扩散模型是近年来快速发展并得到广泛关注的生成模型。它通过一系列的加噪和去噪过程,在复杂的图像分布和高斯分布之间建立联系,使得模型最终能将随机采样的高斯噪声逐步去噪得到一张图像。来自西湖大学李子青等学者发布了关于《扩散模型》综述论文,对扩散模型的现状进行详细的综述。通过对改进算法和在其他领域的应用进行分类。值得关注!
最近大火的“扩散模型”首篇综述来了!北大最新《扩散模型:方法和应用》综述,23页pdf涵盖200页文献

A Survey on Generative Diffusion Model Hanqun Cao, Cheng Tan, Zhangyang Gao, Guangyong Chen, Pheng-Ann Heng, Senior Member, IEEE, and Stan Z. Li, Fellow, IEEE 由于深度潜在表示,深度学习在生成任务中显示出巨大的潜力。生成模型是一类可以根据某些隐含参数随机生成观察结果的模型。近年来,扩散模型以其强大的生成能力成为生成模型的一个新兴门类。如今,已经取得了巨大的成就。除了计算机视觉、语音生成、生物信息学和自然语言处理外,该领域还将探索更多的应用。然而,扩散模型有其生成过程缓慢的天然缺陷,导致许多改进的工作。本文对扩散模型的研究领域进行了综述。我们首先阐述两项标志性工作的主要问题,DDPM及DSM。然后,我们提出了一系列先进的技术来加速扩散模型——训练计划、无训练采样、混合建模以及得分与扩散的统一。对于现有的模型,我们还根据具体的NFE提供了FID score, IS, NLL的基准。此外,还介绍了扩散模型的应用,包括计算机视觉、序列建模、音频、科学人工智能等。最后,对该领域的研究现状进行了总结,指出了研究的局限性和进一步的研究方向。
https://www.zhuanzhi.ai/paper/1fee483da0347749193cb9e6848254cc
