小数据如何学习?吉大最新《小数据学习》综述,26页pdf涵盖269页文献阐述小数据学习理论、方法与应用
吉大最新《小数据学习》综述,26页pdf涵盖269页文献阐述小数据学习理论、方法与应用,非常值得关注!

对大数据的学习为人工智能(AI)带来了成功,但注释和训练成本昂贵。未来,在小数据上学习是AI的最终目的之一,这需要机器像人类一样识别依赖小数据的目标和场景。一系列的机器学习模型正在以这种方式进行,如主动学习、少样本学习、深度聚类。然而,几乎没有理论保证它们的泛化性能。而且,它们的大多数设置都是被动的,即标签分布是由一个指定的采样场景显式控制的。该调查遵循PAC (Probably Approximately Correct)框架下的不可知论主动抽样,使用监督和非监督方式分析小数据学习的泛化误差和标签复杂性。通过这些理论分析,我们从两个几何角度对小数据学习模型进行了分类: 欧几里得和非欧几里得(双曲)均值表示,并给出了它们的优化解。随后总结了一些可能受益于小数据学习的潜在学习场景,并对其潜在的学习场景进行了分析。最后,一些具有挑战性的应用,如计算机视觉,自然语言处理,可能受益于学习小数据也被综述。
https://www.zhuanzhi.ai/paper/b3a7fa03007ee5e7246b7b277e8b2912
“那是一只猫在床上睡觉,男孩在拍大象,那些是要坐飞机的人,那是一架大飞机……”李飞飞说:“这是一个三岁的孩子在描述她看到的图片。”2015年1月,她在科技娱乐设计(TED)上发表了一篇著名的演讲“我们如何教计算机理解图片”。在现实世界中,人类可以根据自己的先验知识,只依靠一张图片来识别目标和场景。然而,机器可能需要更多。在过去的几十年里,人工智能(AI)[1][2]技术通过学习大数据[3][4],帮助机器变得像人类一样聪明。通过对人类大脑神经元的传播进行建模,构建了一系列具有表现力的AI系统,如深蓝[5],AlphaGo[6]。当然,人工智能的天赋不是天生的。大数据训练有助于人工智能识别不同的目标和场景。在处理大数据方面,采用MapReduce[7]、Hadoop[8]等技术访问大规模数据,提取对AI决策有用的信息。具体来说,MapReduce分布在多个异构集群上,Hadoop通过云提供商处理数据。然而,尽管我们采用了这些大数据处理技术,但对大规模数据进行训练和注释的成本相当高。
一种新颖的观点认为,小数据革命正在进行,对小数据进行训练,使其具有预期的性能是人工智能的最终目的之一。从技术上讲,人类专家希望缓解对大数据的需求,为AI系统找到新的突破,特别是深度神经网络[9]的配置。相关工作包括有限标签[10][11]、较少标签[12][13][14]、较少数据[15][16]等,已经被低资源深度学习研究者实现。在形式上,少样本学习[17]被称为低资源学习(low-resource learning),是一个以有限信息研究小数据的统一课题。基于Wang等人的综述[18],少样本学习的一个显式场景是特征生成[19],即根据给定的有限或不足的信息生成人工特征。另一种具有隐式监督信息的场景更具挑战性,它依赖于用那些高信息量的样例(如私人数据)对学习模型[19][20]进行再训练。理论上,大多数的少样本学习场景是被动的,即标签分布是由一个指定的抽样场景显式控制的。因此,主动学习[21]吸引了我们的眼睛,其中标签获取是由学习算法或人类控制的。
