把text description中的名词短语noun phrases提取出来,并使用上述权重共享的Bi-LSTM来提取每个noun phrase的特征。
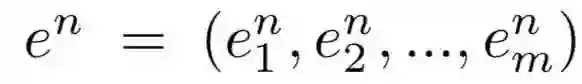
3.网络细节
Global Image-Text Matching
经过上述方式分别提取出文本和global的视觉特征后,再分别使用一个映射权重能让二者映射到同一语义特征空间。
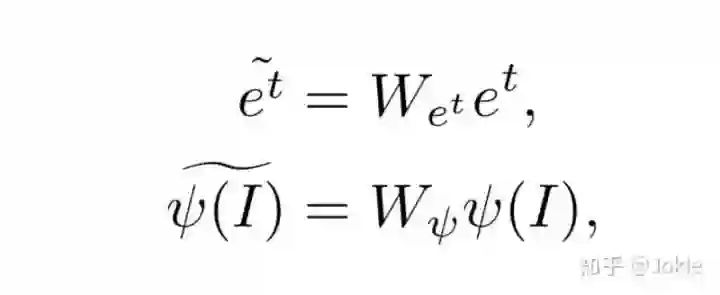
然后简单粗暴,直接对上述二者计算cosine similarity,使用Ranking Loss和ID Loss(就是Dual CNN的Instance Loss)进行约束并训练。
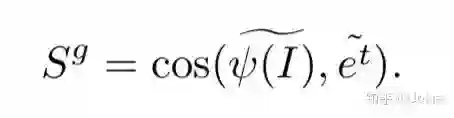
Uni-Local Image-Text Matching
首先,与上述方式类似,对24个Local的视觉特征也使用一个映射权重能让local的视觉特征和文本Text特征映射到同一语义特征空间。
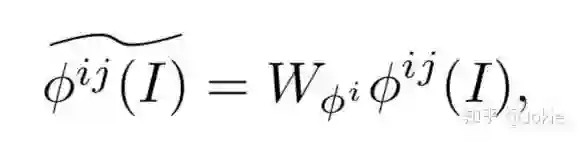

然后就可以计算Local Image-Text之间的cosine similarity。
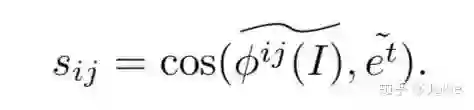
接着使用了一个hard attention的机制,对每个Local Image-Text的similarity计算一个权重q,并设置一个attention阈值r,把所有大于阈值r的Local similarity求和获得Uni-Local Image-Text similarity。
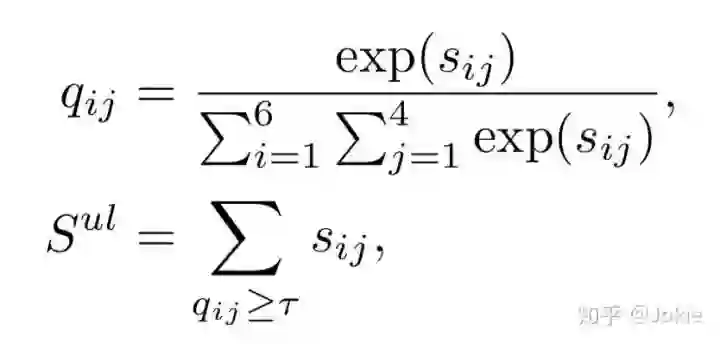
Bi-Local Image-Text Matching
作者认为,一个noun phrase应该对应着图片的某一部分,作者希望网络能够学习到这二者的语义匹配以获得更精准的image-text matching性能。考虑到人体关键点与人体部分息息相关,因此作者选用了人体关键点来监督noun phrase和image regions的matching。把前面Pose Estimator获得的14个keyPoints分为了人体的6个部分:head, upper torso, arm, hand, leg, foot,显然这6者互相之间keyPoints会存在重叠部分。然后把这6部分的confident maps分别使用一个包含4个卷积层和1个全连接层的Pose CNN映射为一个b维的vector。以头部部分得到的向量p1举例,计算一次p1和noun phrase的cosine similarity,然后根据类似softmax的公式获取相应的attention weight,最终可以得到对应noun phrase经过pose attented的表达式为:
