

摘要
现实生活中的问题是动态的,并且与具有多种选择的决策过程有关。我们需要通过优化来解决其中的一些动态决策问题。当我们需要在决策过程中对多个参数进行权衡时,特别是在动态环境中,解决这些问题具有挑战性。然而,在人工智能(AI)的帮助下,我们可以有效地解决这些问题。本研究旨在研究利用深度强化学习(DRL)算法为动态多目标环境开发一个智能决策方案。这包括在强化学习(RL)环境中开发一个动态多目标优化领域的基准,这刺激了使用传统的深海宝藏(DST)基准开发一个改进的测试平台。拟议的测试平台是在改变最佳帕累托前沿(PF)和帕累托集(PS)的基础上创建的。就我所知,这是第一个用于RL环境的动态多目标测试平台。此外,还提出了一个框架来处理动态环境中的多目标,从根本上保持不同目标之间的平衡,以提供一个与真正的PF相近的折衷方案。为了证明这一概念,所提出的模型已经在现实世界的场景中实施,以预测基于巴西圣保罗水质弹性的脆弱区域。
所提出的算法,即奇偶深度Q网络(PQDQN)被成功实施和测试,智能体在实现目标(即获得奖励)方面表现优异。尽管与多目标蒙特卡洛树搜索(MO-MCTS)智能体相比,该智能体需要更多的训练时间(即步骤数),但与多策略DQN(MPDQN)和多帕累托Q学习(MPQ)算法相比,其寻找帕累托最优解决方案的准确性明显提高。
结果显示,所提出的算法可以在动态环境中找到最优解。它允许在不对智能体进行任何再训练和行为调整的情况下适应新的目标。它也制约着需要选择的策略。就动态DST测试平台而言,它将为研究人员提供一个进行研究的新维度,使他们能够在解决动态性质的问题时测试他们的算法。
关键词:深度强化学习,多策略,多目标优化,动态环境,深度Q网络,矢量奖励,基准,水质评价,复原力。
第1章 简介
今天的人类生活受益于科学及其各种应用。特别是,人工智能(AI)增加了一个新的层面,使人们相信人类的智慧可以被人工取代。然而,智能本身是如此庞大、自发、原始和不确定,以至于在不久的将来,它可能无法被纯粹地复制或取代。尽管如此,还是有强大的科学团体相信这种替代,从学术角度来看,它确实值得赞赏(Jarrahi, 2018; King and Grudin, 2016)。
然而,智能的机制可以通过建立机器、智能体和系统,甚至编写计算机程序,在一定的边界内进行分析。这种人工开发的系统可以协助人类做出更好的决定,或根据人类定义的一套规则行事(Duan, Edwards and Dwivedi, 2019)。换句话说,科学界在开发学习如何智能并相应执行的系统方面会有更大的成功(Julian Togelius,2007;Yannakakis和Togelius,2015)。本论文的重点是建立一个智能决策方案,处理多目标(MO)环境中的动态问题。更具体地说,本研究指导如何开发一个计算机应用程序,使其学习到智能,并在动态多目标(DMO)环境中使用深度强化学习(DRL)执行识别优化的解决方案。
人类生活由各种问题组成,这些问题是动态的、多参数的和复杂的。每一个问题都需要遵循不同的步骤来做出最终决定,如果有一个以上的选择,就需要进行优化。因此,多目标优化,一个为问题寻找最佳解决方案的过程,在最近几年变得很流行(Zaroliagis和Christos,2005;Botte和Schöbel,2019)。许多问题涉及连续变化的属性,需要从许多可用的解决方案中找到一个最佳解决方案,这非常具有挑战性。例如,预订航班或酒店,安排班级常规,以适应因工作人员缺席和房间不可用而产生的不断变化,在战争中部署一支军事部队等等。这些场景需要动态优化,因为决策需要根据情况经常改变。另一个例子是癌症患者的用药,其目标不仅仅是在较短的时间内治愈他们,而且要尽量减少药物的副作用(Preissner等人,2012)。这个问题还涉及到用药期间可能出现的任何新情况的风险。
在计算智能领域,解决这些动态多目标优化问题(DMOPs)的常见方法是进化方法(Azzouz, Bechikh and Said, 2017; Lam, Branke and Abbass, 2005)。然而,最近,多目标优化领域的许多科学文献显示,在使用多目标马尔科夫决策过程(MOMDP),特别是使用强化学习(RL)技术来解决问题时,出现了截然不同的视角(Lizotte和Laber,2016;Drugan等人,2017;Bamakan、Nurgaliev和Qu,2019)这种技术的主要目标之一是达到被称为帕累托最优解(POS)的解决方案集,它尽可能接近真正的帕累托最优前沿(POF)。这些技术不仅可以找到帕累托前沿的形状,而且还有助于调查和解码解决方案可能具有的有趣事实(Gopakumar等人,2018)。此外,最近多目标马尔科夫决策过程(MOMDP)不仅因其适用性,而且在解决实际的多目标问题方面也受到了极大的关注(Lizotte和Laber,2016)。为了解决MOMDP,常见的方法是使用状态、行动和奖励函数来定义RL模型。奖励函数可以是标量或矢量。然而,根据奖励假设(Sutton和Barto,2018),目标和目的可以用收到的标量信号(即奖励)的累积总和的期望值最大化来正式确定。换句话说,所产生的MOMDPs总是可以转化为具有聚合回报的单一目标MDPs。
