随着深度强化学习的研究与发展, 强化学习在博弈与优化决策、智能驾驶等现实问题中的应用也取得显著进展. 然而强化学习在智能体与环境的交互中存在人工设计奖励函数难的问题, 因此研究者提出了逆强化学习这一研究方向. 如何从专家演示中学习奖励函数和进行策略优化是一个新颖且重要的研究课题, 在人工智能领域具有十分重要的研究意义. 本文综合介绍了逆强化学习算法的最新进展, 首先介绍了逆强化学习在理论方面的新进展, 然后分析了逆强化学习面临的挑战以及未来的发展趋势, 最后讨论了逆强化学习的应用进展和应用前景.
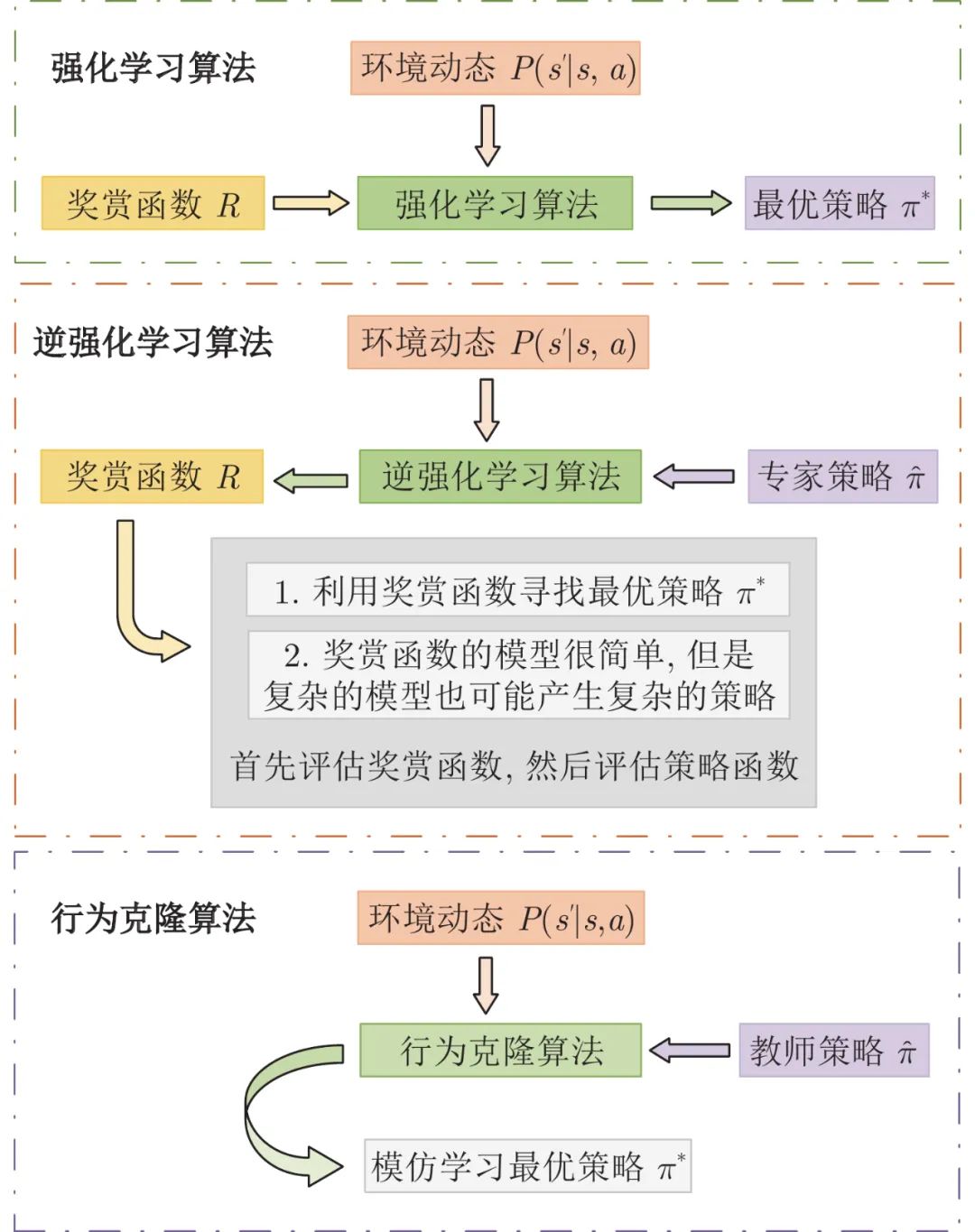
随着人工智能技术的不断发展, 智能决策与控制技术变得越来越重要, 促进了机器学习另一个领域—强化学习(Reinforcement learning, RL)的发展. 目前, 强化学习的理论体系日趋完善, 已经广泛应用于各个领域, 具有巨大的发展前景, 吸引了学术界和工业界的学者对该领域进行深入地探索研究[1-4]. 强化学习算法将策略优化问题建模为马尔科夫决策过程(Markov decision process, MDP), 其主要目标是通过智能体与环境的试错交互, 最大化累积奖励函数和优化策略. 奖励函数作为MDP的重要组成部分, 因此MDP的求解与奖励密切相关[5]. 人为设计奖励函数具有很强的主观性和经验性, 奖励函数的差异会影响强化学习的策略优化. 因此, 如何设计准确的奖励函数是一项非常重要的工作. 然而, 在复杂环境中, 需要考虑多种因素对奖励函数的影响, 很难人为设定准确的奖励函数, 这成为制约强化学习算法发展的瓶颈, 影响了强化学习算法的理论研究和应用发展. 新南威尔士大学Bain等[6]首次较系统地给出了基于行为克隆(Behavior cloning, BC) 的模仿学习(Imitation leaning) 的定义, 该方法采用监督学习的方式, 通过模仿人类专家的动作来学习随机或确定性策略网络. 然而该方法无需学习奖励和推理行为背后产生的内在原因[7], 只能在专家演示下学习最优策略, 无法突破和超越专家演示的最优策略[8]. 因此, 针对如何设计准确的奖励函数的问题, 2000年加州大学伯克利分校Ag等[9]首次提出逆强化学习(Inverse reinforcement learning, IRL) 的概念. 该算法的基本思想是首先利用专家演示反向推导MDP的奖励函数, 然后根据学习的奖励函数去优化策略, 进行正向的强化学习[10].
