
摘要
物联网 (IoT) 和网络物理系统的指数级增长导致了复杂的环境,其中包括各种相互交互和与用户交互的设备。此外,人工智能的快速发展使这些设备能够通过使用强化学习 (RL) 等技术自主修改其行为。因此,需要在网络边缘建立一个具有全局环境视图的智能监控系统,以自主预测最佳设备动作。然而,很明显,确保此类环境中的安全至关重要。为此,我们为物联网环境开发了一个受约束的 RL 框架,该框架使用深度 Q 学习确定与用户定义的目标或所需功能相关的最佳设备操作。我们在网络边缘使用基于异常的入侵检测来动态生成安全策略来约束框架中的 RL 智能体。我们通过操纵 RL 框架中对安全和不安全利益状态空间的探索来分析物联网环境中“安全/保障”和“功能”之间所需的平衡。我们实例化了用于测试智能家居环境中应用层控制的框架,以及网络层控制,包括速率控制和路由等网络功能,用于基于 SDN 的环境。
1 引言
物联网 (IoT) 与网络物理系统相结合的部署导致了复杂的环境,其中包括各种设备相互交互以及通过在手机、平板电脑和台式机等计算平台上运行的应用程序与用户交互。物联网设备通信协议的发展,如 6LowPAN、CoAp 和 Zigbee,以及人工智能的进步,使得互连这些不同的物联网设备并实现智能自主物联网系统成为可能。然而,基于物联网的智能系统需要设备、应用程序、用户和边缘之间的互连和互操作。如此复杂的物联网设备和应用程序相互动态交互的环境很容易出现安全/安全问题[1]-[3]。另一个问题是,就功能而言,每个应用程序都有特定的个人目标。但是,在选择要执行的操作时,应用程序不会考虑物联网设备部署环境的全局视图。这种缺乏意识可能导致在用户需求或目标方面不是全局最优的决策和行动。显然,需要“智能”监控系统来确保安全并最大限度地利用所有设备和应用程序及其交互的全局视图来最大化功能。
真正的“智能”系统需要环境中的物联网设备智能地协同工作,以支持用户使用隐藏在连接这些设备的网络中的信息和智能以“安全”和“最佳”方式执行他们的活动,几乎不需要用户管理,并且可以根据历史和实时数据做出明智的决策。网络边缘是部署此类智能监控系统的理想场所,因为它可以访问学习所需的实时和历史数据,以及运行强大的机器学习方法所需的强大计算和存储能力。随着边缘计算的最新进展,用于开发我们的框架的雾计算范式 [4],[5] 在安全性、隐私性、可扩展性、可靠性、速度和效率方面提供了优于传统分布式和云计算的优势。最重要的是,软件定义网络(SDN)、零信任安全架构和网络功能虚拟化(NFV)在大型现代企业和5G网络中的出现和成功部署,为构建“智能”网络控制器提供了可能利用机器学习 (ML) 技术来学习优化和安全流量工程的策略。
