【导读】聚类是机器学习的一项基本任务。深度学习的发展催生了深度聚类。来自浙江大学等学者发布了关于深度聚类的最新综述论文,35页pdf涵盖246篇文献概述了深度聚类的概念、方法、体系与应用,值得关注!

聚类是一种基本的机器学习任务,在文献中得到了广泛的研究。经典的聚类方法遵循这样的假设:通过各种表示学习技术,数据被表示为向量化的特征。随着数据变得越来越复杂和复杂,浅层(传统)聚类方法不再能够处理高维数据类型。随着深度学习,尤其是深度无监督学习的巨大成功,在过去的十年中,许多具有深度架构的表示学习技术被提出。融入深度学习好处的一种直接方法是,在将其输入浅层聚类方法之前,首先学习深度表示。然而,这是次优的,因为: 1) 表示不是直接学习的聚类,限制了聚类性能;(2)聚类依赖于实例间的复杂关系而非线性关系;3)聚类和表示学习是相互依赖的,应该相互促进。为了应对上述挑战,深度聚类(Deep Clustering)的概念被提出,即联合优化表征学习和聚类,因此受到越来越多的关注。基于深度学习在聚类(最基本的机器学习任务之一)中的巨大成功,以及该方向最近的大量进展,本文通过提出不同最新方法的新分类,对深度聚类进行了全面的调研。我们总结了深度聚类的基本组成部分,并通过设计深度表示学习和聚类之间的交互方式对现有方法进行分类。此外,该综述还提供了流行的基准数据集、评估指标和开源实现,以清楚地说明各种实验设置。最后,我们讨论了深度聚类的实际应用,并提出了值得进一步研究的具有挑战性的主题作为未来的方向。
https://www.zhuanzhi.ai/paper/c46ee4cd4877641a916a18dd389c017e
聚类是机器学习中的一个基本问题,也是许多数据挖掘任务中的一个重要预处理步骤。聚类的主要目的是将实例分配到组中,使相似的样本属于同一个集群,而不同的样本属于不同的集群。样本的聚类提供了数据实例的全局表征,可以显著地促进对整个数据集的进一步分析,如异常检测[166,201]、域适应[180,240]、社区检测[121,178]和鉴别表示学习[133,164,214]等。
虽然浅聚类方法已经取得了巨大的成功,但它们假设实例已经在一个具有良好形状的潜在矢量空间中表示。随着过去几十年互联网和web服务的快速发展,研究人员对发现新的机器学习模型越来越感兴趣,这些模型能够处理没有明确特征的非结构化数据,如图像,以及具有数千维的高维数据等。因此,浅聚类方法不能再直接用于处理此类数据。近年来,深度学习的表示学习取得了成功,特别是在非结构化和高维数据中[166,201]。然而,在聚类过程中并没有探索深度学习技术。由于不能很好地捕捉到实例间复杂的关系,导致聚类结果欠佳。
为了解决这一问题,深度聚类(Deep Clustering)技术应运而生,它旨在将深度表示学习和聚类联合优化。更具体地说,深度聚类方法关注以下研究挑战:(1)如何学习能够产生更好聚类性能的判别表示?(2)如何在一个统一的框架下高效地进行聚类和表示学习?(3)如何打破聚类和表示学习之间的壁垒,使它们以交互迭代的方式相互增强?