然而,Roijers等人(2013)拒绝了Sutton的观点,质疑其在现实世界中的应用。他们提出了三种静态场景(即已知权重、未知权重和决策支持场景),作者表明其中一种或两种转换是不可能的、不可行的或不可取的。此外,就DMOPs而言,由于缺乏测试平台,该领域的研究非常少(Azzouz、Bechikh和Said,2017)。在这项研究中,通过提出一个动态多目标测试平台(即动态深海寻宝)来解决这一研究空白,这可能会引导研究人员在这一领域做进一步调查。据我所知,这是在使用DRL的动态多目标优化方面的第一项工作。此外,关于RL环境的动态多目标优化基准的必要性的论证已经确立,因为问题空间的复杂性和在合理的时间范围内找到一个解决方案是计算密集型的,如NP-hard或NP-complete问题(Plaisted,1984)。此外,还提出了一种算法,该算法主要负责在定义的动态环境中处理一个以上的目标。之后,该算法的实施被认为是根据巴西圣保罗(SP)22个地区的水质恢复力来识别和预测脆弱地区,这确保了所提算法的适用性和效率。这种实施方式打破了理论知识的界限,有助于解决实际问题。
关于实施,只考虑了基本网络,它有461个数据采集点。水体的流量测量是由圣保罗环境公司(CETESB)与圣保罗州水和能源部合作进行的。其结果是通过读取刻度来测量水体中的流量来取样。2017年,核心网络产生了约118,000个(如物理、化学、生物、生物分析和生态毒理学)数据量(Publicações e Relatórios | Águas Interiores, 2017)。这一实施也可能导致解决我们每天面临的其他一些动态的现实世界问题。
1.1 动机
我们生活在这样一个时代,毫无疑问,技术已经极大地改变了我们的工作方式。根据牛津大学的经济学家Carl Frey博士和Michael Osborne博士的说法,所有类别的工作有40%都有可能因为自动化而失去(Benedikt Frey等人,2013)。人工智能(AI)和机器学习(ML)将不可避免地对这种替代产生严重影响(Chris Graham,2018),甚至在政策制定方面(Federico Mor,2018)。关于人工智能对人类的影响,有两派不同的观点(Dwivedi等人,2019;Zanzotto,2019)。一派认为,人工智能很可能对人类产生破坏性影响(Clarke,2019),而另一派则期望人工智能对人类的进步起到积极作用(Woo,2020)。然而,这种争论只有在未来人工智能技术充分发展的时候才能得到解决。在这个自动化过程中,未来将对就业部门产生重大影响,而人工智能将是这种数字化的开拓者(Syed等人,2020)。
为此,计算智能研究人员将更多地参与到使用机器人、增强和虚拟现实以及游戏环境的模拟中。在这整个过程中,游戏或游戏环境将是分析不同算法、模拟问题和提供解决方案的关键组成部分之一。明显的原因是,游戏环境可以作为设计、开发、实施、测试、修改和改进算法的小白鼠(Justin Francis,2017)。遵循同样的宗旨,本研究解决了DMOP领域的一个空白,并在模拟环境的帮助下提出了一个基准,作为对该领域的贡献。
在这篇论文中,我们创造了一个动态的游戏环境,其中有一组相互冲突的目标。如前所述,问题的目标和约束条件相互之间是动态变化的,而且总是在不断发展。为了解决这个问题,进化算法(EA)被广泛用于处理优化问题。然而,由于随时间变化的动态性,DMOPs的解决更具挑战性,EA在解决这些问题时常常面临困难(Jiang等人,2018)。
