深度学习简史:从感知机到Transformer
作者:Jean de Dieu Nyandwi
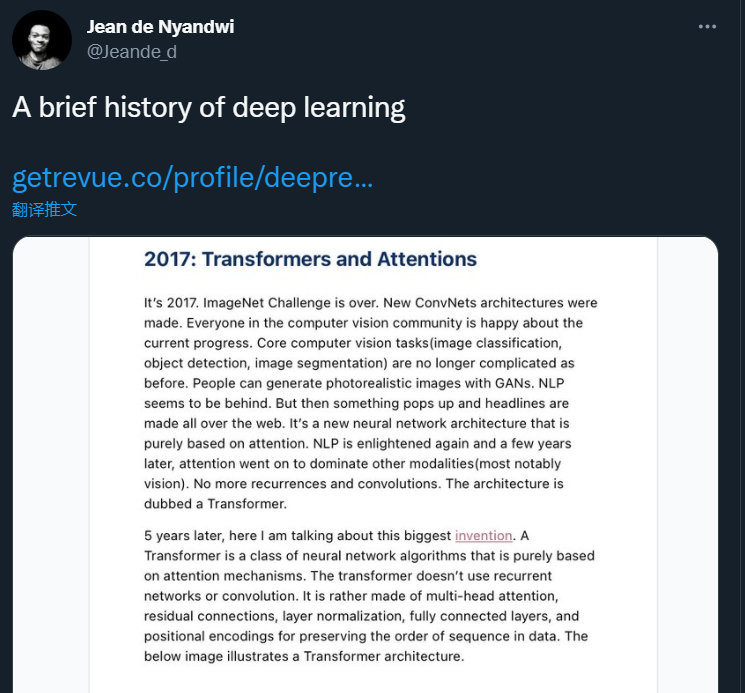
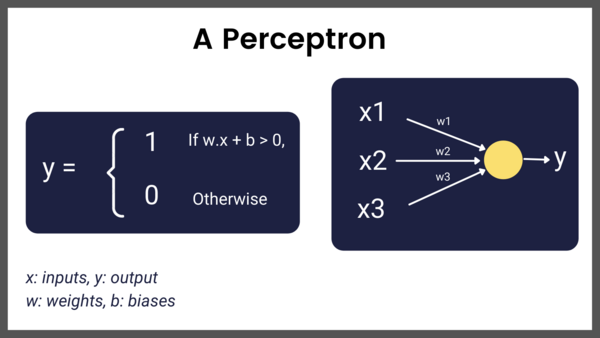
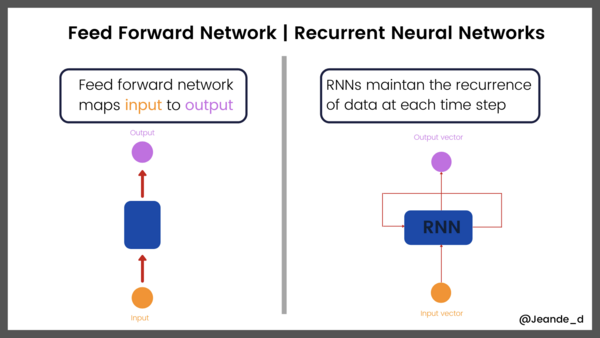
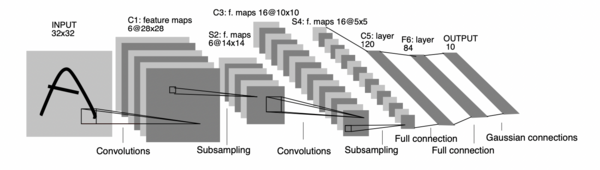
这篇文章从感知机开始,按照时间顺序回顾了深度学习的历史。

