编辑:LRS
【新智元导读】随着神经网络的发展,各种各样的模型都被研究出来,卷积、Transformer也是计算机视觉中国常用的模型,而最近清华大学发表了一篇survey,研究结果或许表明全连接层才是最适合视觉的模型,并将迎来新的AI范式转换!
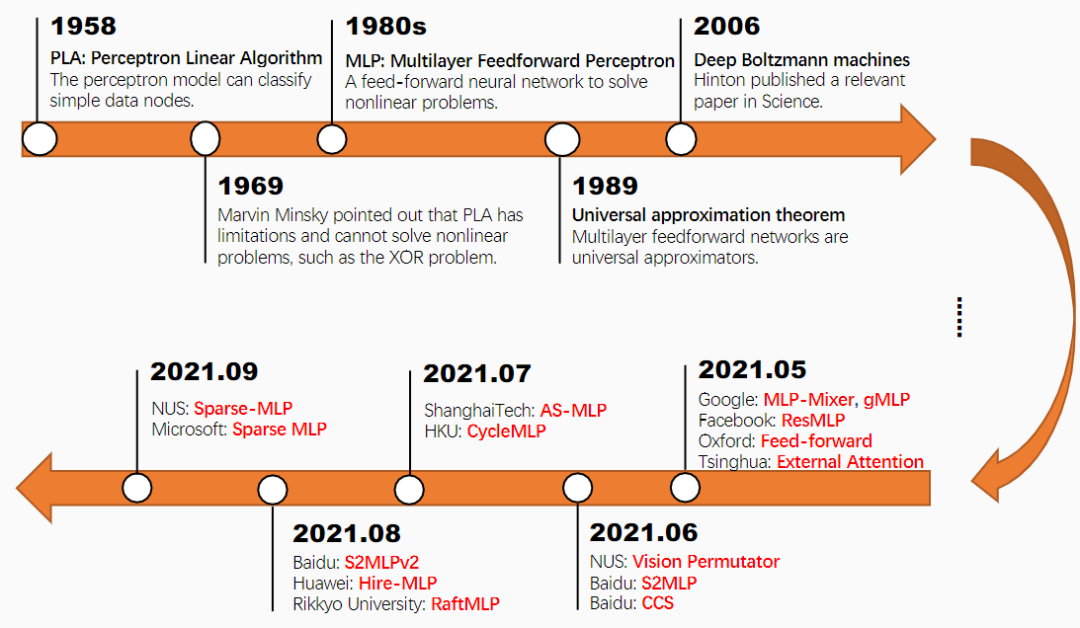
多层感知机(MLP)或全连接(FC)网络是历史上第一个神经网络结构,由多层线性层和非线性激活叠加而成,但受到当时硬件计算能力和数据集大小的限制,这颗明珠被埋没了数十年。
这场人工智能变革也带来了一次AI范式的转换,从手工抽取特征到CNN自动抽取局部特征,基于深度学习的计算机视觉的就是利用多层感知机的计算模型来模拟大脑感知和理解视觉信息的过程。
为了更好地解释多层前馈网络,研究者通过数学理论对多层前馈网络进行了分析,得出多层前馈网络是通用的近似网络(universal approximators)。一些研究结果表明,不同形式和复杂度的多层感知机可以很好地实现任意一个连续函数,但前提是有足够数量的神经元可用。
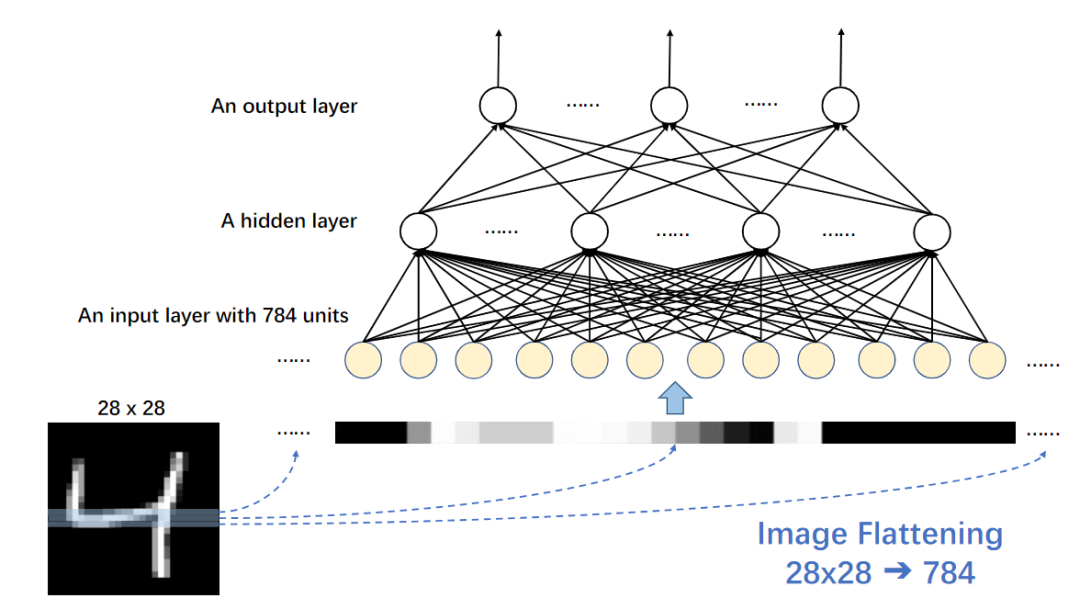
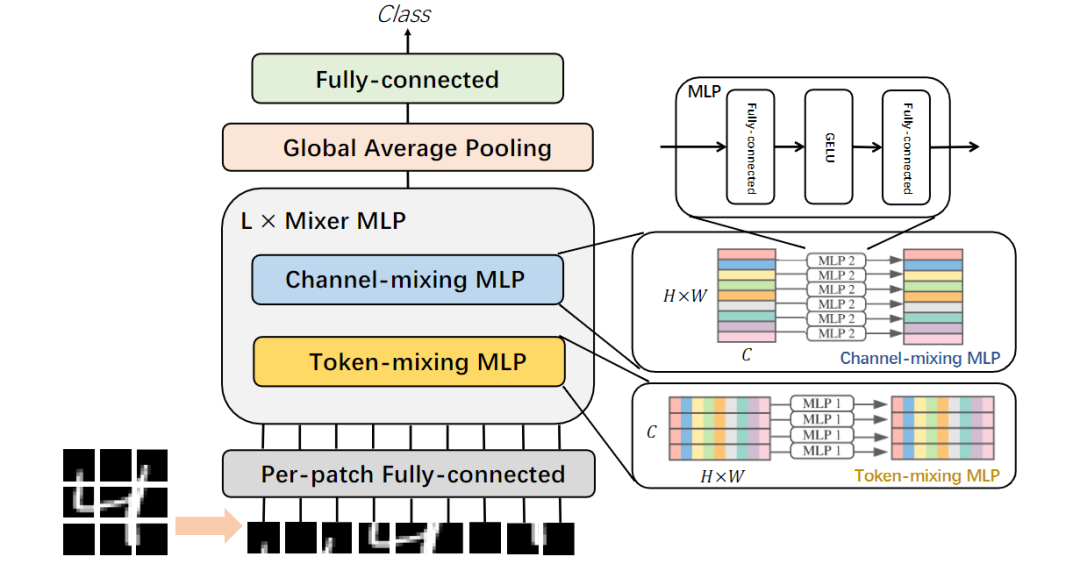
多层感知机最早是在MNIST上进行测试的一个分类器,将28×28的图像按行平展成一个一维矢量,这个矢量被视为初始节点然后经过一个全连接层。
在当年的神经网络通常只有很少的几层网络,并且每层网络内只有少数几个神经元,在CPU核心频率比今天慢上百倍或数千倍时,MLP就能被训练出来了,更不用说现在我们还有了GPU和TPU这种大杀器。
在研究过程中发现,MLP具有计算密集的特点,并且在数据量不足时容易过度拟合。Hinton提出使用预训练和微调的方式来创建一个深度自编码器来解决问题。