尽管如此,在2015年DeepMind的成功之后(Mnih等人,2015),人们对使用RL特别是深度强化学习(DRL)解决顺序决策中的多目标优化的兴趣越来越大(Arulkumaran等人,2017)。本研究也是受这一成就的激励,打算从深度RL的角度增加价值,解决动态多目标优化的问题。此外,还考虑了一个水质测试案例,这是由人类非常关键的需求之一所鼓励的,特别是在21世纪。在这项研究中,对水质恢复力进行了深入研究,并使用机器学习(ML)技术(即DRL)来确定巴西某个城市的关键区域。在这项研究中,提出了一种称为奇偶性Q深Q网络(PQDQN)的新方法,它能够在动态DST环境中找到非主导的解决方案,并根据动态多目标环境中的水质复原力预测脆弱区域。智能体在这些环境中进行互动,这些环境是基于多目标马尔科夫决策过程(MOMDP)的,并且能够在RL环境中获得奖励。
1.2 目的和目标
在这项研究中,主要目的是解决现有测试平台在强化学习背景下的动态多目标优化的挑战。本研究的次要目的是为动态多目标环境研究和开发一个适当的决策框架。为了实现这些目标,我们确定了以下目标。
a) 调查当前在RL背景下动态多目标优化的最新进展。
b) 设计和开发一个用于RL环境下动态多目标优化的概念和数学模型。
c) 设计和开发一个新的动态多目标优化测试平台,用于RL环境。
d) 设计和开发一种使用深度强化学习的新算法,该算法可以处理动态和优化多目标环境下的决策。
e) 应用所提出的算法来解决一个现实世界的问题,即利用巴西圣保罗州的水质复原力来识别和预测脆弱区域。
1.3 研究问题
本研究对以下研究问题的答案进行了调查。
-
Q1: 提出的基准能否解决RL环境的DMOP研究领域的空白?
-
Q2:基于DRL的算法如何处理多个目标并根据水质预测脆弱区域?
1.4 主要的科学贡献
本研究工作的主要科学贡献如下。
a. 为RL环境的动态多目标优化设计和开发了一个新的和创新的测试平台。
b. 首次使用目标关系映射(ORM)来构建不同目标之间的元策略(如治理策略),以找出折中的解决方案。
c. 开发了一种新的方法来验证所提出的算法在现实世界中的适用性,该算法根据巴西圣保罗的水质复原力来识别和预测脆弱区域。
d. 通过广泛的文献回顾,在RL环境的DMOP背景下确定研究差距。
1.5 测试案例
1.5.1 测试案例1
深海宝藏(DST)是一个游戏环境。它是一个标准的多目标问题,也是由(Vamplew等人,2011)引入的RL环境的测试平台。这是流行的测试平台之一,在多目标RL研究的背景下,已经多次出现在文献中。这个环境由10行和9列组成,有三种不同类型的单元,如船只可以穿越的水单元,不能穿越的海面单元,因为这些单元是网格的边缘,还有提供不同奖励的宝藏单元。当智能体到达宝藏单元时,DST游戏结束。
在这里,智能体控制着一艘潜水艇,在海底寻找宝藏。智能体的目标是在最短的时间内找到价值最高的宝藏(即冲突的方式)。它有决定性的过渡,有非凸边界。潜水艇从网格的左上角开始,可以向上、向下、向右和向左移动。与单目标环境不同的是,智能体获得矢量奖励。奖励由每次移动的惩罚-1(即RL的负奖励)和取得的宝物价值组成,宝物价值为0,除非智能体到达宝物的位置时收到宝物的数量(即RL的正奖励)。最佳帕累托前线有10个非支配性的解决方案,每一个宝藏都有一个。锋面是全局凹陷的,在宝藏值为74、24和8时有局部凹陷。最佳前线帕累托前线的超体积值为10455。图1.1显示了一个经典的和静态的DST测试平台,其中最低的宝藏值是1,最高的是124。
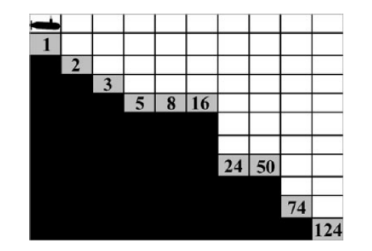
图1. 1:作为测试案例1的深海寻宝(DST)环境
1.5.2 测试案例2
选择测试案例2是为了让所提出的算法(即PQDQN)和方法(即MOMDP)能够解决巴西一个拥挤的城市中的实际问题。考虑到这一庞大人口的公共供水问题,圣保罗州政府正在努力实现该州各市镇的普遍卫生设施,在那里,各种服务(如测量和维护水质、污水处理服务等)的人口比例增加。然而,水污染恶化了水的质量,阻碍了圣保罗的可持续发展(Governo do Estado de São Paulo | Eleições, 2018)。河流、水库、河口和沿海地区水域中存在的污水降低了水质,限制了其多种用途,同时增加了因初次接触或摄入受污染的水而引起的水传播疾病的发生(Nogueira等人,2018)。
为了确定脆弱地区并在这些地区采取适当的行动,需要大量的人力和费用。这些行动涉及综合管理行动,涉及与工农业污水使用管理、人力资源(HR)管理的复杂性、固定资产和反应性或计划性维护有关的各个部门和组织(Barbosa, Alam and Mushtaq, 2016)。因此,重要的是实现流程自动化,以尽可能快地检测出脆弱区域。因此,基于人工智能的最佳决策支持系统可以减少管理这种巨大任务的成本,并可以产生社会经济影响,这可能有助于可持续发展。图1.2显示了测试案例2的鸟瞰图,其中智能体能够根据水质恢复力预测脆弱区域。
