通用世界模型代表了实现通用人工智能(AGI)的关键途径,是从虚拟环境到决策系统等各类应用的基石。近期,Sora模型的出现因其卓越的模拟能力而备受关注,展现出对物理定律的初步理解。在这篇综述中,我们将全面探索世界模型的最新进展。我们的分析涵盖了视频生成领域的前沿生成方法,在该领域,世界模型作为核心结构,促进了高度逼真的视觉内容合成。此外,我们深入研究了自动驾驶世界模型这一新兴领域,详细描述了其在重塑交通和城市移动性方面不可或缺的作用。进一步地,我们剖析了部署于自主智能体中的世界模型的复杂性,阐明了它们在实现动态环境中智能交互方面的重要意义。最后,我们探讨了世界模型的挑战和局限性,并展望了其潜在的未来方向。我们希望这篇综述能够为研究社区提供一个基础性参考,并激发持续的创新。这篇综述将定期更新,网址为:https://github.com/GigaAI-research/General-World-Models-Survey。
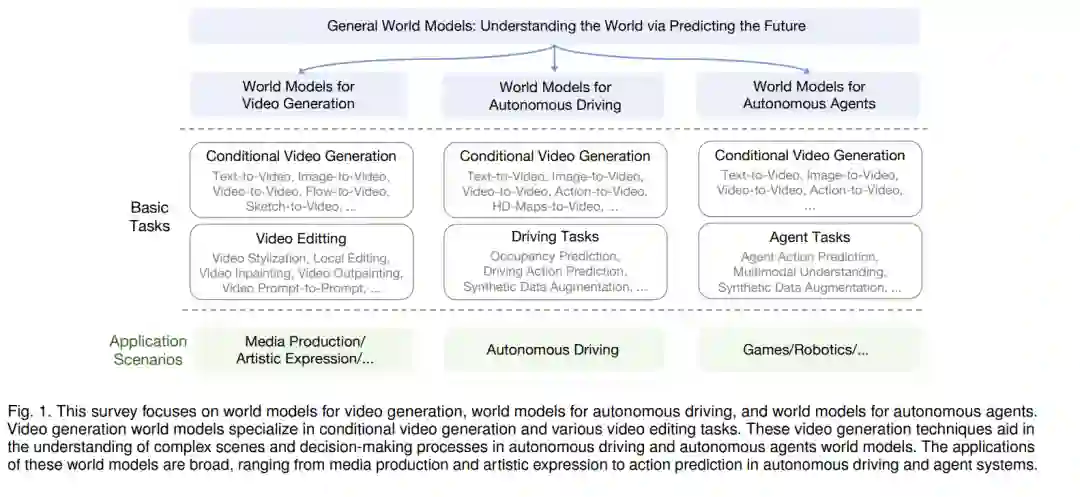
在追求通用人工智能(AGI)的过程中,开发通用世界模型是一条基本途径。通用世界模型旨在通过生成过程来理解世界。值得注意的是,Sora模型的引入[21]引起了广泛关注,其卓越的模拟能力不仅展示了对物理定律的初步理解,还突显了世界模型领域的可喜进展。站在人工智能驱动创新的前沿,有必要深入研究世界模型领域,揭示其复杂性,评估其当前发展阶段,并思考其未来可能的发展轨迹。 世界模型通过预测未来来加深对世界的理解。这种预测能力在视频生成、自动驾驶和自主智能体的发展中具有巨大潜力,代表了世界模型的三个主流发展方向。如图1所示,视频生成世界模型涵盖了视频的生成和编辑,以理解和模拟世界,为媒体制作和艺术表达带来了价值。借助视频生成技术,自动驾驶世界模型可以创建驾驶场景,从驾驶视频中学习驾驶要素和策略。这一知识有助于直接生成驾驶动作或训练驾驶策略网络,从而推动端到端自动驾驶。类似地,智能体世界模型利用视频生成技术在动态环境中建立智能交互。与驾驶模型不同,它们构建的策略网络适用于各种虚拟(例如游戏或模拟环境中的程序)或物理(例如机器人)情境。 在全面世界建模的基础上,视频生成方法通过视觉合成揭示物理定律。最初,生成模型主要集中在图像生成[10]、[33]、[46]、[66]、[155]、[168]、[173]、[177]、[236]和编辑[95]、[129]、[154]、[245]上,为合成动态视觉序列的更复杂进展奠定了基础。随着时间的推移,生成模型[17]、[18]、[52]、[63]、[68]、[84]、[111]、[229]、[243]不仅能够捕捉图像的静态特征,还能将一系列帧无缝串联起来。这些模型已经发展出了一定的物理和运动理解能力,代表了早期和有限形式的通用世界模型[62]。值得注意的是,Sora模型[21]处于这一演化的前沿。通过利用生成技术的力量,Sora展示了生成精细视觉叙事的深刻能力,并遵循物理世界的基本原则。生成模型和世界建模之间的关系是共生的,相互启发和丰富。生成模型可以在受控环境中构建大量数据,从而减轻对现实世界数据采集的广泛需求,尤其有利于训练实际应用中必需的人工智能系统。此外,生成模型的有效性关键取决于世界模型所提供的理解深度。正是世界模型对潜在环境动态的全面理解,赋予了生成模型在严格物理约束下产生质量更高的视觉信号的能力,从而增强了它们在各个领域的真实性和实用性。
