【泡泡图灵智库】体积实例感知语义建图与3D对象发现
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Volumetric Instance-Aware Semantic Mapping and 3D Object Discovery
作者:Grinvald, Margarita; Furrer, Fadri;Novkovic, Tonci
Chung, Jen Jen;Cadena, Cesar;Siegwart, Roland;Nieto, Juan
来源:arXiv 2019
播音员:
编译:张蕾
审核:林瑞豪
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——Volumetric Instance-Aware Semantic Mapping and 3D Object Discovery,该文章发表于arXiv preprint arXiv:1903.00268 (2019)。
为了在现实世界环境中自主地导航和动态规划,机器人需要能够稳健地感知和映射复杂的,非结构化的周围场景。除了构建观察到的场景的几何表达外,为了对环境具有真正功能性的理解,关键在于在建图过程中使用更高层级的实体,例如单个对象实例。我们提出了一种使用RGB-D相机进行在线扫描,逐步构建体积对象中心地图的方法。首先,每帧分割原理结合了无监督的几何方法和实例感知的语义对象预测。这允许我们从已知类的集合和其他以前看不见的类别中检测和分割元素。接下来,数据关联步骤跟踪不同帧的预测实例。最后,地图集成策略将有关其3D形状,位置以及语义类(如果可用)的信息融合到全局地图中。对公开数据集的评估表明,所提出的用于构建实例级语义地图的方法能够与最先进的方法媲美,同时还能够发现看不见的类别对象。在真实世界的机器人建图设置下进一步评估该系统,其定性结果表现了该方法的在线特性。
主要贡献
一种组合几何-语义分割方案,可将对象检测扩展到以前看不到的新类别。
用于跟踪和匹配跨多个帧的实例预测的数据关联策略。
分别在公共数据集和在线机器人建图设置下,评估该框架。
算法流程
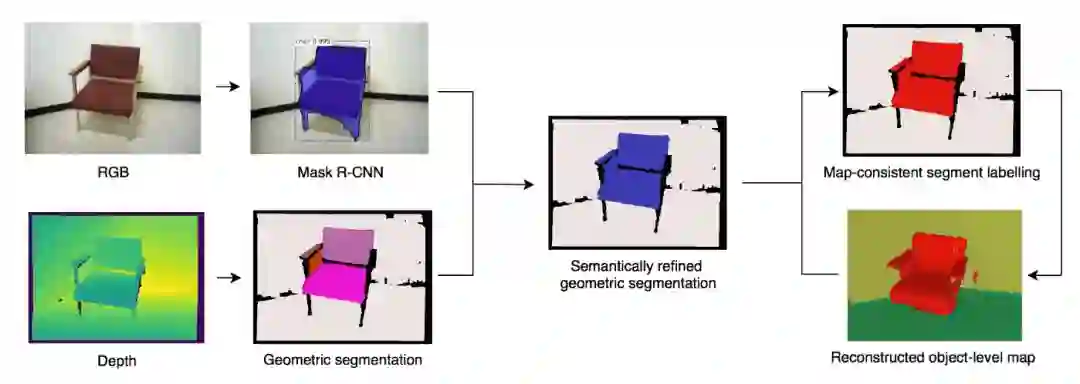
图1 本文方法的增量对象建图过程
对每一个RGB-D帧,增量对象建图的过程包含4个步骤: 1)几何分割;2)语义实例感知分段细化;3)数据关联;4)地图融合。
1. 几何分割
在假设现实世界物体呈现整体凸面几何形状的基础上,按照[4]中介绍的基于几何的方法将每个新来的深度帧分解为一组物体形状的凸三维分割片段。
[4] “Incremental Object Database: Building 3D Models from Multiple Partial Observations,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
2.语义实例感知分段细化
为了补充具有语义对象实例信息的每个深度帧的无监督几何分割,使用Mask R-CNN框架处理相应的RGB图像。 网络检测并分类各个对象实例,并为每个实例预测一个带语义注释的分段掩码。
3.数据关联
这里提出了一个数据关联步骤,用于跟踪相应的几何段和跨帧的预测对象实例。我们定义了一组几何标签L和一组对象实例标签O,它们在整个建图过程中保持有效。
4.地图融合
在当前帧中发现的3D片段(其中一些富含类别和实例信息)被融合到全局体积图中。 为此,通过另外编码对象分段信息,来扩展基于Voxblox TSDF的稠密地图框架。 在使用已知的相机姿势将片段投影到全局TSDF体积中之后,根据[4]中介绍的方法,更新对应于每个投影3D点的体素,以存储输入的几何片段标签信息。