然而,输入平坦化(input flattening)仍然是MLP模型的一个问题,并限制了输入图像只能是固定分辨率。由于当时可用的硬件和数据仍然有限,MLP没有看到春天的到来,人工智能就进入寒冬了。
几年后,随着计算能力的提高,并且可以用更大的数据集(如ImageNet),直接导致模型训练范式的转变,卷积神经网络(CNN)也是这一范式的代表模型。
卷积神经网络以灵活、可训练的结构取代了手工设计的特征选择。CNN固有的不变性和局部连通性等有助于图像特征提取。
虽然CNN已经成为计算机视觉领域上的标准模型,但在2020年,Vision Transformer(ViT)的出现引发了新一轮范式转变(paradigm shift)。
ViT及其变体基于自注意层,将全局感知引入计算机视觉,其在各大图像分类基准上表现的更强。
在这些范式转变中,人工干预逐渐减少,性能也逐渐提升。
但天下没有免费的午餐,ViT的胃口更大,需要更大的计算量、更多的训练数据才能表现的更好。
2021年5月,当Transformer的问题还没敲定时,MLP又回来了,带着更多的隐藏层和更多样的(compromise)平坦输入。
几乎所有的研究机构(包括Google、牛津大学、清华大学、Meta等等)同时提出一个问题:
卷积层和注意力层有必要吗?当前是否已经准备好迎接下一个范式的转换了?
研究人员只需要在patch上简单地堆叠一些全连接层就可以在ImageNet上得到只比CNN和ViT弱一点点的模型。这种纯粹的MLP架构模型不仅保留了全局感知的能力,还引入了一些归纳偏差(inductive bias)。
学习算法的归纳偏差是一组假设,学习者使用这些假设来预测给定输入的输出,而这些输入是他们训练过程中没有遇到的。深度MLP进一步消除了这些假设,并允许网络从原始数据中学习权重。
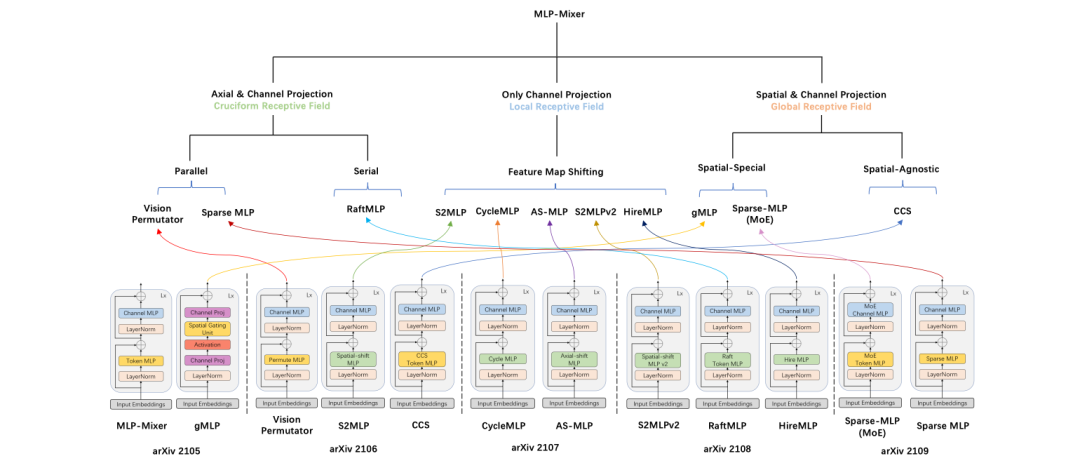
