

视频基础模型(ViFMs)旨在为各种视频理解任务学习通用表示。通过利用大规模数据集和强大的模型,ViFMs通过从视频数据中提取稳健且通用的特征来实现这一目标。这篇综述分析了超过200个视频基础模型,提供了针对14种不同视频任务的基准和评估指标的全面概览,并将其分为3个主要类别。此外,我们还对最常见的6种视频任务的这些模型进行了深入的性能分析。我们将ViFMs分为三类:1)基于图像的ViFMs,将现有的图像模型应用于视频任务;2)基于视频的ViFMs,采用特定于视频的编码方法;3)通用基础模型(UFMs),在单一框架内结合多种模态(图像、视频、音频和文本等)。通过比较各种ViFMs在不同任务上的性能,这篇综述提供了有关它们优缺点的宝贵见解,为视频理解的未来进展提供指导。我们的分析结果令人惊讶地发现,基于图像的基础模型在大多数视频理解任务上始终优于基于视频的模型。此外,利用多模态的UFMs在视频任务上表现出色。我们在以下地址分享了这项研究中所分析的ViFMs完整列表:https://github.com/NeeluMadan/ViFM_Survey.git
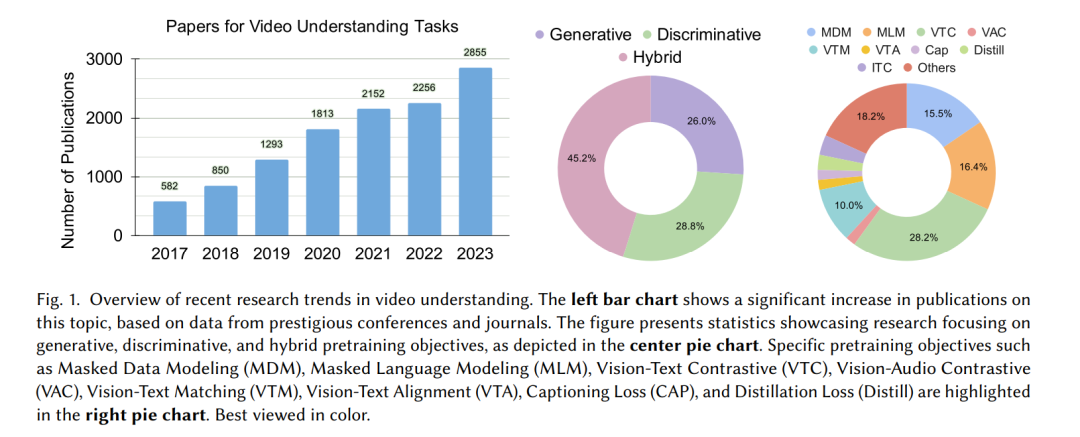
强大的计算资源的日益普及和不断增长的数据集推动了基础模型的发展[10, 24]。这些多功能的AI模型使用自监督学习或半监督学习在海量数据上进行训练,可以通过微调用于各种下游任务。最初的成功集中在静态图像上[123, 238],例如CLIP[238]和SAM[139]等模型都取得了令人印象深刻的成果。最近的研究[322, 352]已将这一成果扩展到视频领域,开发出了几种针对视频基础模型(ViFMs)的预训练策略。 尽管视频分析和生成数十年来一直是计算机视觉社区关注的焦点[19, 30, 134, 142, 278, 281],但由于任务的复杂性、额外的时间维度以及数据量庞大,这一问题在很大程度上一直具有挑战性。最初开发的方法主要基于使用标准图像分析技术处理各个帧并在其上加入时间维度[30, 80]。或者,专为视频设计的更高级技术也被开发出来,例如3D卷积[338]、循环网络、光流的使用以及Transformers[7, 19],直接作用于视频,从而提供更好的时间建模。此外,针对增强视频理解的多模态角色的研究也有显著发展[111, 245]。 我们在ViFMs的发展中也看到了类似的趋势,延续了图像(基于图像的ViFMs)、独立的视频建模(基于视频的ViFMs)以及结合额外模态(例如自动语音识别(ASR))(通用基础模型,Universal FMs)的路径。 