为了解决上述挑战,已经提出了许多具有不同深度架构和数据类型的深度聚类方法。受聚类(最基本的机器学习任务之一)中深度学习的巨大成功以及该方向最近取得的大量进展的激励,本文通过提出各种最新方法的新分类,对深度聚类进行了全面的调研。
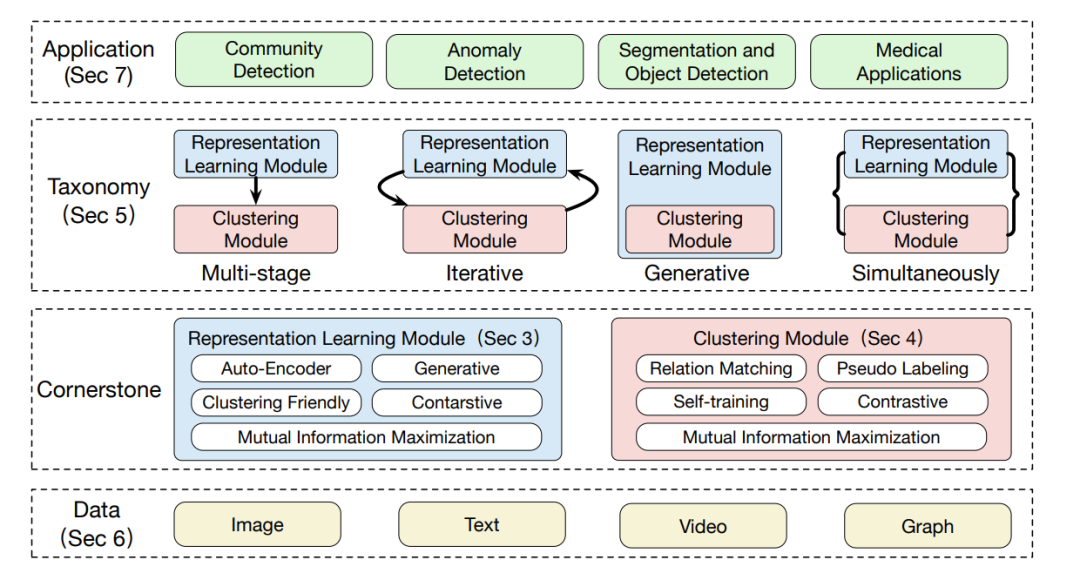
综上所述,本文旨在从以下几个方面为潜在读者理解深度聚类全景图提供支持:
-
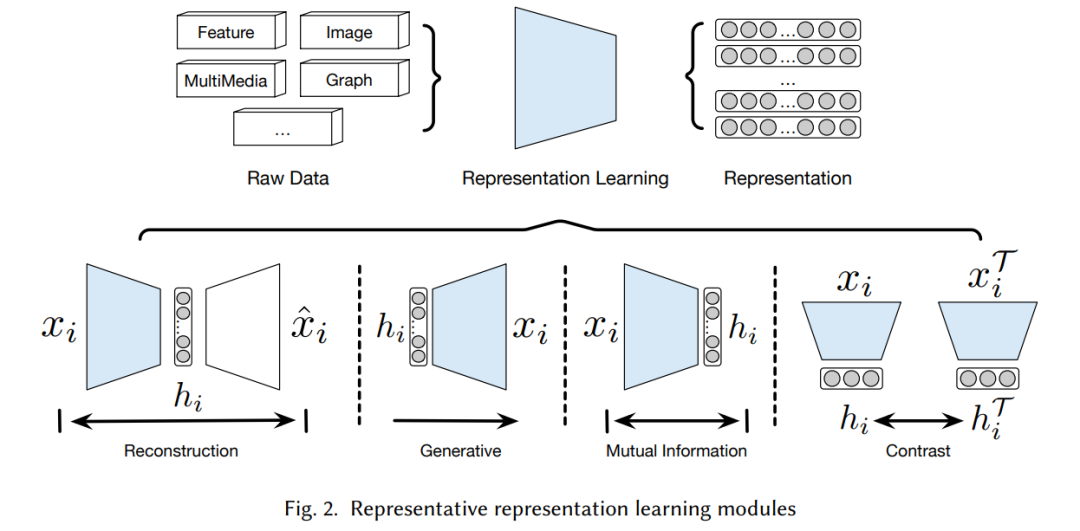
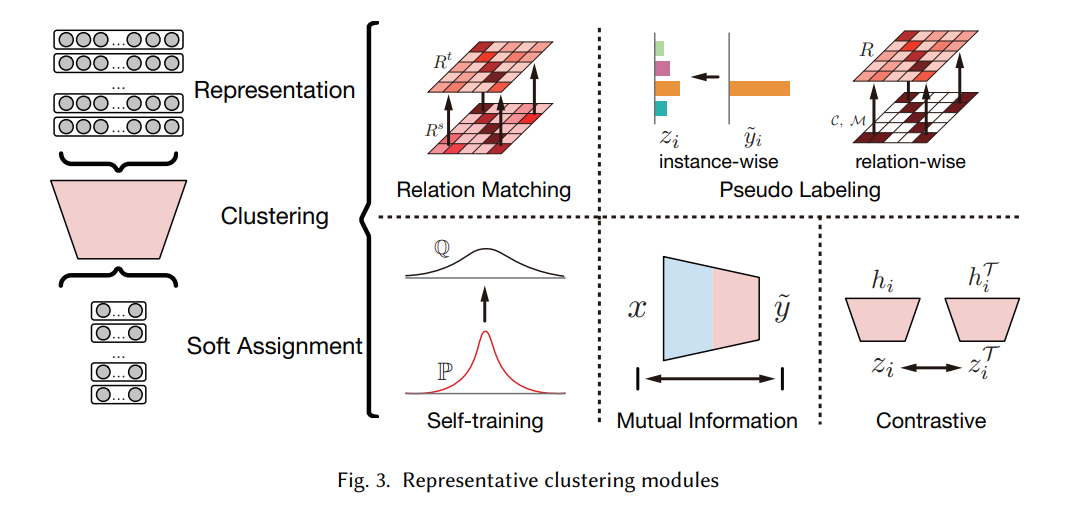
深度集群的基石。我们总结了深度聚类的两个基础模块,即表示学习模块和聚类模块。对于每个模块,我们强调了从现有方法中总结出的具有代表性和通用性的设计,这些设计很容易推广到新的模型中。
-
