
深度生成建模是一类训练深度神经网络对训练样本分布进行建模的技术。
研究已经分成了各种相互关联的方法,每一种方法都进行了权衡,包括运行时、多样性和体系结构限制。
特别是,本综述涵盖了基于能量的模型、变分自编码器、生成对抗网络、自回归模型、规格化流,以及许多混合方法。这些技术是在一个单一的内聚框架下绘制的,比较和对比来解释每种技术背后的前提,同时回顾当前最先进的进展和实现。
引言
使用神经网络的生成式建模起源于上世纪80年代,目的是在没有监督的情况下学习数据,可能为标准分类任务提供好处。这是因为收集无监督学习的训练数据自然要比收集标记数据花费更少的精力和成本,但仍然有大量可用的信息表明生成模型对于各种各样的应用是至关重要的。
除此之外,生成模型有很多直接的应用;最近的一些工作包括图像生成:超分辨率,文本到图像和图像到图像转换,修复,属性操作,姿态估计; 视频:合成与重定向;音频:语音和音频合成;文本:生成、翻译;强化学习;计算机图形学:快速渲染、纹理生成、人物运动、液体模拟;医学:药物合成、方式转换;密度估计;数据增加;特征生成。
生成模型的核心思想是训练一个生成模型,其样本x ~ pθ(x )来自与训练数据分布相同的分布,x ~ pd(x)。第一个神经生成模型,即基于能量的模型,通过在与似然成比例的数据点上定义能量函数来实现这一点,然而,这些模型难以缩放到复杂的高维数据,如自然图像,并且在训练和推理过程中都需要蒙特卡罗马尔可夫链(MCMC)采样,这是一个缓慢的迭代过程。近年来,人们对生成模型重新产生了兴趣,总的来说,这是由于大型免费数据集的出现,以及通用深度学习架构和生成模型的进步,在视觉保真度和采样速度方面开辟了新领域。在许多情况下,这是通过使用潜在变量z来实现的,这很容易从样本和/或计算密度,而不是学习p(x, z);这就需要对未观察到的潜在变量进行边缘化,然而,一般来说,这很难做到。因此,生成模型通常会在执行时间、架构或优化代理功能方面进行权衡。选择优化的对象对样本质量有重要影响,直接优化可能性往往导致样本质量显著低于替代函数。
有许多综述论文关注于特定的生成模型,如归一化流[108],[157],生成对抗网络[60],[219]和基于能量的模型[180],然而,这些自然地深入到各自方法的复杂性,而不是与其他方法进行比较;此外,有些人关注的是应用而不是理论。虽然最近有一个关于生成模型作为一个整体的综述[155],但它深入研究了一些特定的实现,而不是检查整个领域。
本综述提供了生成建模趋势的全面概述,引入新的读者到该领域,通过在单一统计框架下的方法,比较和对比,以便解释建模决策背后的每个各自的技术。从理论上讲,为了让读者了解最新的研究成果,本文对新旧文献进行了讨论。特别地,本调查涵盖了基于能量的模型(第2节)、典型的单一非归一化密度模型、变分自编码器(第3节)、基于潜在模型的后验的变分近似、生成对抗网络(第4节)、在最小-最大博弈中设置的两个模型、自回归模型(第5节)、将模型数据分解为条件概率的产品,以及归一化流(第6节)、使用可逆转换的精确似然模型。这种细分被定义为与研究中的典型划分紧密匹配,然而,存在着许多模糊这些界限的混合方法,这些将在最相关的章节中讨论,或者在合适的情况下两者都讨论。
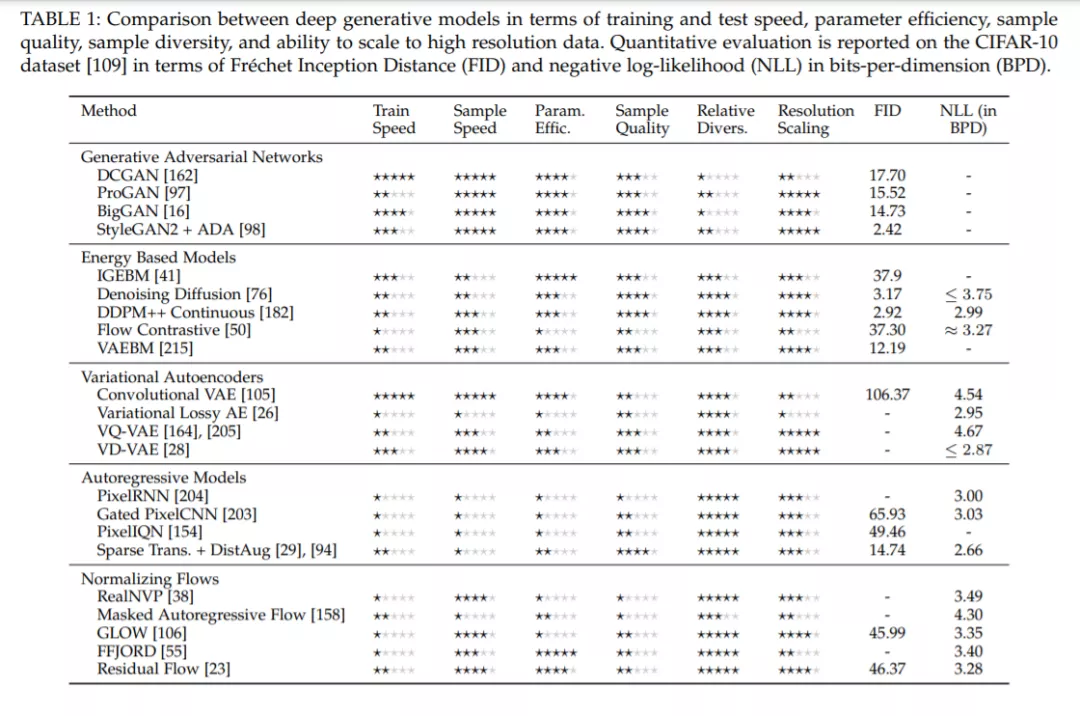
为了简单地了解不同架构之间的差异,我们提供了表1,通过容易比较的星级评级对比了各种不同的技术。具体来说,训练速度是根据报告的总训练时间来评估的,因此要考虑多种因素,包括架构、每一步的函数评估数量、优化的便捷性和所涉及的随机性;样本速度是基于网络速度和所需评估的数量;参数效率是由训练数据集所需的参数总数决定的,而功能更强大的模型通常会有更多的参数,在模型类型之间与质量的相关性不强;一星-一些结构/纹理被捕捉,二星-一个场景可识别但缺少全局结构/细节,三星-重要结构被捕捉但场景看起来“怪异”,四星-与真实图像的差别是可识别的,五星-差别是完全不可察觉的