随着人工智能的快速发展,强化学习 (DRL) 已成为使这些设备能够自主修改其行为的强大工具。将 DRL 应用于 IoT 和 SDN 环境是一个有利可图的概念。但是,任何以优化为单一目标的机器学习智能应用都不会考虑由于环境参数而达到的不安全状态。以前的工作集中在构建基于应用层 RL 的解决方案,以优化具有特定目标的物联网环境,如能源管理 [6],[7]、最佳资源分配 [8]、能源价格最小化 [9] 等。类似的方法已经被用于优化网络层功能,例如 SDN 环境中的路由,例如路由 [10]-[13] 和速率控制/负载平衡 [14]、[15]。如前所述,这些 RL 框架的缺点是它们专注于优化某些目标,但没有考虑环境的安全性。
1.1 研究问题
需要部署在网络边缘的自主控制系统,能够支持应用程序/用户,通过在应用程序和网络层提供最佳设备操作,在所需功能方面为用户最大化 QoS,同时保持安全并保护受监控的物联网环境。
1.2 挑战
我们解决此类研究问题的方法是基于 DRL 技术的使用,该技术受到安全策略使用的限制。然而,为复杂的物联网环境设计这种方法需要解决几个挑战:
- 1.安全策略取决于在环境中检测到的入侵类型,这些环境通常具有各种感染源、阶段和载体,如恶意软件、基于网络的攻击、恶意内部人员、旁道攻击、良性用户妥协、僵尸网络攻击等。由于攻击面迅速增长并随环境而变化,因此挑战在于能够动态指定合适的安全策略。
- 2.RL 框架通过“自由”探索其环境(状态空间)来学习,以找到最佳策略。挑战在于建立一个强化学习框架,其中智能体受这些安全策略“约束”,但同时可以“自由探索”,以便在物联网生态系统中学习“最佳”和“安全”行动。因此,一个挑战是在智能体探索中确定“不安全状态空间”方面的“约束”和“安全状态空间”方面的“自由”之间的正确权衡。
- 3.所有 RL 框架都在环境或环境本身的模型(模拟)上工作。为物联网环境构建模型具有挑战性,因为噪声、用户错误、故障等变量的固有分布不稳定。完全无模型的方法需要实际经验才能进行训练,这使得探索更加危险。
- 4.RL 框架应该是灵活的,可以以最少的人力适用于不同的环境。因此,理想情况下,RL 框架不仅应该从他们的经验中学习最优策略,即状态-动作对奖励,还应该了解模型本身或更具体的状态转换概率。
- 5.由于设备、用户、环境特定功能等方面的差异,为一个 IoT 环境学习的策略通常不能直接应用于其他 IoT 环境。因此,挑战是在一个环境中使用从学习策略获得的知识并将它们应用到不同环境的语境。
