近年来,深度学习的发展引出了能够学习数据内在表示和性质的表达方法。这种功能提供了新的机会,可以找出数据的结构模式和功能属性之间的相互关系,并利用这种关系来生成给定所需属性的结构性数据。本文对可控深度数据生成这一前景广阔的研究领域进行了系统的综述。

在目标属性下设计和生成新数据已经吸引了各种关键应用,如分子设计、图像编辑和语音合成。传统的手工制作方法严重依赖专业经验和密集的人力努力,但仍然受到科学知识的不足和低吞吐量的影响,以支持有效和高效的数据生成。近年来,深度学习的发展引出了能够学习数据内在表示和性质的表达方法。这种功能提供了新的机会,可以找出数据的结构模式和功能属性之间的相互关系,并利用这种关系来生成给定所需属性的结构性数据。本文对可控深度数据生成这一前景广阔的研究领域进行了系统的综述。首先,提出了潜在的挑战,并提供了初步建议。然后正式定义了可控深度数据生成技术,提出了可控深度数据生成技术的分类方法,总结了可控深度数据生成技术的评价指标。在此基础上,介绍了可控深度数据生成技术的重要应用,并对已有的研究成果进行了实验分析和比较。最后,指出了可控深度数据生成的未来发展方向,并指出了5个潜在挑战。
https://www.zhuanzhi.ai/paper/9ce23982a0872977f5df286c1f4f388f
数据生成是一个重要的领域,旨在捕捉数据的固有分布,以生成类似的新数据。由于其在分子设计[1-3]、图像编辑[4-6]、文本生成[7,8]和语音合成[9-11]等关键领域的广泛应用,它是一个持久、快速发展的重要领域。数据生成需要探索和操作复杂的数据结构,这在历史上导致了高成本,密集的人力,丰富的领域知识在大(通常是离散的)搜索空间。部分由于这个原因,传统的数据生成方法都是针对特定领域定制的,领域启发式规则与工程更容易得到应用[12-15]。例如,药物设计的过程,即产生新的分子结构,通常需要化学家手工制作候选结构,然后测试它们是否能带来期望的性质,如溶解度和毒性。还可以利用泛型算法等计算方法,根据领域知识[16]设计分子突变和交叉规则,对分子结构进行组合搜索。然而,分子结构空间是巨大的: 例如,现实的类药物分子的数量估计在10^33[17]左右,这给搜索和识别感兴趣的结构带来了相当大的困难。此外,在许多领域,如神经科学,电路设计,蛋白质结构,我们的领域知识仍然非常有限和不完整。对数据生成过程的缺乏理解限制了我们重新生成甚至创建具有所需属性的新数据的能力。另一个例子是逻辑电路设计,其目的是输出所需的集成电路原理图。传统的电路设计是一个相当复杂的过程,需要根据电荷的特性对电路元件的行为进行大量的数学建模[13,18],并根据不同电路器件的性质选择合适的材料[13,19]。值得注意的是,对传统数据生成技术的详细综述可以在特定的领域单独找到[13,15,20,21]。
