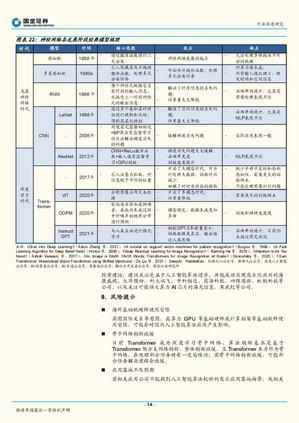
神经网络的发展以Relu激活函数的提出为分水岭,可分为浅层神经网络和深度学习两个阶段。浅层神经网络阶段最重要的任务是解决梯度不稳定的问题,在这个问题未被妥善解决之前,神经网络受限于激活函数梯度过大或过小、以及神经元全连接对高算力的要求,因此应用性能不佳,而属于非神经网络的支持向量机(SVM)是当时解决人工智能模式识别的主流方法。
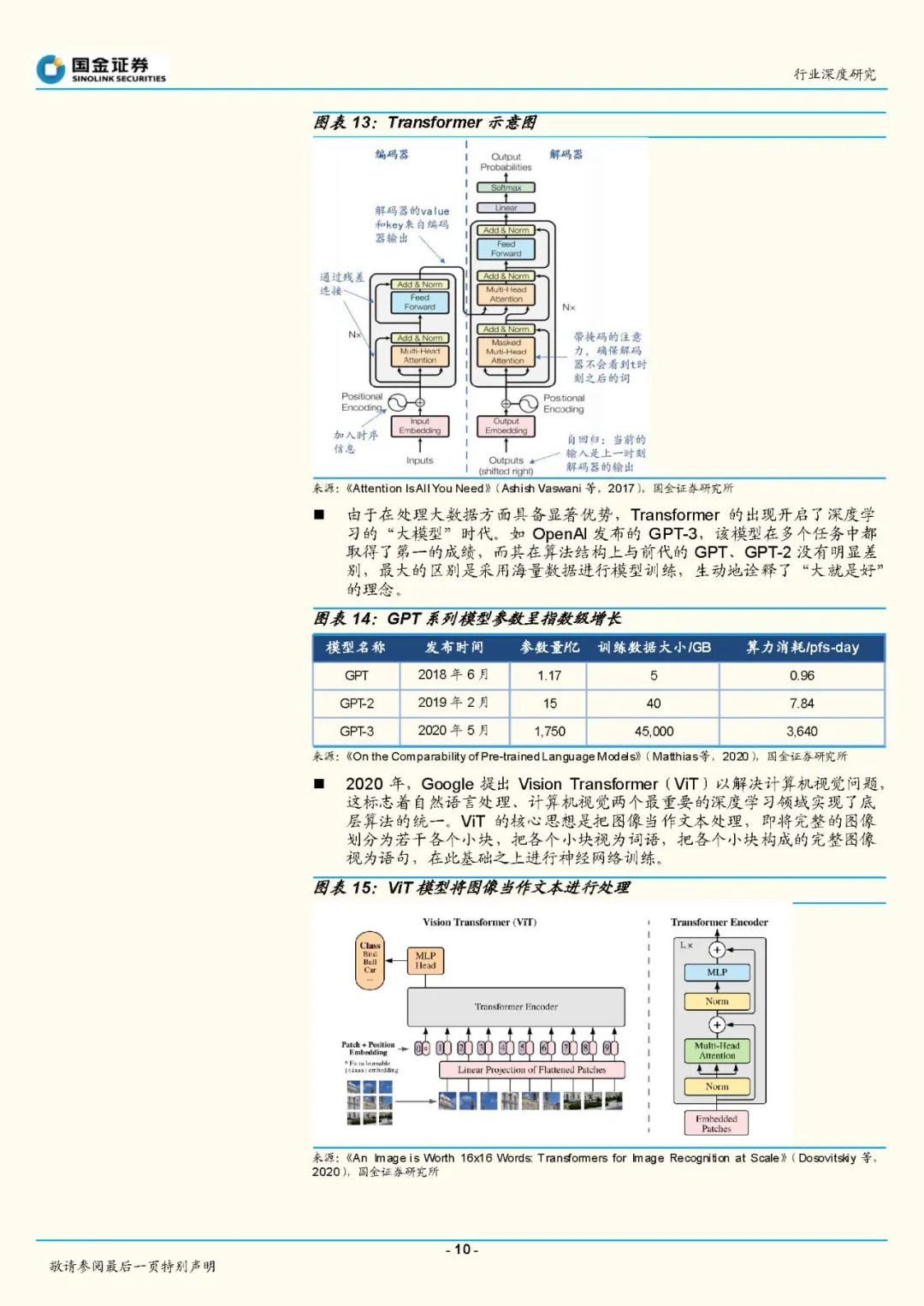
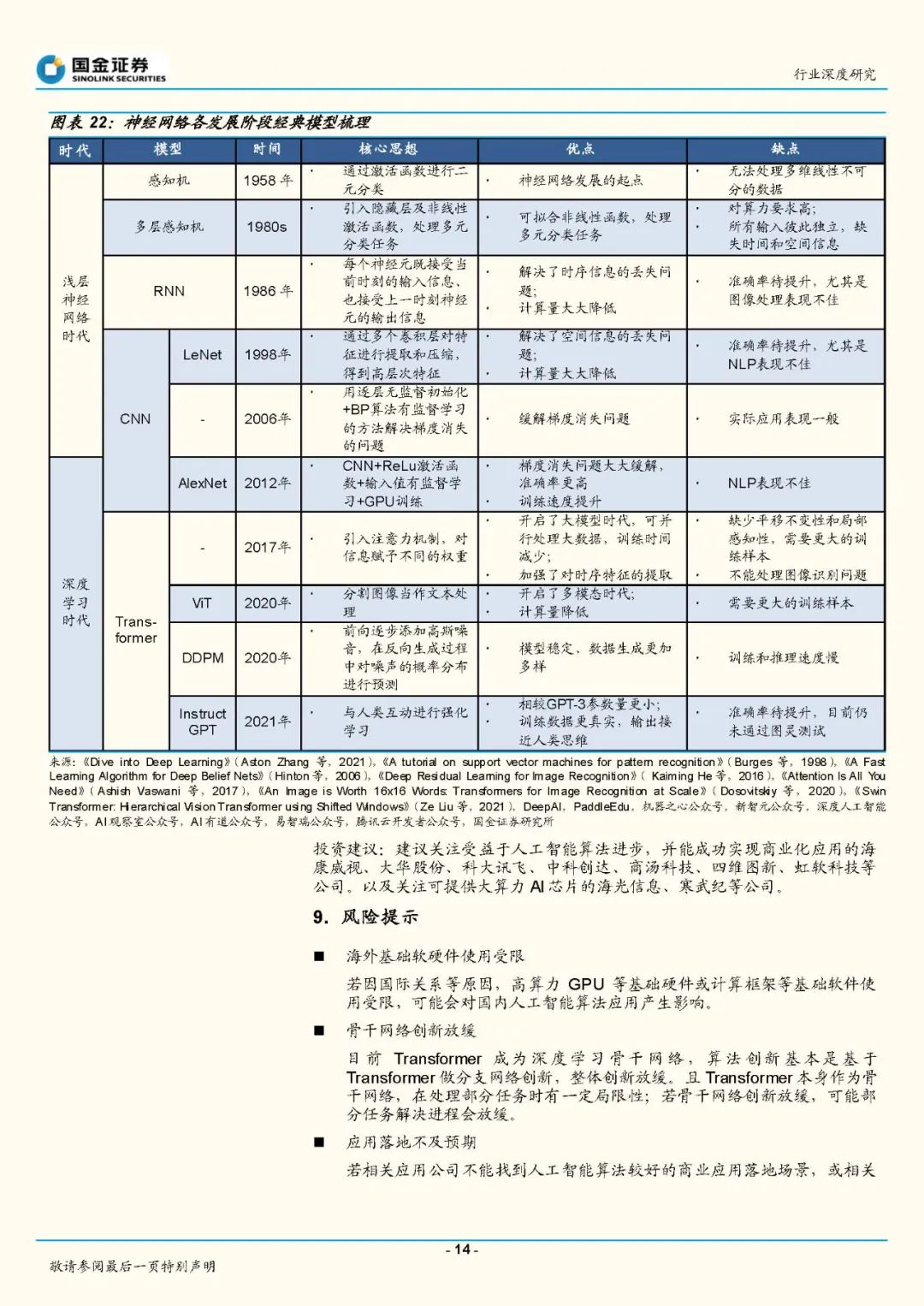
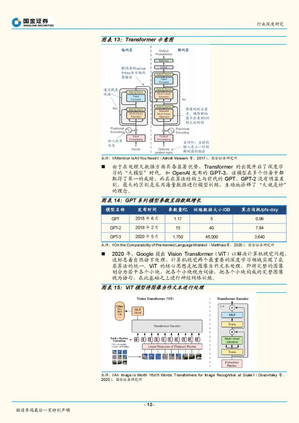
过去10年,深度学习经历了从多样化发展到融合统一的阶段。深度学习时代的开启依托于2011年Relu激活函数被提出、梯度消失问题被大幅缓解,此后深度学习算法和应用的发展均突飞猛进。最初卷积神经网络(CNN)通过对高层次特征的提取和压缩,擅长图像分类等任务;循环神经网络(RNN)通过对时序信息的提取,擅长文字、语音识别和理解等任务。2017年Transformer的提出让深度学习进入了大模型时代、2020年VisionTransformer的提出让深度学习进入了多模态时代。由于Transformer在大数据并行计算方面具备优势,且训练数据增长后对模型精度提升明显,自此各模态和各任务底层算法被统一为Transformer架构。 深度学习底层算法发展放缓,数据无监督学习、数据生成以及高算力芯片成为行业发展的重点方向。目前深度学习算法主要是基于Transformer骨干网络来进行分支网络的创新。如OpenAI在多模态主干网络CLIP的基础上引入扩散模型,即训练出能完成语义图像生成和编辑的DALL〃E2,引发AIGC浪潮;在GPT-3模型基础上引入了人类反馈强化学习方法(RLHF),训练出InstructGPT模型,并据此发布了对话机器人ChatGPT,引起了互联网用户的注意。但随着Transformer基本完成底层算法统一之后,整个行业底层算法发展速度开始放缓,静待骨干网络的下一次突破。同时基于Transformer对大数据的需求,催生了无监督学习、高算力芯片的发展。