
预训练模型通过自监督学习方法在大规模文本语料库上学习上下文化的词表示,该方法经过微调后取得了良好的性能。然而,这些模型的健壮性差,且缺乏可解释性。带有知识注入的预训练模型(knowledge enhanced pre- training model, KEPTMs)具有深刻的理解和逻辑推理能力,并在一定程度上引入了可解释性。在这个综述中,我们提供了自然语言处理的KEPTMs的全面概述。首先介绍了预训练模型和知识表示学习的研究进展。然后我们从三个不同的角度对现有KEPTMs进行了系统的分类。最后,对KEPTMs的未来研究方向进行了展望。
https://www.zhuanzhi.ai/paper/2e6a280b91bab87be5075bc650650678
引言
数据和知识是人工智能的核心。深度学习[1],[2],[3]借助神经网络的分布式表示和层次结构泛化,可以充分利用大规模数据。基于深度学习的预训练模型[4]、[5]、[6]、[7]、[8]、[9]、[10]、[11]、[12]、[13]、[14]、[15]、[16]、[17]、[18]有了质的飞跃,促进了下游自然语言处理(NLP)的广泛应用。虽然它们可以从大规模的无监督语料库中获取词汇、句法和浅层语义信息,但它们是统计模型,受重尾数据分布的限制,导致无法深入理解和因果推理和反事实推理。此外,尽管深度学习在学习数据背后的关键因素方面很强大,但由于纠缠表示,预先训练的模型失去了可解释性。知识为模型提供了全面而丰富的实体特征和关系,克服了数据分布的影响,增强了模型的鲁棒性。此外,知识为模型引入了显式语义的可解释性。因此,利用不同的知识来实现预先训练的具有深度理解和逻辑推理的模型是必不可少的。为了更好地集成知识和文本特征,将符号知识投影到一个密集的、低维的语义空间中,并通过分布式向量通过学习[19]的知识表示来表示。在此背景下,研究人员探索了通过注入知识来概括知识驱动和语义理解所需场景的方法来改进预先训练的模型。
这项综述的贡献可以总结如下:
全面综述。本文对自然语言处理的预训练模型和知识表示学习进行了综述。 新分类法。我们提出了一种面向自然语言处理的KEPTMs分类法,根据注入知识的类型将现有KEPTMs分为三组,并根据知识与语料库的耦合关系和知识注入方法进一步划分不同组对应的模型。 未来的发展方向。讨论分析了现有KEPTMs的局限性,并提出了未来可能的研究方向。
近年来,预训练模型的逐步发展引起了研究者的广泛关注。然而,尽管他们在创作上付出了巨大的努力,但却无法理解文本的深层语义和逻辑推理。此外,从模型中学习到的知识存在于参数中,是无法解释的。通过注入KGs的实体特征和事实知识,可以极大地缓解鲁棒性差和可解释性不足的问题。本文介绍的预训练模型大多侧重于语言知识和世界知识的利用,这些知识属于2.2.1节中定义的事实知识或概念知识。这类知识为预训练模型提供了丰富的实体和关系信息,极大地提高了预训练模型的深度理解和推理能力。
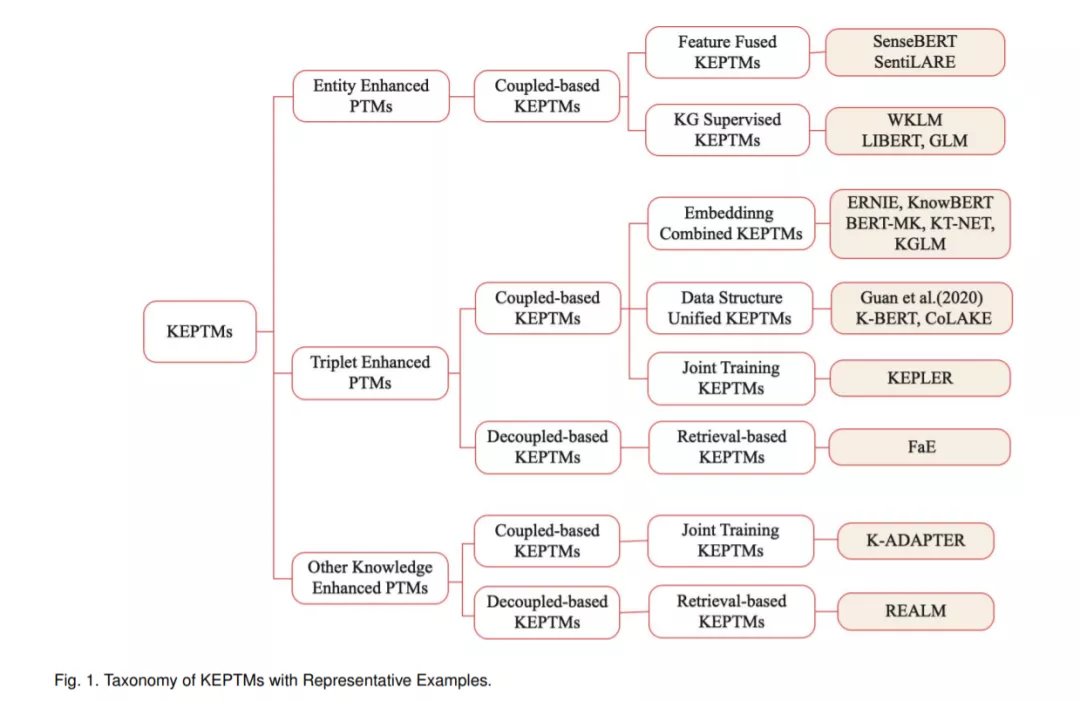
为了比较和分析现有的KEPTMs,我们首先根据注入知识的类型将其分为三类: 实体增强的预训练模型、三元组增强的预训练模型和其他知识增强的预训练模型。对于实体增强的预训练模型,所有这些模型都将知识和语言信息存储在预训练模型的参数中,属于基于耦合的KEPTMs。根据实体注入的方法,进一步将其分为实体特征融合模型和知识图谱监督预训练模型。对于三联体增强的训练前模型,我们根据三联体与语料是否耦合,将其分为基于耦合和基于解耦的KEPTMs。基于耦合的KEPTMs在训练前将单词嵌入和知识嵌入纠缠在一起,无法保持符号知识的可解释性。根据三联体输注方法,将基于耦合的KEPTMs分为三组: 嵌入联合KEPTMs、数据结构统一KEPTMs和联合训练KEPTMs。而基于解耦的KEPTMs则分别保留了知识和语言的嵌入,从而引入了符号知识的可解释性。我们将其划分为基于检索的KEPTMs,因为它通过检索相关信息来利用知识。其他知识增强模型也可分为基于耦合和基于解耦的KEPTMs。我们进一步将其分为联合训练和基于检索的KEPTMs。