- 6.在此类环境中,安全性的单点故障是中央 SDN 控制器本身,它可以通过网络层攻击(如 DoS、DDoS、BruteForce 和基于 Web 的攻击)受到损害。因此,一个挑战是学习 SDN 边缘控制器以及应用层边缘控制器的最佳策略。这需要学习针对核心网络功能(如路由、速率控制等)的安全约束优化策略。
1.3 解决方案
为了解决上述研究问题,我们设计了一个包含三个主要组件的架构:E-Spion、Jarvis 和 Jarvis-SDN。从 E-Spion 日志中学习到的安全和安全策略用于构建 Jarvis DRL 框架的模型或状态转换概率,如图 1.1 所示。形式上,Jarvis 和 Jarvis-SDN 可以定义为基于 Dyna-Q 框架 [16] 的基于模型的 RL 框架,其中:(i) 从 E-Spion 学习安全/安保策略方面的环境模型,以及 (ii) 学习模型的最优策略由 RL 代理从模拟经验中学习。我们提供了有关以下三个组件中的每一个的更多详细信息。
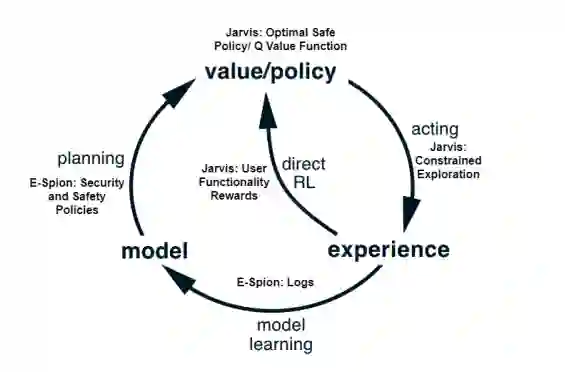
图 1.1 学习架构的高级概述
1.3.1 E-Spion:基于边缘的物联网环境入侵检测
E-Spion 是用于物联网设备的基于异常的系统级入侵检测系统 (IDS)。它使用系统级信息(例如运行过程参数及其系统调用)以自主、高效和可扩展的方式根据物联网设备的“行为”对其进行分析。然后使用这些配置文件来检测指示入侵的异常行为。我们的 IDS 的模块化设计以及独特的设备边缘拆分架构允许在物联网设备上以最小的开销进行有效的攻击检测。我们的设备配置文件使用三种类型的设备日志(每层一个)构建在三层中,这些日志从三种类型的信息中获取:运行进程名称、运行进程参数和这些进程进行的系统调用。由于这些日志类型中的每一种都有不同的记录、存储和分析开销,因此我们维护了三个独立的模块来处理每种类型的设备日志,即 PWM、PBM 和 SBM。这些模块可以根据设备/网络要求(资源消耗、相关风险等)以不同的配置值(记录间隔、睡眠时间等)同时运行。模块使用通用模块管理器相互交互,以提高整体检测效率,提供更细粒度的入侵警报,并减少设备上的开销。通过搜索异常行为,可以从 E-Spion 日志中提取环境的安全和安全策略。
1.3.2 Jarvis:一个为物联网环境量身定制的受限DRL框架
通过观察具体的 IoT 环境,Jarvis 首先根据设备状态和动作动态构建模拟环境。受安全策略约束的代理可以在特定时间段的多个情节中遍历模拟环境,并根据用户提供的功能需求找到最佳的安全动作。深度 Q 学习网络 (DQN) 用于确定每个环境状态和时间实例的最高奖励(质量)动作。 Q 学习方法非常适合这样的环境/生态系统,在这种环境/生态系统中,对于每个状态-动作对,我们可以根据用户目标在一段时间内通过累积奖励来确定其质量。我们使用深度神经网络 (DNN) 训练代理以最大化累积奖励,从而生成最佳质量函数。图 1.2 显示了框架的高级轮廓。需要注意的是,Jarvis 框架中使用的安全策略可以从 E-Spion 日志中动态获取,也可以通过离线可用的 IDS 系统的其他攻击签名获取。