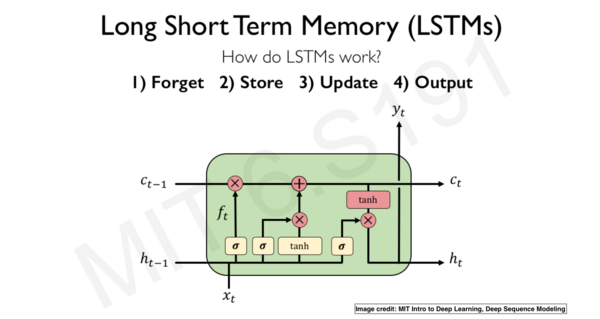
输入门识别输入序列。
遗忘门去掉输入序列中包含的所有不相关信息,并将相关信息存储在长期记忆中。
LTSM 单元更新更新单元的状态值。
输出门控制必须发送到下一个时间步的信息。
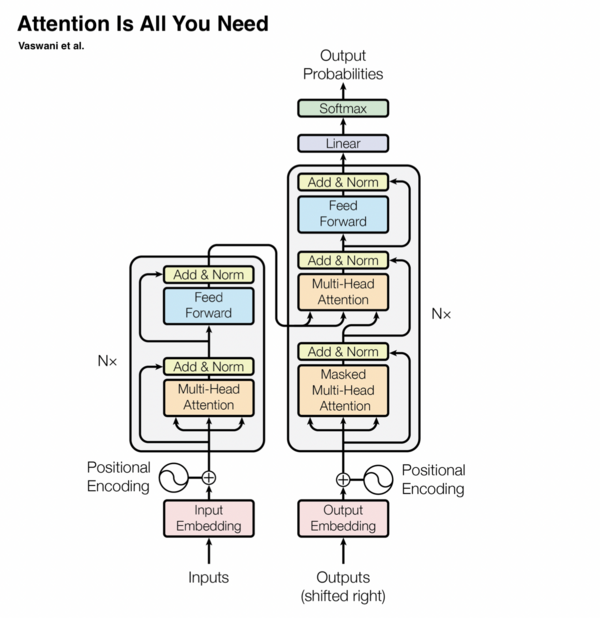
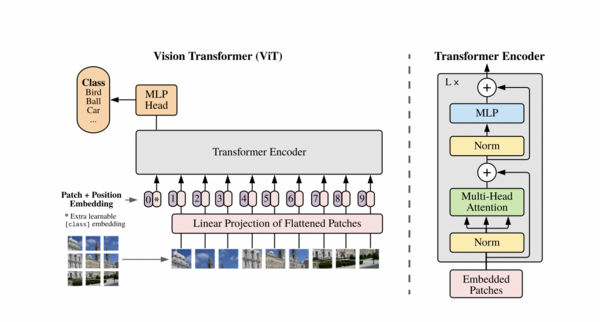


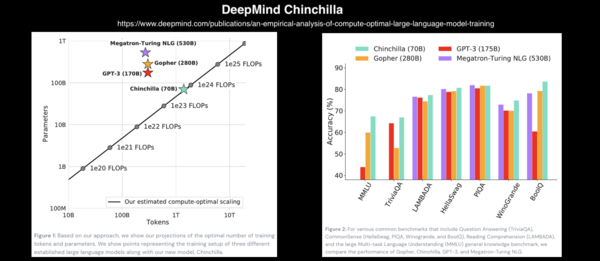
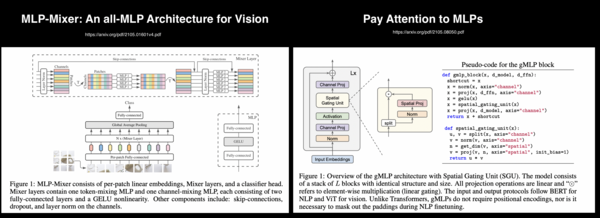
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“深度学习” 就可以获取《深度学习专知合集》专知下载链接



登录查看更多
相关内容

Arxiv
0+阅读 · 2022年7月27日
Arxiv
21+阅读 · 2020年12月17日
相关主题


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年7月27日
Arxiv
21+阅读 · 2020年12月17日