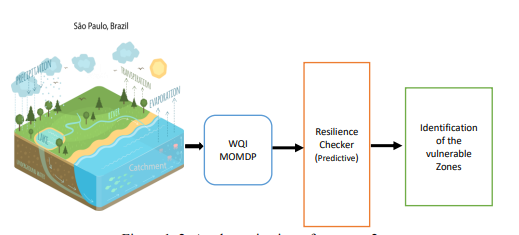
图1.2:测试案例2的示意图
简而言之,该测试案例中发现的问题如下:
-
这是一个动态问题,考虑到水质数据因各种因素而随时间变化。
-
收集这些数据是昂贵的,需要人力资源。
-
由于手工检查和计算,识别脆弱区很困难。
-
针对不同区域的投资优化很复杂。
-
确定各区的优先次序以提高水质是非常耗时的。
1.6 可交付的成果
本研究的成果在下面列出了出版物清单。
杂志:
Md Mahmudul Hasan, Khin Lwin, Maryam Imani, Antesar Shabut, Luiz Fernando Bittencourt, M.A. Hossain, "Dynamic multi-objective optimisation using deep reinforcement learning: benchmark, algorithm and an application to identify vulnerable zones based on water quality", Engineering Applications of Artificial Intelligence, Publisher: Elsevier, Volume 86, 2019, Pages 107-135, ISSN 0952-1976, https://doi.org/10.1016/j.engappai.2019.08.014.
IEEE会议:
1.Md Mahmudul Hasan, Khin Lwin, Antesar Shabut, Alamgir Hossain, "Design and Development of a Benchmark for Dynamic Multi-objective Optimisation Problem in the Context of Deep Reinforcement Learning", 22nd International Conference on Computer and Information Technology, Dhaka, 2019. IEEE Xplore数字档案链接:https://ieeexplore.ieee.org/document/9038529
2.Md Mahmudul Hasan, Ali Mohsin, Maryam Imani, Luiz Fernando Bittencourt, "A novel method to predict water quality resilience using deep reinforcement learning in Sao Paulo, Brazil", International Conference on Innovation in Engineering and Technology(ICIET), Dhaka, 2019.
3.M. M. Hasan, K. Abu-Hassan, Khin Lwin and M. A. Hossain, "可逆决策支持系统。Minimising cognitive dissonance in multi-criteria based complex system using fuzzy analytic hierarchy process," 2016 8th Computer Science and Electronic Engineering (CEEC), Colchester, UK, 2016, pp.210-215. IEEE Xplore数字档案。链接:https://ieeexplore.ieee.org/document/7835915
其他国际会议:
1.Md Mahmudul Hasan, Khin Lwin, Antesar Shabut, Miltu Kumar Ghosh, M A Hossain, "Deep Reinforcement Learning for Dynamic Multi-objective Optimisation", 17th International Conference on Operational ResearchKOI 2018, Zadar, Croatia, 2018.