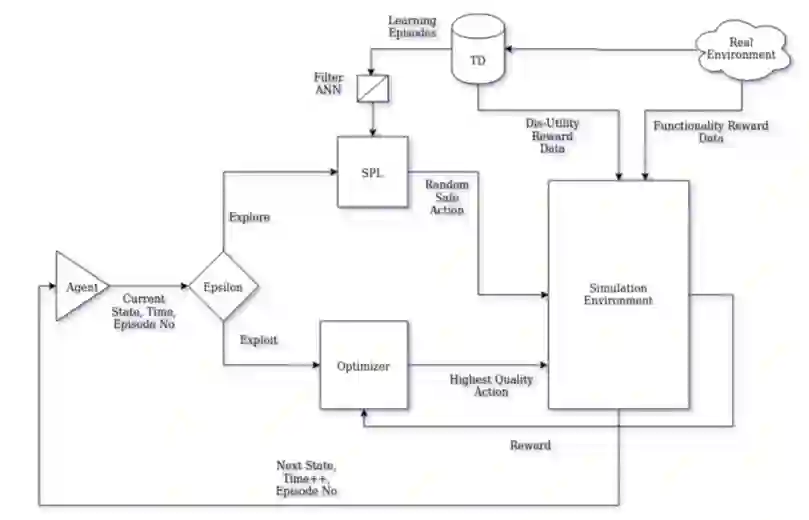
图1.2 JarvisRL框架
1.3.3 Jarvis-SDN:用于SDN环境的受限DRL框架
Jarvis-SDN 基于用于 Jarvis 的类似 RL 框架,但在网络层而不是应用层运行。 RL 框架的目标是优化网络控制。尽管网络控制有很多方面,但在本论文中,我们重点关注网络成功运行所需的两个核心网络功能组件: 1. 路由:确定从节点 A 到 B 的数据包传输路径,以最大限度地减少延迟和 2. 速率控制:确定为节点 A 和 B 之间的每个网络会话分配多少带宽或优先级以满足用户 SLA。然后将安全约束作为风险指标编码到 Jarvis-SDN 优化标准中,以保护网络控制器免受 DoS、DDoS、Brute-Force 和基于 Web 的攻击,同时学习最佳网络策略。例如,在路由方面,理想情况下,可疑的网络流(可能是 DDoS 攻击)应该通过网络上运行 DDoS IDS/IPS 的节点进行路由。在速率控制方面,在IDS/IPS能够做出准确推断之前,应该对恶意流进行节流。
1.4 论文大纲
本论文的其余部分安排如下。首先,在第 2 章中,我们回顾了为 IoT 设计的 IDS/IPS 系统,并开发了 E-Spion,这是一个专门用于 IoT 环境的基于主机的 IDS。在第 3 章中,我们定义了 Jarvis 模型,用于物联网智能家居环境中的应用层控制。在第 4 章和第 5 章中,我们分别定义了 Jarvis-SDN 模型,用于 SDN 环境中的网络层速率控制和路由。
我们的 DRL 模型 Jarvis 用于应用层控制和 Jarvis-SDN 用于网络控制的实例化需要解决一个关键挑战,即大规模应用这些技术。纯离线 RL 模型会随着模拟环境的质量下降而随规模下降。另一方面,出于显而易见的原因,以纯在线方式学习安全策略是不可行的。这是将 RL 模型应用于现实世界环境的一个基本问题。在第6 章中,我们更详细地讨论了这一挑战,并使用生成对抗网络 (GAN) 提供了解决这一挑战的方法,该网络基于在离线环境中通过在线环境中的真实探索来增强探索的方法。最后,在第7章中,我们提供了一个结论和未来工作的途径。
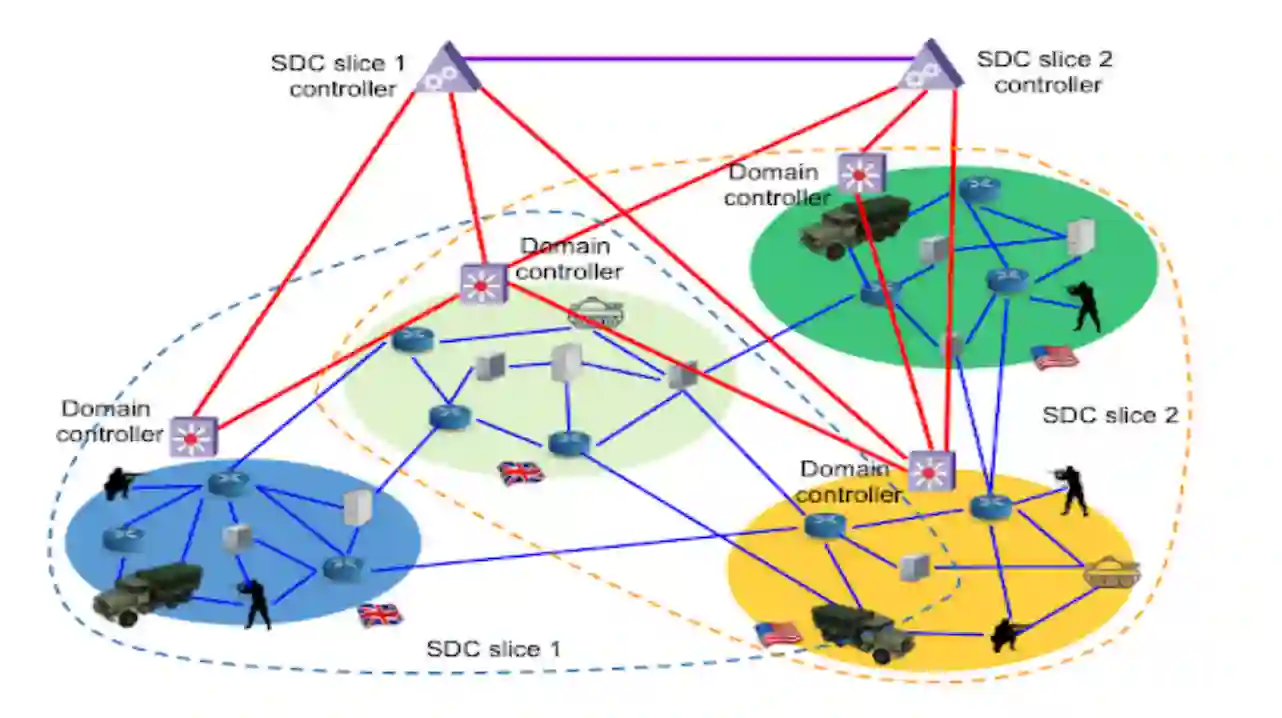
图6.1 武装部队的软件定义联盟 (SDC)