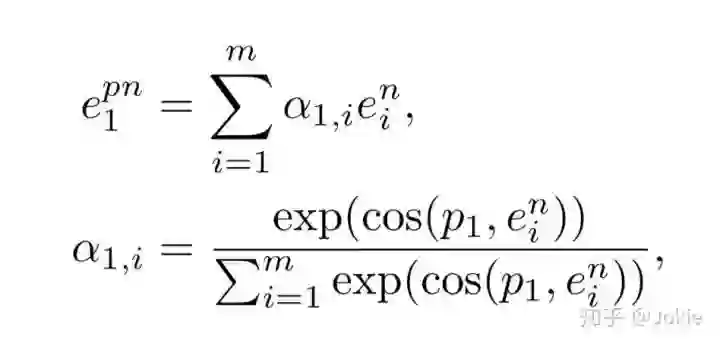
同理也可以获得Image经过pose attented后的特征表达,因此最终得到的Bi-Local Image-Text similarity的表达式为:
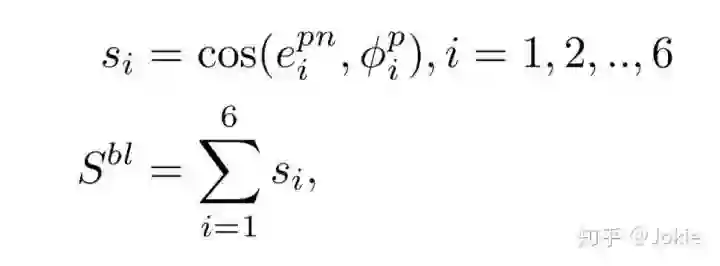
训练GALM
可以看到,对于每个子网络,都使用了Ranking Loss+ID Loss的模式,这与前面的Dual CNN相类似。
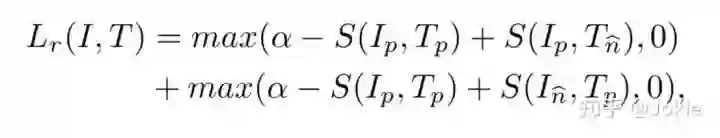
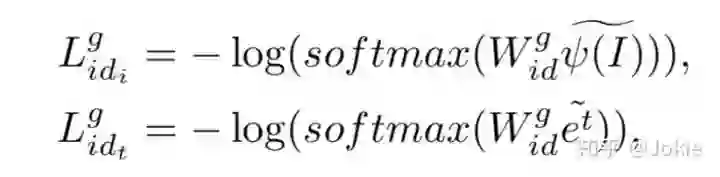
因此Global分支的loss可以表示为下式,并且Uni-Local Image-Text Matching和Bi-Local Image-Text Matching分支均是同理,这里省略。
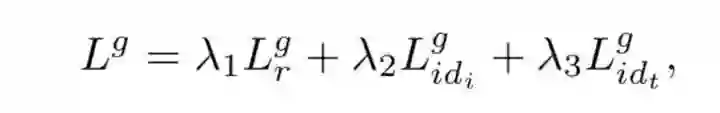
除此之外,还在Bi-Local Image-Text Matching分支中增加了一个part loss来对6种pi进行分类,确保不同的p能关注到image和text的不同部分。
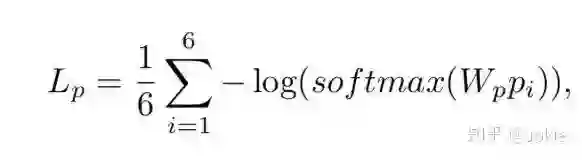
综上所述,Total Loss就可以表示为:
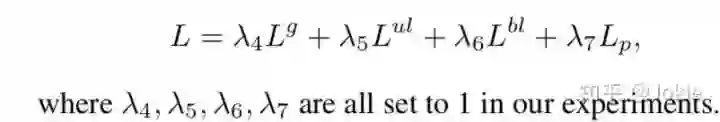
4.实验结果
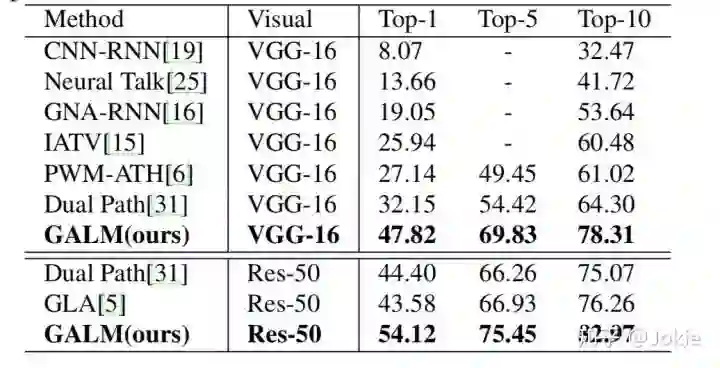
在CUHK-PEDES数据集上进行实验,可见该网络不论骨架采用VGG-16还是ResNet-50,都达到了同水平的SOTA性能。
文中还对分别添加各子模块网络的作用进行了Ablation Study。

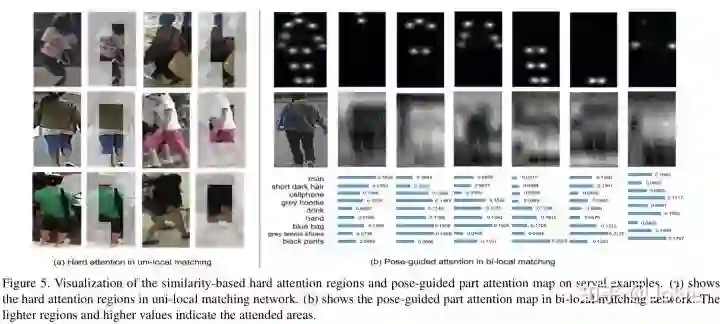
对文中的visual hard attention的regions以及pose-guided attention的attention map进行了可视化,可见经过pose的监督能让visual和noun prase分支都attend到更具可解释性的human body part以及名词上。
小结