与少样本学习不同,主动学习的注释场景没有那么有限。主动学习算法可以随时停止迭代采样,因为算法性能不理想,或者注释预算耗尽。主动学习有两类: 假设类[22]上的主动抽样理论和实现场景[23]上的主动抽样算法,其中理论研究给出了这些算法范式的标签复杂性和收敛性保证。典型的理论分析来自PAC ((Probably Approximately Correct))[24]风格,它针对诸如[25]这样的不可知论设置。为了控制主动采样,存在一种搜索目标数据的误差不一致系数,该系数能最大限度地提高假设更新,其中这些更新要求是积极的、有帮助的。因此,主动抽样也是一个假设剪枝[26]的过程,它试图从给定的假设类中找到最优假设,其中假设从版本空间[27][28]维持到类的决策边界[29]。在几何上,封闭类的版本空间通常嵌入在一个管状结构[30][31]中,该管状结构与球面类具有同胚拓扑。
对小数据的学习对于推进人工智能至关重要。少样本学习作为一个先行课题,对有限数据训练进行了探索。而少样本学习的设置是一个被动的场景,任务本身规定的标签信息不足。同时,它的泛化性能几乎没有理论保证。这促使我们对小数据的学习进行理论分析。利用主动抽样理论,我们遵循PAC框架提出了一组用于小数据学习的误差和标签复杂性边界。为了总结这些算法范式,我们然后将小数据学习模型分为:欧几里得和双曲(非欧几里得)表示,包括它们的深度学习场景。具体地说,这项综述的贡献总结如下。
我们提出了小数据学习的形式化定义。该定义是一个模型无关的设置,从机器学习的角度派生出一个更一般化的概念。
从PAC的角度来看,我们首先提出了通过主动抽样理论学习小数据的理论保证。给出了小数据学习的泛化误差和标签复杂度界。
从几何的角度,我们将小数据学习模型分为两类:欧几里得表示和双曲表示,其中它们的优化求解器进行了分析。
我们调研了一些学习小数据的新方向,为潜在的学习场景和现实世界的挑战应用。
本综述的其余部分安排如下。第2节介绍了小数据学习的相关文献,包括少样本学习和主动学习。第3节给出了关于小数据学习的正式定义,并给出了它的PAC分析,包括标签复杂度和泛化误差边界。第4节从几何角度介绍了学习小数据的欧几里得和非欧几里得范式,第5节介绍了相关的优化求解器。之后,第6节讨论了学习小数据表示的潜在场景,第7节介绍了具有挑战性的场景。然后,第8节介绍一些关于小数据的有趣应用。第9部分是本次综述的最后结论。
小数据学习方法
随着对小数据学习需求的不断增加,我们探索在未来不同的方向上促进小数据表示的模型学习,包括迁移学习、元学习、强化学习、对比学习和图表示学习等。在本节中,我们将介绍这些学习主题,并解释在小数据上学习的潜力。
基于小数据的迁移学习
大多数机器学习理论都基于一个共同的假设:训练数据和测试数据遵循相同的分布。然而,这种假设过于严格,无法满足,或者在许多现实场景中可能不成立。迁移学习[116]摆脱了这一假设的约束(即训练和测试数据可以来自不同的分布或域),其目的是挖掘不同域之间的域不变特征和结构,从而进行有效的数据和知识迁移。迁移学习是利用从源领域学习到的知识来提高模型在目标领域的能力,如将骑自行车的知识转移到开车的知识。