近年来,深度学习的发展为我们解决上述数据生成方面的挑战提供了新的机遇。深度学习技术在学习图像、文本、序列和图等各种数据类型的表示方面取得了巨大的成功[22-26]。这进一步使我们能够适应从数据结构到其相应(潜在)特征的映射,其中前者通常可以是离散的和非结构化的,而后者是连续的向量或矩阵。因此,我们不需要使用昂贵的组合算法来直接探索复杂数据结构的高维空间,而是可以使用高效的算法(如基于梯度的算法)来探索数据在连续向量空间中的潜在特征。例如,蛋白质结构是由氨基酸序列形成的,因此序列数据的分布可以被序列深度学习模型(如递归神经网络(RNNs)和变压器[27])捕获和编码。然后从学习到的蛋白质结构潜在空间[28]中自回归生成新的氨基酸序列。研究表明,与Rosetta[29]等传统框架相比,基于深度学习的蛋白质设计方法获得了更大的序列多样性。此外,由于深度学习以端到端方式提取潜在特征,可以大大减少对领域知识的依赖。例如,在图像合成领域,基于深度学习的技术可以学习特定艺术家画作的潜在语义表示,并很容易地拟合其在潜在空间中的分布,因此合成同一艺术家的新画作简单地就是一个采样+解码过程[30]。另外,由于领域知识的独立性更强,基于深度学习的数据生成技术在不同数据类型或应用程序中更容易一般化或交叉使用方面具有更好的潜力。
尽管黑盒深度学习技术有望解决数据生成中的传统障碍,但如何填补学习到的潜在特征和感兴趣的真实属性之间的空白对于确保生成的数据结构和期望属性之间的对齐至关重要。在典型的现实世界应用中,生成具有所需特性的数据是事实上的先决条件,从医学设计[31,32],到电路混淆[33],到艺术设计[34,35],再到音频合成[36,37]。例如,化学家不仅可以生成新型季铵盐化合物(QACs),还希望生成的QACs在水中具有强溶解性,最低抑菌浓度(MIC)小于4mg/L,以确保抗菌性[38]。图像描述社区可能期望从长度小于10个单词的图像中以幽默的风格生成更多类似人类的文本[39,40]。因此,为了解决深度学习技术产生的数据属性控制这一核心问题,近年来可控深度数据生成的需求和研究主体快速增长[1,6,41 - 43]。
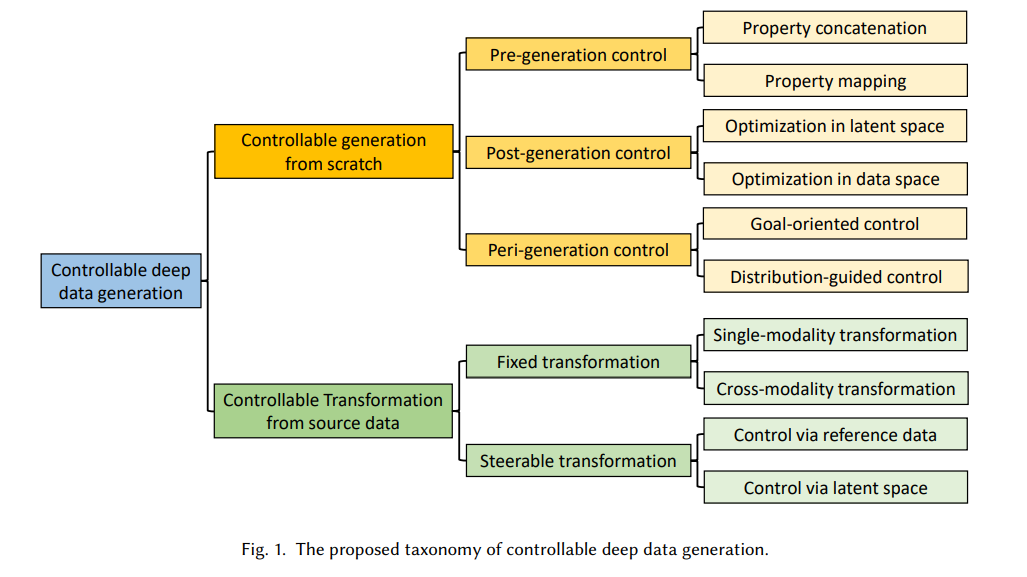
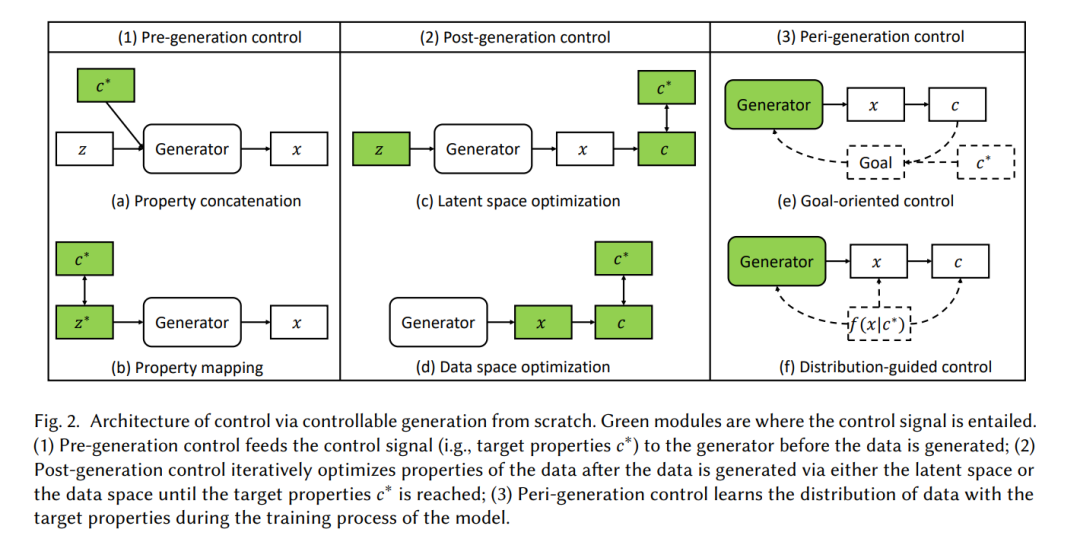
迄今为止,已有相当多的研究致力于可控深度数据生成,以应对上述挑战。为了推进最先进的技术和预见潜在的研究机会,全面了解现有工作的优势和弱点是很重要的。此外,在控制不同领域的数据生成方面也有广泛的兴趣。虽然大多数提出的方法都是针对单个应用领域设计的,但将它们的技术推广到其他应用领域是有益的,也是可能的。因此,交叉引用这些服务于不同应用领域的方法是困难的,需要加以解决。此外,可控的深度数据生成结果的质量要求在各个应用领域专门设计评价策略。因此,我们需要对不同领域的不同评价策略进行系统的标准化和总结。此外,人工智能(AI)科学家正在寻找新的可用数据集来测试他们的可控深度数据生成模型,而特定领域的社区正在寻找更强大的控制技术来生成具有期望属性的复杂结构化数据,鉴于这两方面的需求不断增长,对现有可控深度数据生成技术的系统综述限制了双方数据生成的进展。为了填补这一空白,本研究旨在通过对可控深度数据生成技术的系统综述,帮助跨学科研究人员了解可控深度数据生成的基本原理,选择合适的技术解决相关领域的问题,并以标准化的评估场景推进研究前沿。这项综述的主要贡献总结如下:
-
对现有技术进行系统的总结、分类和比较。根据可控深度数据生成过程的触发方式,对现有可控深度数据生成技术进行了全面的分类,形成了新的分类框架。讨论并比较了该分类法不同子类别的技术细节、技术优缺点。这种分类法的提出是为了使来自不同应用领域的研究人员能够定位最适合他们需要的技术。
-
标准化的评估指标和流程。从历史上看,数据生成方法和它们的评估通常是针对单个领域定制的,尽管它们有共同的抽象问题和目标,但并没有很好地统一。针对这一问题,本文总结了可控深度数据生成的常用评价指标和流程,并从生成数据质量和属性可控性两个角度对其进行标准化。
-
对主要应用进行全面的分类和总结。对分子合成与优化、蛋白质设计、图像编辑、情感语音生成等主要应用进行了全面的介绍和总结。本文比较并充分讨论了应用于这些应用领域的各种技术。对这些主要应用的全面分类和总结,将有助于人工智能研究人员探索广泛的应用领域,并指导这些领域的研究人员使用适当的技术生成数据。
-
对现有基准数据集进行系统综述,并对现有技术进行实证比较。根据不同的数据模式,系统地总结了各应用领域借鉴的基准数据集。此外。实验结果由我们和同行评议的文章进行,以比较在这些基准数据集上生成可控深度数据的代表性模型。对现有基准数据集的系统综述和代表性技术的实证比较将使模型开发人员能够使用额外的数据集来评估他们的模型,并将他们提出的模型的性能与基准结果进行比较。
-
对当前的研究现状和潜在的未来方向进行了深刻的讨论。本文通过对可控深度数据生成技术、标准化评价指标、广泛的应用范围、基准数据集的系统回顾和现有技术的实证比较,对该领域存在的几个问题提出了深刻的见解,并展望了该领域未来的发展方向。
在第一部分中,我们首先介绍了可控深度数据生成的背景、挑战、我们的贡献、我们的综述与现有综述的关系。然后在第2节中,我们将介绍用于深度数据生成的通用框架作为初步介绍。接下来,我们正式阐述了可控深度数据生成问题(章节3.1),并在章节3中根据各种属性控制技术(章节3.2)提出了分类方法,然后在同一章节中总结了评价指标。在第4节中,我们介绍了可控深度数据生成的技术,并根据我们的分类,详细解释了从无开始可控生成(第4.1节)和从源数据可控转化(第4.2节)的概念和代表工作。在第5节中,我们将展示在4.1节和4.2节中回顾的模型在各种领域特定任务中的应用,然后介绍这些领域中使用的流行数据集。此外,在第6节中,我们对常用的分子、图像、文本和音频数据集进行了实验比较和分析,用于可控的深度数据生成。在后面的第7节中,我们将介绍该领域的潜在挑战、机会和现有方法的局限性。我们将在第8部分结束我们的综述。