初学者系列:Deep FM详解
导读
核心思想
01
原理
02
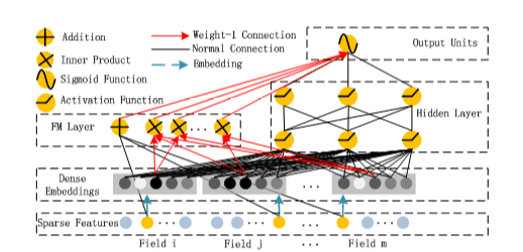
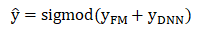
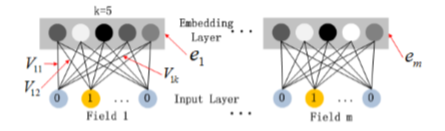
Embedding

-
V_{ij}表示第i个特征Embeding之后在隐向量的第j维。 -
x_{1j}表示第1个field的one-hot特征的第j个值
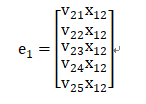
Note: 在FM部分和DNN部分,embedding是共享权重的,对同一个特征来说,得到的V_i 相同。虽然输入fields的长度不同,但是embedding之后的长度是一样的。
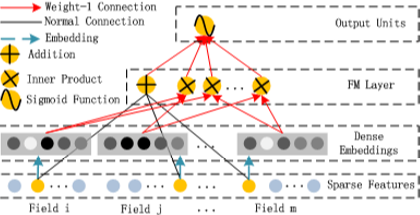
FM模块
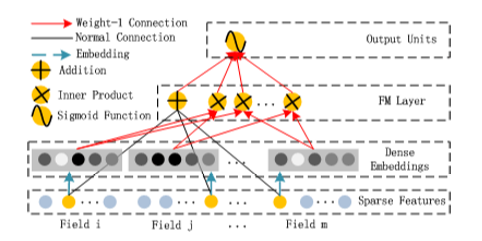
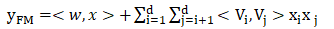
-
d是输入one-hot之后的维度(对应FM论文中的n)
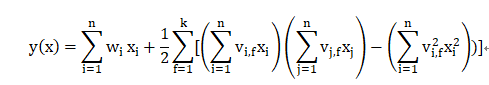
tips:请点击FM查看FM的具体推倒过程
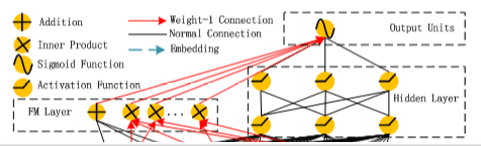
Deep模块
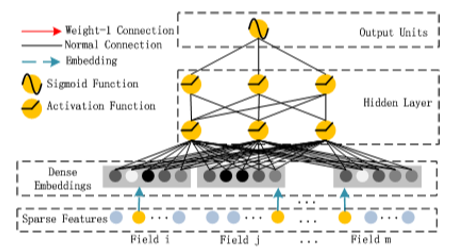
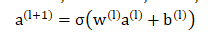
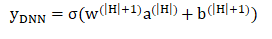
实践
03
数据集

数据构造(data.py)


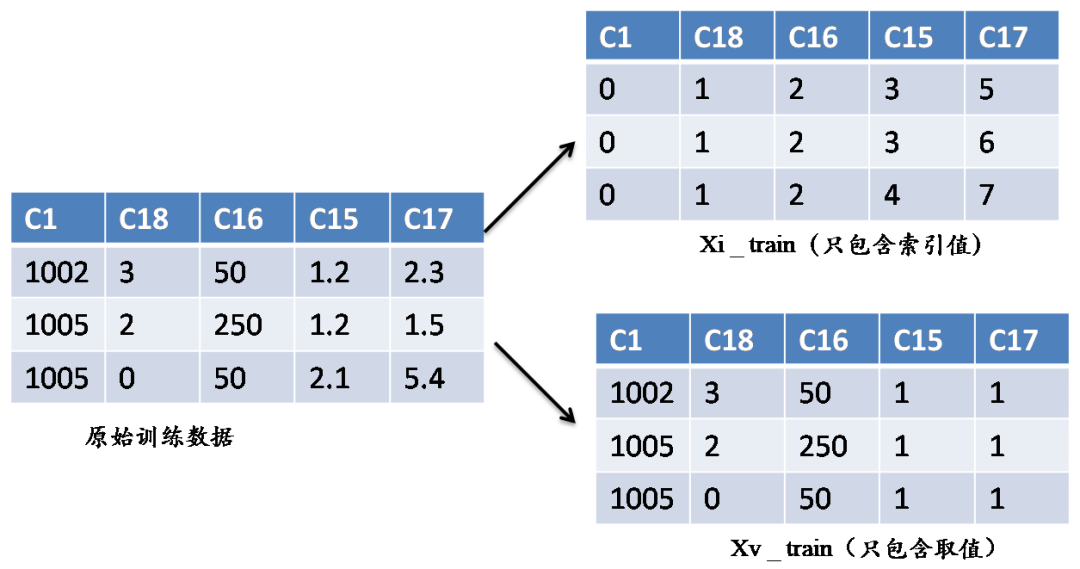
模型构造(main.py)
-
加载数据
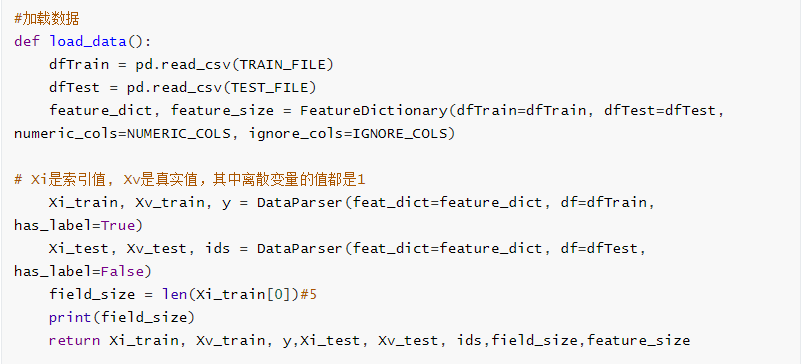

-
构建模型







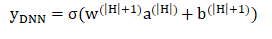


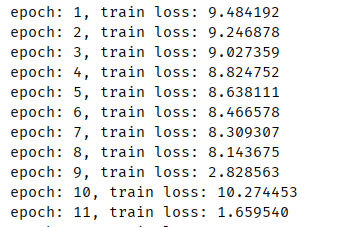
训练

预测

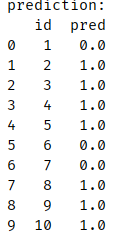
获取代码
请关注专知公众号(点击上方蓝色专知关注)
后台回复“初学者系列deepFM”即可获取数据集以及全部代码。




登录查看更多
相关内容

FM 2019是正式方法欧洲(FME)组织的系列国际研讨会中的第23次,该协会是一个独立的协会,旨在促进软件开发正式方法的使用和研究。官网链接:http://formalmethods2019.inesctec.pt/?page_id=565
专知会员服务
101+阅读 · 2020年6月28日
专知会员服务
71+阅读 · 2020年2月5日
Arxiv
7+阅读 · 2018年5月24日


相关VIP内容
专知会员服务
101+阅读 · 2020年6月28日
专知会员服务
71+阅读 · 2020年2月5日
相关资讯
相关论文
Arxiv
7+阅读 · 2018年5月24日