动机和贡献:视频理解领域正在经历显著的进步,这可以从日益增长的专注于各类视频理解任务的研究论文数量中看出(图1)。这种增长与大规模预训练技术的发展相吻合。这些技术在适应不同任务方面表现出非凡的能力,只需最少的额外训练即可实现强大的泛化。因此,研究人员正在积极探索这些基础模型在解决各种视频理解挑战中的作用。为了在这个快速发展的研究领域中导航(见图2),对视频理解模型进行系统的综述是必要的。我们试图通过对用于视频理解任务的基础模型进行全面分析来填补这一关键空白。我们希望这篇综述能够为视频理解相关的未来研究方向提供路线图。
我们综述的主要贡献: * 本文首次对部署于各种视频理解任务的基础模型(ViFMs)进行了全面的综述。我们将ViFMs分为三类:1)基于图像的ViFMs:仅在图像数据上进行训练。2)基于视频的ViFMs:在训练期间利用视频数据。3)通用基础模型(UFMs):在预训练期间结合多种模态(图像、视频、音频、文本)。 * 我们独特地根据视频理解任务中对时间维度的涉入程度对其进行了分类。此外,还提供了与每个分类任务相关的数据集和评估指标的详细列表。 * 我们对每个类别的ViFMs进行了全面的比较,分析了各种研究成果。这一分析揭示了有关最有效的ViFMs在不同视频理解任务中的宝贵见解。 * 本综述进一步指出了ViFMs面临的关键挑战,强调了需要进一步研究关注的开放性问题。此外,我们讨论了ViFM开发的有前景的未来方向,为视频理解的进步铺平道路。
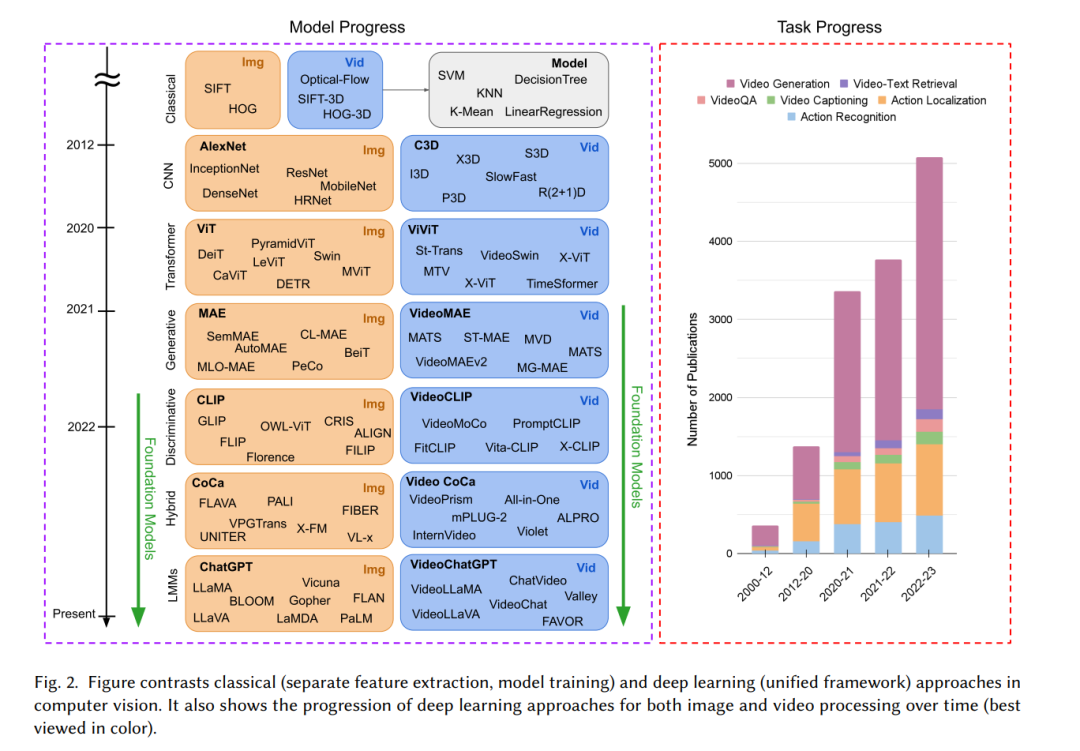
相关综述:尽管一些综述深入探讨了特定的视频理解任务[353, 366]或图像的基础模型[10],如Shiappa等人[252]提供了关于自监督视频理解方法的详尽综述,但近年来这一领域已经发生了显著变化。随着大规模基础模型的兴起,需要对这些模型在视频理解背景下进行全面的综述。据我们所知,我们的综述是第一个提供用于视频理解的基础模型的全面概述。 论文组织结构:在论文的第一部分(第2节),我们涵盖了从视频分类到生成的各种视频分析任务。我们讨论了广泛使用的架构和损失函数,以及与大规模预训练相关的数据集。接下来,我们解释了ViFMs的主要类别,即:基于图像的ViFMs(第3节)、基于视频的ViFMs(第4节)和通用基础模型(UFMs)(第5节)(有关分类法请参见图5)。最后(第6-7节),我们比较并讨论了所介绍模型的性能,并展示了该领域的挑战和未来方向。