主要结果
1. 实例感知语义分割
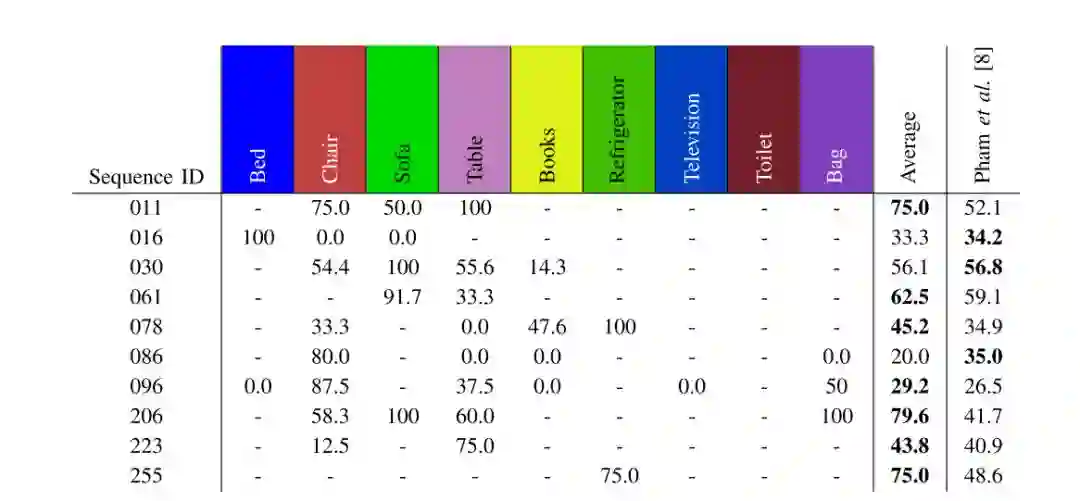
图2 3D语义实例分割方法比较
2. 在线重建与实例建图
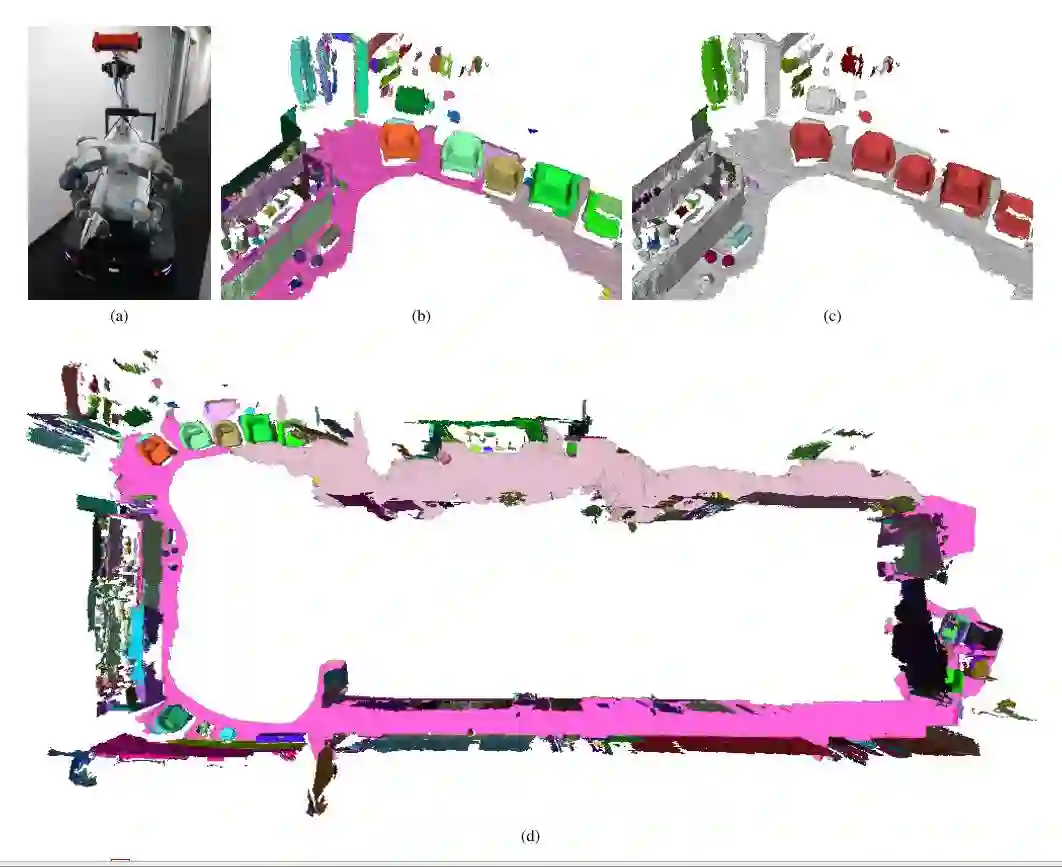
图3 在线建图实验

Abstract
To autonomously navigate and plan interactions in
real-world environments, robots require the ability to robustly perceive and map complex, unstructured surrounding scenes. Besides building an internal representation of the observed scene geometry, the key insight towards a truly functional understanding of the environment is the usage of higher-level entities during mapping, such as individual object instances. We propose an approach to incrementally build volumetric object- centric maps during online scanning with a localized RGB-D camera. First, a per-frame segmentation scheme combines an unsupervised geometric approach with instance-aware semantic object predictions. This allows us to detect and segment elements both from the set of known classes and from other, previously unseen categories. Next, a data association step tracks the predicted instances across the different frames. Finally, a map integration strategy fuses information about their 3D shape, location, and, if available, semantic class into a global volume. Evaluation on a publicly available dataset shows that the proposed approach for building instance-level semantic maps is competitive with state-of-the-art methods, while additionally able to discover objects of unseen categories. The system is further evaluated within a real-world robotic mapping setup, for which qualitative results highlight the online nature of the method.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