我们如何赋予机器与人类一样的想象力? 深度生成模型,如VAE[1]、[2]、[3]、[4]、EBM[5]、[6]、[7]、[8]、[9]、[10]、[11]、[12]、[13]、[14]、[15]、[16]、[17]、[18]、[19]、[20]、[21]、GAN[22]、[23]、[24]、标准流模型[25]、[26]、[27]、[28]、[29]、[30]和扩散模型[31]、[32]、[33]、[34]、[35],在创造人类无法正确区分的新模式方面显示出巨大潜力。我们专注于基于扩散的生成模型,该模型不需要像VAE那样调整后验分布,不需要像EBM那样处理难以处理的配分函数,不需要像GAN那样训练额外的鉴别器,也不需要将网络约束作为归一化流。由于上述优点,基于扩散的方法已经引起了从计算机视觉、自然语言处理到图形分析的广泛关注。然而,目前对扩散模型的研究进展还缺乏系统的分类和分析。
扩散模型的发展为模型的描述提供了可跟踪的概率参数化,为训练过程的稳定提供了充分的理论支持,为损失函数的统一设计提供了简单的方法。扩散模型的目的是将先验数据分布转化为随机噪声,然后逐步对变换进行修正,重建一个与先验[36]分布相同的全新样本。近年来,扩散模型在计算机视觉(CV)[31]、[37]、生物信息学[38]、[39]、语音处理[40]、[41]等领域显示出了其精妙的潜力。例如,去噪扩散GAN生成的高分辨率伪图像只需要四个采样步骤就能击败GAN[42]。Luo等人[33]首先利用蛋白质特征上的DDPM在原子分辨率上生成抗体CDR序列和结构。Wavegrad[43]生成高保真音频样本,具有恒定的生成步骤,优于现有的基于GAN的音频生成模型。受扩散模型在CV、生物信息学和语音处理领域的成功启发,将扩散模型应用于其他领域的生成相关任务将是开发强大的生成能力的有利途径。
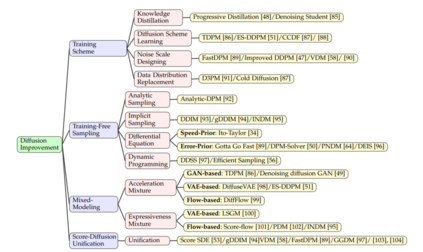
