持续学习
·


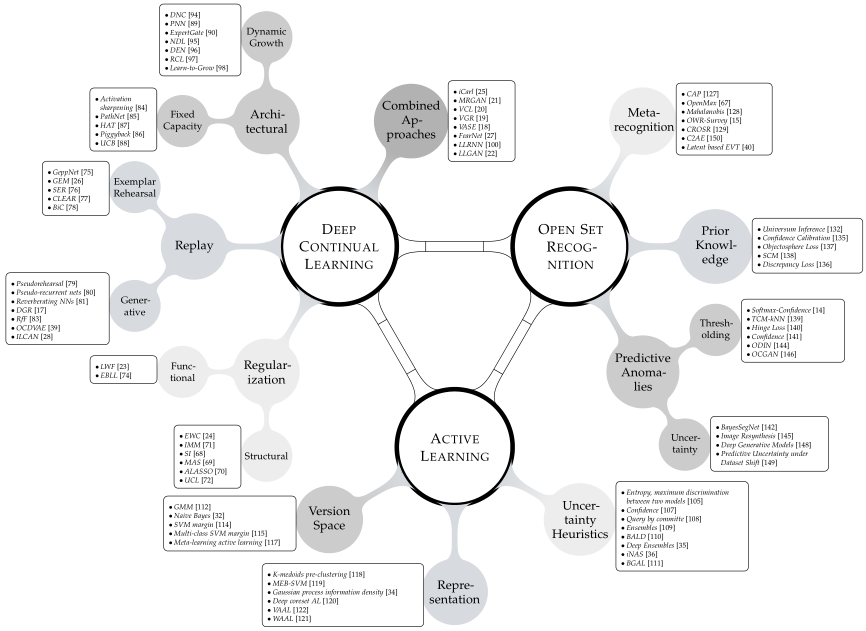
当前的深度学习研究以基准评价为主。如果一种方法在专门的测试集上有良好的经验表现,那么它就被认为是有利的。这种心态无缝地反映在连续学习的重现领域,在这里研究的是持续到达的基准数据集。核心挑战是如何保护之前获得的表示,以免由于迭代参数更新而出现灾难性地遗忘的情况。然而,各个方法的比较是与现实应用程序隔离的,通常通过监视累积的测试集性能来判断。封闭世界的假设仍然占主导地位。假设在部署过程中,一个模型保证会遇到来自与用于训练的相同分布的数据。这带来了一个巨大的挑战,因为众所周知,神经网络会对未知的实例提供过于自信的错误预测,并在数据损坏的情况下崩溃。在这个工作我们认为值得注意的教训来自开放数据集识别,识别的统计偏差以外的数据观测数据集,和相邻的主动学习领域,数据增量查询等预期的性能收益最大化,这些常常在深度学习的时代被忽略。基于这些遗忘的教训,我们提出了一个统一的观点,以搭建持续学习,主动学习和开放集识别在深度神经网络的桥梁。我们的结果表明,这不仅有利于每个个体范式,而且突出了在一个共同框架中的自然协同作用。我们从经验上证明了在减轻灾难性遗忘、主动学习中查询数据、选择任务顺序等方面的改进,同时在以前提出的方法失败的地方展示了强大的开放世界应用。****
成为VIP会员查看完整内容
相关内容
Arxiv
10+阅读 · 2020年4月9日
Arxiv
3+阅读 · 2019年4月10日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
10+阅读 · 2020年4月9日
Arxiv
3+阅读 · 2019年4月10日