
摘要
人工智能(AI)技术的发展使各种应用系统得以应用于现实世界,影响着人们的日常生活。然而,目前很多人工智能系统被发现容易受到无形的攻击,对弱势群体存在偏见,缺乏对用户隐私的保护等,这不仅降低了用户体验,也侵蚀了社会对所有人工智能系统的信任。在这篇综述中,我们努力为人工智能从业者提供一个全面的指南,以构建可信赖的人工智能系统。我们首先介绍了人工智能可信度的重要方面的理论框架,包括稳健性、泛化性、可解释性、透明度、再现性、公平性、隐私保护、与人类价值观的一致性和问责性。然后我们调研了行业中在这些方面的领先方法。为了统一目前零散的人工智能方法,我们提出了一种系统的方法,考虑人工智能系统的整个生命周期,从数据采集到模型开发,到开发和部署,最后到持续监测和治理。在这个框架中,我们向从业者和社会利益相关者(如研究人员和监管机构)提供具体的行动项目,以提高人工智能的可信度。最后,我们确定可信赖的人工智能系统未来发展的关键机遇和挑战,我们确定需要向全面可信赖的人工智能系统转变范式。
https://www.zhuanzhi.ai/paper/00386996069b8168827d03f0c809a462
引言
人工智能(AI)的快速发展给人类社会带来了巨大的经济和社会前景。随着人工智能在交通、金融、医疗、安全、娱乐等领域的广泛应用,越来越多的社会意识到,我们需要这些系统是可信的。这是因为,考虑到这些人工智能系统的普遍性,违背利益相关者的信任可能会导致严重的社会后果。相比之下,人工智能从业者,包括研究人员、开发人员、决策者等,传统上一直追求系统性能(也就是准确性)作为他们工作流程的主要指标。这一指标远远不足以反映对人工智能可信度的要求。除了系统性能外,人工智能系统的各个方面都应该被仔细考虑,以提高其可信度,包括但不限于健壮性、算法公平性、可解释性、透明度等方面。
虽然最活跃的关于人工智能可信度的学术研究集中在模型的算法属性上,但我们发现,单靠算法研究的发展不足以构建可信的人工智能产品。从行业角度看,人工智能产品的生命周期包括数据准备、算法设计、开发、部署、运营、监控、治理等多个阶段。要在任何一个方面(如健壮性)获得可信赖性,需要在系统生命周期的多个阶段进行努力,如数据净化、健壮算法、异常监控、风险审计等。另一方面,任何一个环节或任何一个方面的信任违约都可能破坏整个系统的可信赖性。因此,应该在人工智能系统的整个生命周期中建立和系统地评估人工智能的可信度。
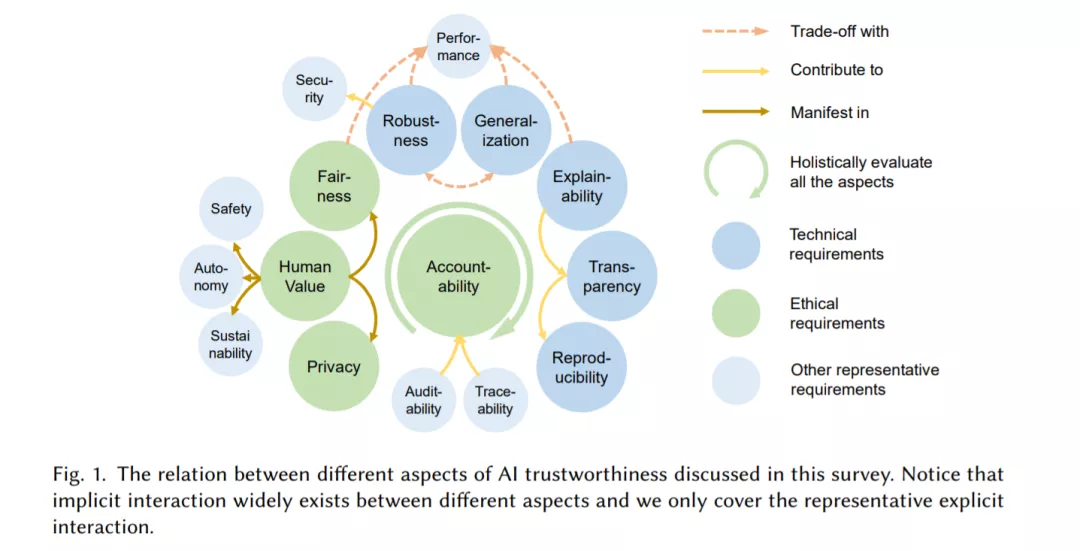
除了通过在不同的可信赖性方面建立可信赖的要求来追求人工智能的可信赖性,这些方面之间的交互是现实世界值得信赖的人工智能系统中一个重要且有待探索的话题。例如,对数据隐私的需求可能会干扰详细解释系统输出的愿望,而对算法公平性的追求可能会不利于某些群体体验到的准确性和稳健性。因此,仅仅贪婪地追求这些不同的方面并不一定会产生通向更可靠的AI系统的最佳解决方案。值得信赖的人工智能应该通过权衡和联合优化多个值得信赖的方面来建立。以上事实表明,有必要采取系统的方法来改变目前的人工智能范式,以获得可信赖性。这需要多学科相关者的意识和合作,相关者在系统生命周期的不同可信方面和不同阶段工作。为了帮助开发这种系统方法,我们以一种可访问的方式组织多学科知识,让人工智能从业者了解人工智能的可信赖性,并为构建可信赖的人工智能系统提供操作和系统的指导。我们的主要贡献包括:
-
我们调研和扩大在最近讨论关于AI可信赖性,建立值得信赖的AI系统的迫切需要得到我们的东西从工业的角度来看,包括鲁棒性、泛化,可解释性、透明度、复现性、公平、隐私保护、价值一致和责任(第2节)。
-
我们广泛回顾了各种利益相关者为实现这些需求所做的努力,包括积极的学术研究、工业发展技术以及治理和管理机制。这种多样化和全面的方法集合有助于提供人工智能可信度的整体图景,并弥合来自不同背景的从业者之间的知识鸿沟(第3节)。
-
我们剖析了工业应用中人工智能系统的整个开发和部署生命周期,并讨论了从数据到人工智能模型,从系统部署到操作的每个阶段如何提高人工智能的可信度。我们提出了一个系统框架来组织值得信赖的人工智能的多学科和碎片化方法,并进一步提出将人工智能值得信赖作为一个连续的工作流,在人工智能系统生命周期的每个阶段纳入反馈。我们也分析了在实践中不同可信度方面之间的关系(相互增强,有时是权衡)。因此,我们的目标是为研究人员、开发人员、操作人员和法律专家等人工智能从业者提供一个可访问的、全面的指南,以快速理解通向人工智能可信度的方法(第4节)。
-
我们讨论了值得信赖的人工智能的突出挑战,在不久的将来,研究社区和行业从业者应该专注于解决这些挑战。我们确定了几个关键问题,包括需要对人工智能可信度的几个方面(如健壮性、公平性和可解释性)有更深层次的基础理解,用户意识的重要性,以及促进跨学科和国际合作(第5节)。