另一方面,与生成对抗网络(GANs)和变分自编码(VAEs)相比,扩散模型具有采样步骤多、采样时间长等固有缺陷。这是因为利用马尔可夫核的扩散步骤只需要很小的扰动就可以得到大量的扩散。同时,可处理模型在推理过程中需要相同的步骤数。因此,从随机噪声中采样需要数千步,直到它最终变成类似于先验的高质量数据。因此,在提高采样质量[47],[48],[49]的同时,加快扩散过程是很多工作的目标。例如,DPM求解器利用ODE的稳定性在10步[50]内生成最先进的样本。ES-DDPM[51]成功地将轨迹学习与变分自编码器相结合,实现了对扩散模型的高速采样。部分受到Bao等人[50]的启发,我们将扩散模型的改进工作总结为5类。(1)训练时间表,(2)高级无训练抽样,(3)混合生成建模,(4)分数与扩散统一。详细内容见第3节。
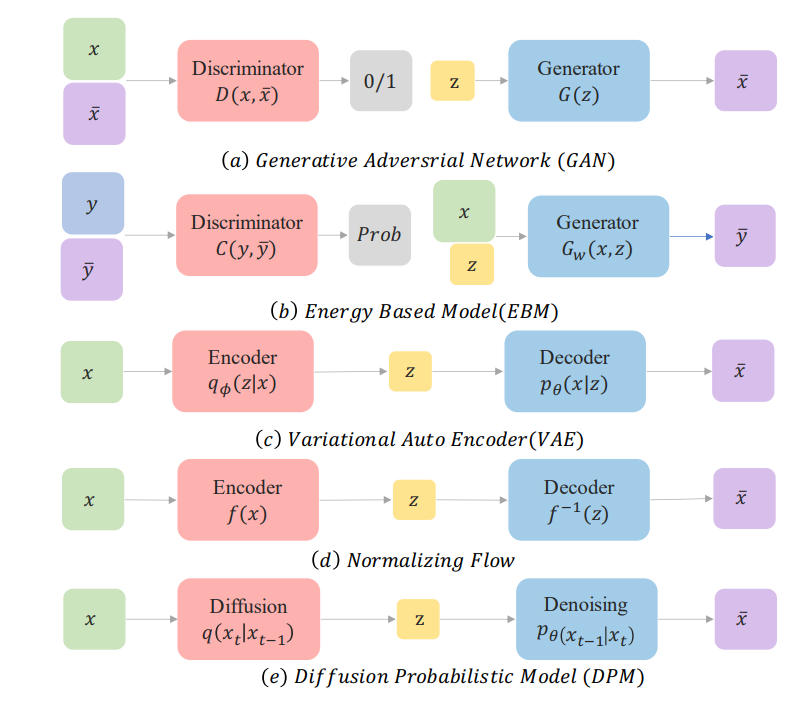
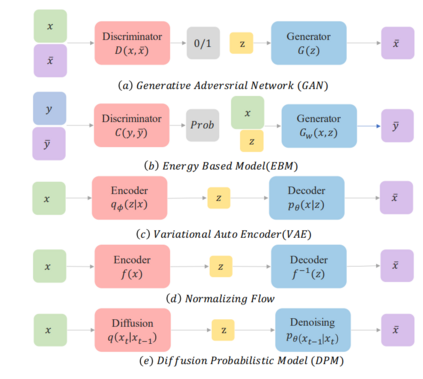
图1所示。在这个图中,我们为每一类生成模型提供了一个直观的机制。(a) 生成式对抗网络(Generative Adversarial Net, GAN)[44]在生成器上运用了对抗训练策略,使其生成的样本不能被真假鉴别器和先验鉴别器区分。(b) 基于能量的模型(EBM)[45]以类似的方式训练,它找到一个由softmax鉴别器和先验输入发生器组成的合适的能量函数,这样它可以输出随机输入的最佳匹配样本。(c) 变分自动编码器(VAE)[46]应用编码器将先验投影到一个潜在空间,从中解码器可以采样。(d) 归一化流量(NF)[29]采用了一个设计良好的可逆流量函数,将输入转化为潜在变量,然后用流量函数的倒数返回样本。(e) 扩散模型逐渐向原始数据注入噪声,直到转向已知的噪声分布,再对采样步骤中的每一步进行反转。
因此,基于扩散模型的广泛应用以及算法改进的多角度思考,我们旨在对扩散模型的现状进行详细的综述。通过对改进算法和在其他领域的应用进行分类,本文的核心贡献如下:
-
总结了扩散模型领域基本算法的本质数学公式和推导,包括方法公式、训练策略和抽样算法。
-
本文对改进扩散算法进行了全面和最新的分类,并将其分为五类: 蒸馏、噪声/轨迹学习、高级免训练采样、混合生成建模和评分与扩散统一。
-
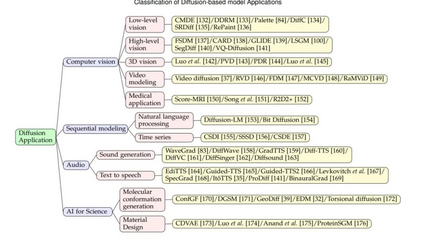
提供关于扩散模型在计算机视觉、自然语言处理、生物信息学和语音处理方面的应用的广泛陈述,包括领域专用问题公式、相关数据集、评估指标、下游任务以及基准集。
-
阐明扩散模型领域现有模型的局限性和可能进一步证明的方向。
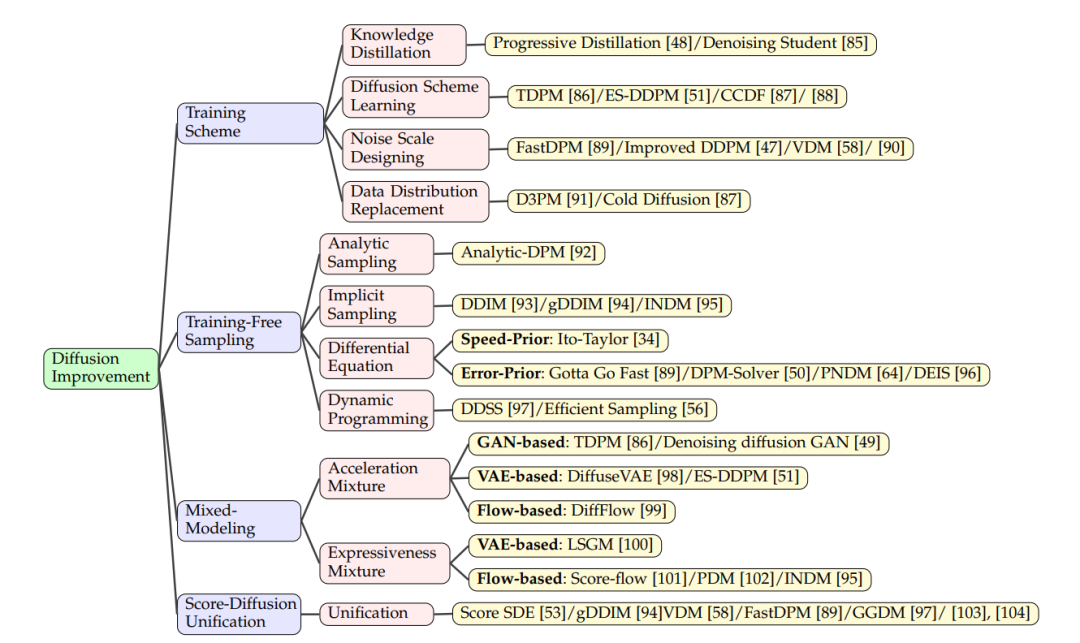
借助强条件设置,只需[48]几步就可以实现扩散采样,如文本到语音[83]和图像超分辨率[84]。一般情况下,扩散模型需要数千个步骤才能生成高质量的样本。以提高采样速度为主要内容,从不同方面进行了许多工作。在本节中,我们将它们分为5类(如表2所示),并分别给出详细的陈述。
扩散模型应用
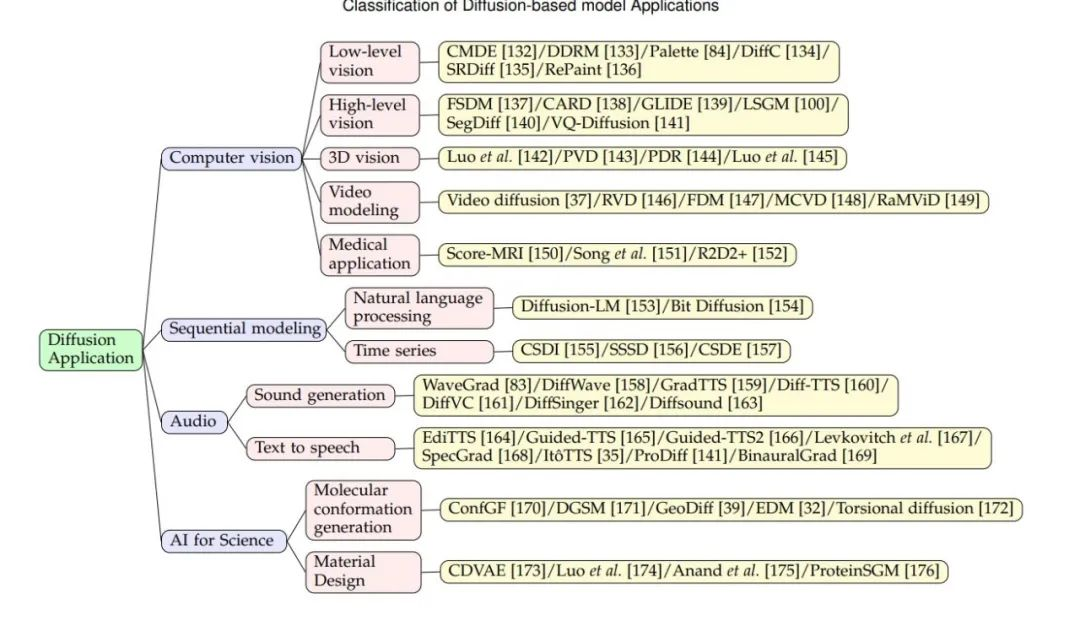
结论扩散模型正成为广泛应用领域的热门课题。为了充分利用扩散模型的威力,本文对扩散模型的几个方面进行了全面和最新的回顾,详细分析了各种姿态,包括理论、改进的算法和应用。希望本研究能对扩散模型增强和模型增强起到一定的指导作用。本节从算法和应用的角度提出了一些预期的方向。一方面,应该对不同的数据类型进行更多的尝试,包括离散空间、去量化空间和潜在空间。此外,为了扩大扩散模型的多样性,还需要探索不同的最终态噪声类型和扰动核,如正态分布、伯努利分布、二项分布和泊松分布。此外,明确的损失优化机制和加速与质量的权衡,将带来有前景的影响,可控调控和更令人满意的性能。另一方面,为了获得更好的生成性能,扩散模型在各个领域都得到了应用。然而,目前的大多数应用还停留在表面。预计会有更多针对特定问题的扩散模型,特别是针对科学问题。