本文通过梳理论文的方式为读者逐篇讲解了目前基于自然语言的跨模态行人re-id相关的SOTA方法,作为一个跨模态检索中比较细粒度的子任务,除了最初提出的GNA-RNN使用CE Loss,后续的方法都用上了行人Re-Id常见的类似Triplet Loss的Ranking Loss,并且逐渐从全局模态信息对齐转变成局部模态信息对齐,包括attention机制,利用人体姿态信息加强监督等等。如有错漏或不足,希望读者们多多指导。下一部分我们将继续学习相关领域的SOTA方法,包括:
Identity-aware textual-visual matching with latent co-attention(ICCV 2017)
Improving Text-based Person Search by Spatial Matching and Adaptive Threshold(WACV 2018)
ref="arxiv.org/abs/1808.0157">Improving deep visual representation for person re-identification by global and local image-language association(ECCV 2018)
......
目前正在进行的WIDER Face & Person Challenge 2019其中Track 4就是Person Search by Language,欢迎小伙伴继续关注follow~
参考文献
[1]简书:Person Search with natural language
[2]知乎:用CNN分100,000类图像
[3]Z. Cao, T. Simon, S. E. Wei, and Y. Sheikh. Realtime multi- person 2d pose estimation using part affinity fields. In IEEE Conference on Computer Vision and Pattern Recognition, 2017.
[4]知乎:以人为本的计算机视觉研究,WIDER Challenge 2019
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、算法竞赛、图像检测分割、人脸人体、医学影像、自动驾驶、综合等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

推荐阅读
计算机视觉方向简介 | 立体匹配技术简介

最新AI干货,我在看