世界模型理解环境的能力不仅提高了视频生成质量,还能促进现实驾驶场景的发展。通过使用预测技术理解驾驶环境,世界模型正通过预测未来驾驶场景来重塑交通和城市移动性,从而提高安全性和效率。旨在建立动态环境模型的世界方法在自动驾驶中至关重要,因为对未来的准确预测对安全操作至关重要。然而,为自动驾驶构建世界模型面临独特的挑战,主要是因为现实驾驶场景中固有的样本复杂性。早期方法[60]、[90]、[159]试图通过减少搜索空间并明确解开视觉动态来应对这些挑战。尽管取得了一些进展,但主要集中在模拟环境上的重点限制是一个关键的局限性。最近的进展显示,自动驾驶世界模型利用生成模型来应对搜索空间较大的现实场景。GAIA-1[91]使用Transformers预测下一个视觉令牌,有效构建驾驶世界模型。这一方法使得可以根据不同提示(例如天气条件、场景、交通参与者和车辆动作)预测多种潜在未来。类似地,DriveDreamer[209]和Panacea[218]等方法利用预训练扩散模型从现实驾驶视频中学习驾驶世界模型。这些技术利用驾驶场景中固有的结构化信息可控地生成高质量的驾驶视频,甚至可以提高驾驶感知任务的训练效果。基于DriveDreamer的DriveDreamer2[249]进一步整合了大型语言模型,增强了驾驶世界模型的性能和用户交互能力。它能够仅通过自然语言输入生成可控驾驶场景视频,甚至包括像突然超车这样罕见的场景。此外,Drive-WM[212]证明了直接使用生成的驾驶场景视频进行端到端驾驶训练的可行性,大大提高了端到端驾驶性能。通过预测未来场景,这些模型赋予车辆做出明智决策的能力,最终实现更安全、更高效的道路导航。此外,这种整合不仅提高了交通系统的安全性和效率,还为城市规划和设计开辟了新的可能性。
除了在驾驶场景中确立的实用性之外,世界模型已日益成为自主智能体功能的重要组成部分,促进了各类环境中的智能交互。例如,游戏智能体中的世界模型不仅增强了游戏体验,还推动了复杂游戏算法的发展。Dreamer系列[72]、[73]、[74]很好地展示了它如何巧妙地利用世界模型预测游戏环境中的未来状态。这一能力使游戏智能体能够通过想象进行学习,大大减少了有效学习所需的互动量。在机器人系统中,创新方法进一步凸显了世界模型的多功能性和潜力。UniPi[50]将机器人中的决策问题重新构想为文本到视频任务。其策略即视频的设计使得在各种机器人操作任务中促进学习和泛化。同样,UniSim[232]通过生成建模引入了动态交互模拟器,可以在现实场景中部署而无需事先接触。RoboDreamer[255]通过利用世界模型提出涉及动作和物体组合的计划,推动了在新的机器人执行环境中解决前所未有的任务的能力。世界模型的多方面应用不仅限于游戏和机器人。LeCun提出的联合嵌入预测架构(JEPA)[115]标志着传统生成模型的重大转变。JEPA学习将输入数据映射到高级表示空间中的预测输出,使模型能够专注于学习更具语义特征的特征,增强了其跨各种模态理解和预测的能力。
基于上述全面的讨论,世界模型的研究显然对实现AGI具有巨大的潜力,并且在各个领域具有广泛的应用。因此,世界模型需要学术界和工业界的重大关注,并需要长期持续的努力。与近期有关世界模型的综述[36]、[67]、[136]、[193]相比,我们的综述提供了更广泛的覆盖范围。它不仅涵盖了视频生成中的生成世界模型,还深入探讨了世界模型在自动驾驶和机器人等决策系统中的应用。我们希望这篇综述能够为刚踏入这一领域的新手提供有价值的见解,同时激发社区中成熟研究人员的批判性思维和讨论。 本综述的主要贡献可以总结如下:(1)我们对世界模型研究的最新进展进行了整体审视,包括深刻的哲学观点和详细讨论。(2)我们的分析深入探讨了围绕视频生成、自动驾驶和自主智能体的世界模型文献,揭示了它们在媒体制作、艺术表达、端到端驾驶、游戏和机器人方面的应用。(3)我们评估了现有世界模型的挑战和局限性,并深入探讨了未来研究的潜在途径,旨在引导和激发世界模型的进一步进步。