为了回答这个问题,清华大学的研究人员写了一篇survey,重点是全面概述最新的visual deep MLP模型,并阐明deep MLP的最新发展。
文中首先回顾了传统的MLP,并简要概述了过去十年中的范式转变,有助于读者理解最新的网络设计。
然后回顾了最近的一些模型模型的设计,描述了MLP、卷积和自我注意机制之间的区别和联系,并介绍了纯深层MLP体系结构面临的瓶颈和挑战。比较各种深度MLP变体的块设计,分析它们在设计实现、计算复杂性和感受野方面的异同。从内部到外部,从宏观角度分析了块体堆叠的发展,并将其分为单阶段、两阶段和金字塔类型。
此外,文章还比较和讨论了基于MLP、基于CNN和基于Transformer的不同模型的性能。
文章作者郑海涛是来自清华大学深圳国际研究生院的副教授、博士生导师、智能语义挖掘技术工程实验室副主任。2004年于中山大学计算机软件专业硕士毕业,2009年韩国首尔国立大学医疗信息学专业博士毕业。
研究方向包括网络科学、语义网、信息检索、机器学习、医疗信息及人工智能等。博士学习期间被授予韩国政府BK奖学金(Brain Korea Scholarship),主持了国家自然科学基金和教育部博士点基金各一项,担任国家863项目副组长。
研究结果表明,目前的数据量和计算能力还不足以支持纯MLP模型的最佳学习,人工干预仍然有着重要的影响,但还有一些问题需要研究。
视觉裁剪设计(Vision Tailored Designs)
在目前的数据量和计算量下,人类的指导仍然很重要,能够有效结合其他神经网络的架构的优势。当前的深层MLP体系结构可能仍然是一种用于短期和长期依赖的选择,但还需要进一步的研究以使它们更有效地用于视觉输入。