逆强化学习随着人工智能技术的不断成熟表现出强大的发展潜力, 逆强化学习算法的理论和应用领域不断被完善. 从解决问题的方面来看, 可以分为三大分支. 第一个分支是最早的逆强化学习算法, 主要包括2000年斯坦福大学Abbeel等[11]提出的学徒学习逆强化学习(Apprenticeship learning inverse reinforcement learning, ALIRL)、2006年Ratliff等[12]提出的最大边际规划逆强化学习(Maximum margin planning inverse reinforcement learning, MMPIRL)等算法. 然而, 这类算法存在模糊性问题, 即不同的奖励对应相同的策略. 进而衍生出第二个分支, 基于熵的逆强化学习算法, 主要包括2008年卡内基梅隆大学Ziebart等[13]提出的最大熵逆强化学习(Maximum entropy inverse reinforcement learning, MEIRL)、2011年马克斯- 普朗克智能系统研究所Boularias等[14]提出的相对熵逆强化学习(Relative entropy inverse reinforcement learning, REIRL)等. 基于熵的逆强化学习最初实现的是特征到奖励的线性映射, 随着环境复杂度的增大, 2016年牛津大学Wulfmeier等[15]提出深度逆强化学习算法, 借助神经网络能拟合任意非线性函数的能力来学习非线性奖励函数[16-17]. 在专家演示下, 虽然基于熵的逆强化学习算法一定程度上提高了奖励函数的学习精度, 但有限和非最优的专家演示依然影响着奖励函数的学习. 因此, 2016年, 斯坦福大学Ho等[18]给出了生成对抗逆强化学习(Generative adversarial inverse reinforcement learning, GAIRL)的基本定义, 通过RL和IRL的学习迭代不断优化专家演示, 提高奖励的学习精度. 此外, 在复杂的非线性环境下, 2016年斯坦福大学Levine等[19]提出基于高斯过程的逆强化学习(Inverse reinforcement learning with Gaussian processes, GPIRL), 利用高斯函数的高度非线性确定每个特征与策略的相关性, 求解奖励函数. 三个分支既相互独立又相互补充, 基于以上探讨, 如何构建高效可靠的奖励函数和求得最优策略是逆强化学习研究的重点. 在求解的过程中, 针对出现的模糊性和专家演示非最优的问题, 研究者们提出了不同的应对策略, 在一定程度上解决了这些问题. 本文首先介绍逆强化学习算法的发展历程, 然后重点介绍和讨论了逆强化学习算法的应用进展及算法面临的挑战.
本文内容安排如下: 第1节介绍了马尔科夫决策过程、逆强化学习、强化学习、行为克隆等算法的基本概念和知识; 第2节介绍解决MDP问题的逆强化学习算法的研究进展; 第3节介绍了逆强化学习算法的应用进展; 第4节介绍逆强化学习算法面临的挑战及解决方案; 第5节对逆强化学习算法的未来进行展望; 第6节对本文内容进行总结.