系统的分类。基于表示学习模块和聚类模块之间的交互方式,我们对现有的深度聚类方法进行了系统的分类,提出了四个具有代表性的方法分支。我们还在不同的场景中比较和分析每个分支的属性。
-
丰富的资源和参考资料。我们收集了各种类型的基准数据集、评估指标和深度聚类最新论文的开源实现,这些数据与Github (1.8K Star)上的参考文献一起组织。
-
未来的发展方向。基于表示学习模块和聚类模块的特性及其相互作用,我们讨论了现有方法的局限性和挑战,并对未来值得研究的有前景的研究方向提出了自己的见解和想法。
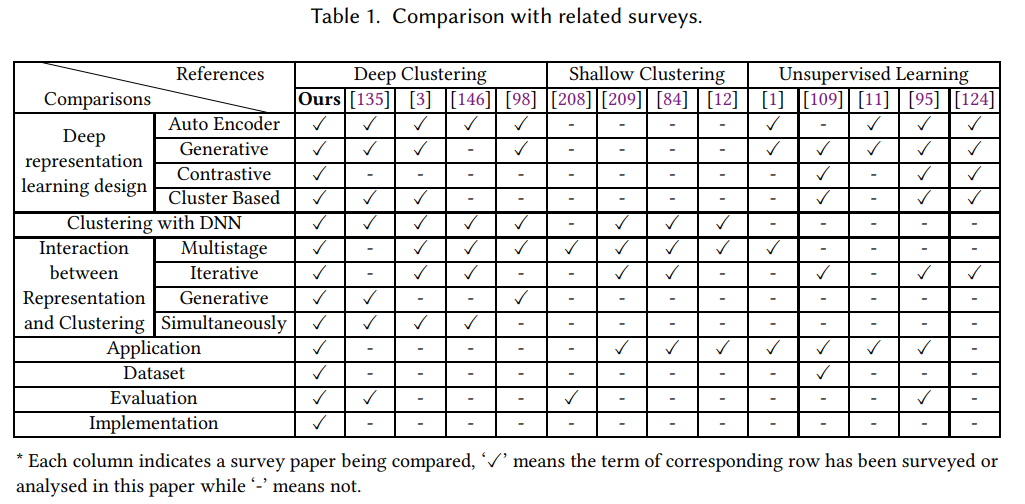
在这个调研中,我们关注深度学习技术的聚类,特别是深度表示学习和深度神经网络聚类之间的相互作用。对于其他基础研究问题,如初始化聚类、自动识别聚类数量等,我们在第8节中进行了讨论,并将其留待以后的工作。关于浅聚类、深聚类和表示学习的调研比较见表1。