基于小数据的元学习
传统的机器学习模型通常是在特定任务的专属数据集上进行训练的,这就造成了泛化能力差的问题,即学习模型很难适应以前从未见过的任务。为了克服这一困难,元学习[121]利用广泛的元知识,例如在各种学习任务中调整学习参数,来教学习模型学习看不见的任务。

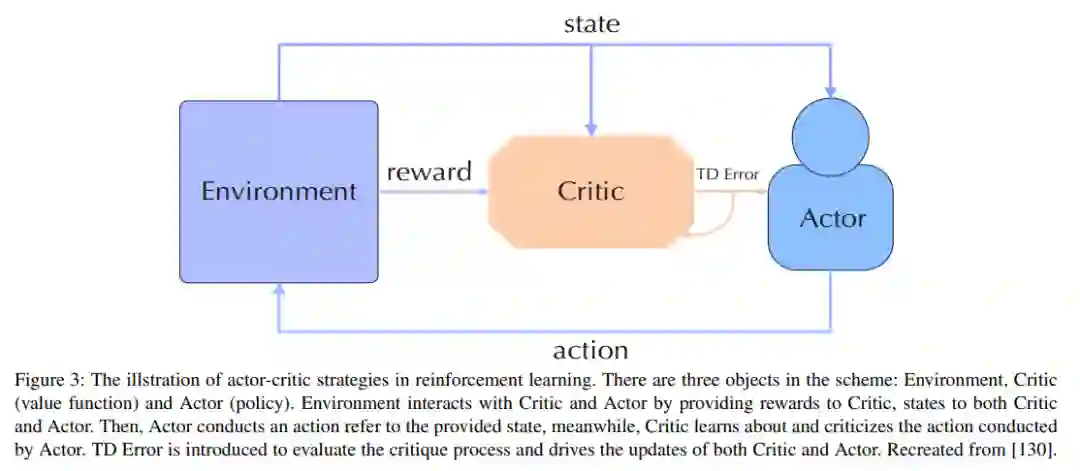
小数据的强化学习
强化学习[135]是一种强调通过奖励预期行为和/或惩罚意外行为来最大化预期收益的人工智能范式。在强化学习中,存在两个相互作用的对象:Agent和Environment。Agent可以感知环境的状态,并对环境的反馈进行奖励,从而做出合理的决策。也就是说,Agent的决策函数根据环境的状态采取不同的行动,而学习函数根据环境的奖励来调整策略,环境可以在Agent的行为的影响下调整自己的状态,并将相应的奖励反馈给Agent。
小数据对比学习
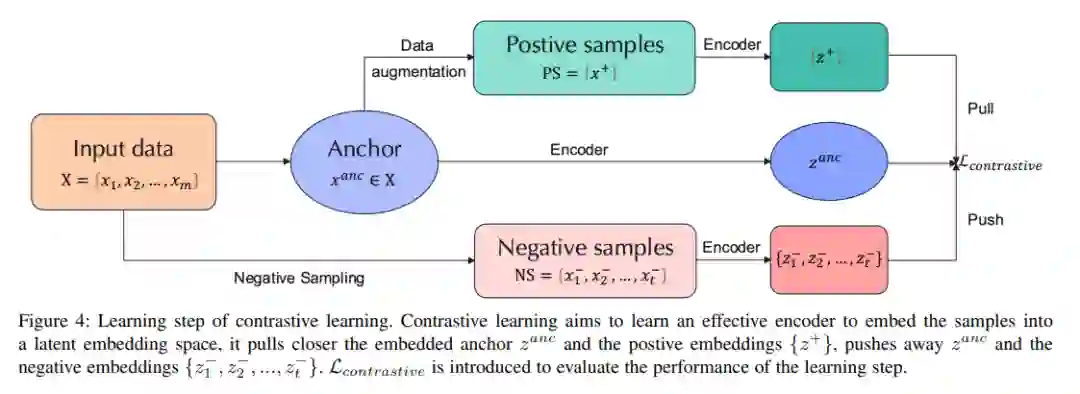
自监督学习[153]由于能够避免标注大规模数据集的成本而受到关注。它主要利用前置任务从无监督数据中挖掘监督信息。利用构建的监督信息,我们可以进行模型学习,获得对下游任务有价值的表示。与此同时,对比学习[154]、[155]、[156]、[157]、[158]最近成为自监督学习中的一个重要子课题,其目的是学习一种表示法,该表示法可以将具有对比损失的正对组合得更近,并将负对推离潜在嵌入空间。图4展示了对比学习中的一个学习步骤。
小数据的图表示学习
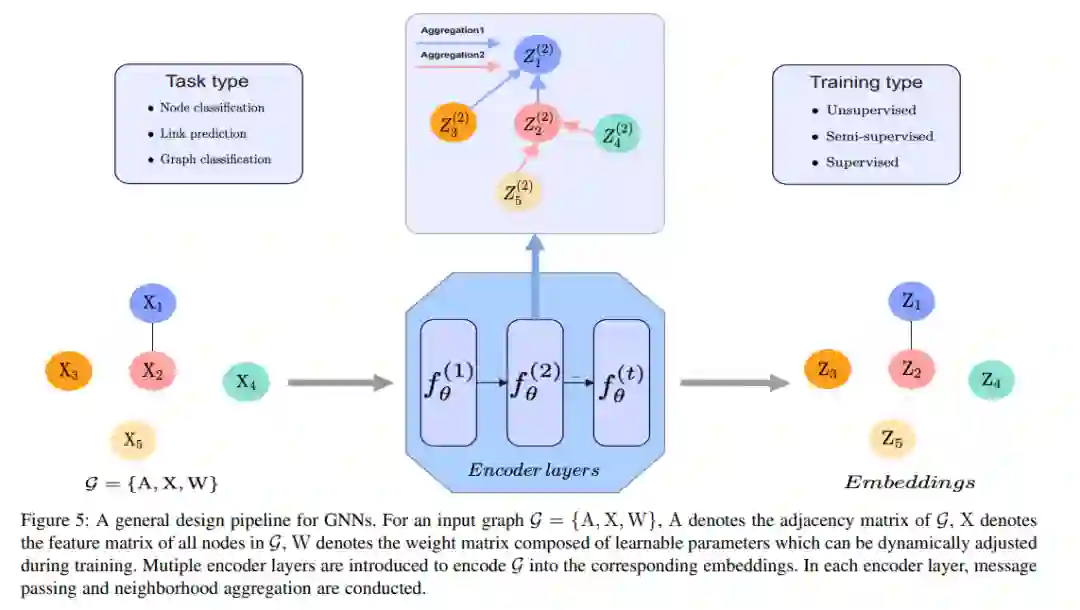
图是一种常用的数据结构,用于描述社交网络、推荐系统等复杂系统。在过去的几年中,由于图的强大表达能力,图表示学习[163]逐渐引起了机器学习界的关注,它旨在建立能够从非欧几里得数据中高效学习的模型。与此同时,各种图神经网络[164]应运而生,它们在结构化数据挖掘任务中显示出巨大的潜力,如节点分类、链接预测或图分类等。然而,当这些图数据挖掘任务遇到许多无监督/有监督的场景,其中很少,甚至没有有效的数据或标签存在,如何提高这些任务在图上的性能,并在这些情况下获得一个鲁棒的模型?同时,图神经网络的关系结构发现[165]、[166]、[167]、表征能力[168]等有意义的子主题也有待探索,从数据表示的角度来看,可能也需要有效的思路。针对上述问题,对小数据的学习可以提供必要和强大的支持,由于其可观的数据发现效率和较强的表示能力,可以促进图表示学习的发展。特别地,图5给出了GNN的一般设计流程。在该设计流程的方案下,GNN可分为递归图神经网络、卷积图神经网络、图自编码器和时空图神经网络。分类的详细描述如下[164]。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SDL” 就可以获取《小数据如何学习?吉大最新《小数据学习》综述,26页pdf涵盖269页文献阐述小数据学习理论、方法与应用》专知下载链接