研究人员认为在未来,研究社区应侧重于如何将短期和长期依赖结合起来,因为局部细节有助于我们理解单个物体,物体在整个视野中的相互作用对我们的判断仍然很重要。需要注意的是,全连接层的权重取决于位置,并且也与图像分辨率相对应,因此很难转移到下游任务。
硬件高效设计(Hardware Efficient Designs)
从实验室到日常生活,基于MLP的网络需要更密集的计算,所以如果想要把模型从实验室搬到消费者面前,需要将它们能够部署到边缘设备和资源受限的环境,如收集等。目前,视觉领域的 MLP缺乏这种高效的硬件设计,无法将其无缝部署到资源受限的设备中。
纯MLP模型如何进行低精度训练和推断?纯MLP模型如何进行知识蒸馏?如何使用Nerual Architecter Search(NAS)设计更高效、更轻重量的MLP模型?找到这些问题的答案也许能有所帮助。
另一个可以研究的方向是更深入地分析和比较网络学习的filter以及产生的特征图。纯MLP模型延续了从模型中去除手工视觉特征和归纳偏差的长期趋势,并依赖于从原始数据中学习。
数学解释和可视化分析都有助于理解神经网络可以在较低的优先级下自由地从大量原始数据中学习到什么。这有助于确定过去的一些人工优先级是正确的还是不正确的,并可能提供未来网络改进方向设计选择上的指导方向。
纯MLP模型需要大量的训练数据,在小数据集上很容易过度拟合。出于这些原因,自监督的预训练将会非常有用。预训练有助于泛化,标签中非常有限的信息仅用于微调整权重。考虑到计算成本,对比式方法似乎优于生成式方法。
目前,许多对比学习框架都是针对CNN 的,特征向量的相似性被用作训练目标。
以前的比较学习方法对纯MLP模型是否仍然有效?能为MLP设计一种更好的自我监督培训方法吗?此外,Hinton提出的基于能量的预训练方法能否再次应用?
研究人员认为自监督学习将是加速MLP模型发展的一个很好的推动力。
参考资料:
https://arxiv.org/abs/2111.04060
![]()