其他贡献:
1.Md Mahmudul Hasan, Md Shahinur Rahman, Khin Lwin, Antesar Shabut, Adrian Bell, M A Hossain, "Deep Reinforcement Learning for Optimisation", "Handbook of Research on Deep Learning Innovations and Trends "的书籍章节,出版商。IGI Global,2018。链接:https://www.igi-global.com/chapter/deep-reinforcement-learning-for-optimization/227852
2.2017年PACKT出版社出版的《Machine Learning for Developers》一书的技术评审员。链接:https://www.packtpub.com/big-data-and-business-intelligence/machine-learning-developers
3.Md Mahmudul Hasan, "Predicting Water Quality Resilience: A Machine Learning Approach", 8th FST Conference, ARU, UK, 2019.
4.Md Mahmudul Hasan, "A robust decision support system in dynamic multiobjective optimization using deep reinforcement learning", 12th Research Student Conference, ARU, UK, 2018.
5.最佳博士论文发表,第7届FST会议,ARU,英国,2017。
6.Md Mahmudul Hasan, "Optimising decision in a multi-criteria based environment", seminar at ARITI, ARU, UK, 2017.
1.7 术语和风格说明
以下部分代表了本研究中经常使用的常用术语。
智能体:智能体或算法生活在模拟环境中,帮助做出决策。
状态:状态有助于确定由智能体决定的下一个步骤。
行动:智能体通过观察新的状态和接受奖励,在不同的状态之间可能的移动。
政策:政策通常表示智能体选择行动的行为。
环境:环境是智能体的外部实体,它与状态相互作用。环境可以是完全可观察的(即智能体直接观察环境)或部分可观察的(即智能体间接观察环境)。
静态环境:不发生变化的环境,或受变化的参数和约束的影响。
动态环境:随时间变化的环境。更具体地说,受目标函数、约束条件和问题参数影响的变化状态。
奖励:智能体有一个特定的任务,需要通过行动来完成。在有限水平线或偶发环境中,预期回报通常是标量奖励的未贴现的有限总和,直到智能体达到终端状态。
决策空间:这个术语用来定义代表选择的空间,以做出决策。
目标空间:这个空间定义了基于目标的支配性和非支配性解决方案。
值得一提的是,为了让读者合理地阅读这篇论文,我们使用了最少的首字母缩写词和数学术语,使读者感到轻松和愉快。在一些章节的末尾,提供了一个图形表示,以提供一个可视化和概念性的理解。此外,有些地方的数学公式是以可读的形式描述的。然而,在某些地方已经向读者做了充分的介绍,以便他们可以从相关的来源收集更多的信息。此外,一些词语(如快、慢、快、长)被用来例证收敛性、耗费的训练时间和识别真正的PF的性能,由于在优化和RL领域对真正的PF的近似(如移动全局最优),这些词语被广泛陈述和利用(Moffaert和Nowé,2014;Lin等人,2017;Farina、Deb和Amato,2004;Mehnen、Wagner和Rudolph,2006;Sutton和Barto,2018)。此外,之前对强化学习的熟悉程度可能会对读者跟随和享受阅读产生明显的影响。
1.8 论文的组织
本论文的组织结构如下所示。
第二章回顾了相关的研究工作,其中强调了智能应用、决策支持系统、马尔科夫决策过程、机器学习、强化、深度强化学习、现有基准和优化技术的概述。本章还代表了对基本组成部分的全面分析,以增强论文成果的可读性,如回顾分析算法的性能指标。最后,本章对研究的理由进行了说明。
第三章涉及研究的方法,其中解释了研究设计。本章还涉及到方法的细节和进行这项研究的必要方法。它还对数据准备、水质参数选择和弹性计算方法进行了全面分析。
第四章讨论了问题背景和实验背景,其中描述了数学和概念模型。在这一章中,描述了拟议的基准、网络结构和对现实世界场景中MOMDP的形式化的详细讨论,以及两个测试案例的实验背景。
第五章解释了拟议算法的高层结构。在这一章中,已经解释了所提出的算法的一步一步的工作程序。此外,本章还讨论了开发拟议算法所需的工具,如必要的软件、库和机器环境。
第章介绍了实证分析和讨论,其中也阐述了关键的审查和限制。在这一章中,还提到了性能测量标准和选择这些标准的理由。此外,还解释了拟议算法的优点和缺点。
最后,第七章阐述了本论文的结论和未来方向。未来方向包括开展现有研究的近期和长期目标。本章还解释了两个测试案例的进一步可能方向。

