2篇论文验证:组合大规模蛋白质预训练模型(ESM+ProtTrans)编码,预测效果最好
01
ESM-1v+ProtTrans蛋白质预训练模型预测致病突变
近日bioRxiv预印版发表了题为“E-SNPs&GO: Embedding of protein sequence and function improves the annotation of human pathogenic variants”,通过组合两种蛋白质预训练方法(ESM-1v与ProtTrans)的编码、GO编码预测致病变异,在现有方法上得到了最好的效果。

E-SNPs&GO是一种新颖的方法,给定输入蛋白质序列和单个残基变异,可以预测变异是否和疾病有关,该方法首次采用完全基于蛋白质语言模型和嵌入技术的输入编码,专门设计用于编码蛋白质序列和GO功能注释。
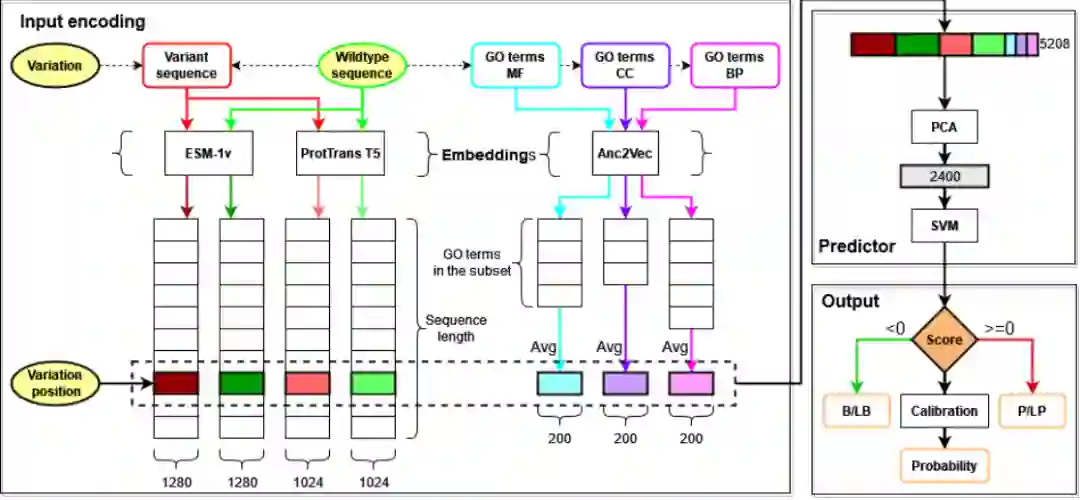
输入(野生型、变异、变异位点)为黄色。该体系结构包括输入编码、预测器和输出。野生型序列(绿色)和变异序列(红色)用ESM-1v和ProtTrans T5建模。GO功能注释(蓝色MF(分子功能),紫色CC(细胞成分),粉红色BP(生物学过程))用Anc2Vec建模。虚线框内的向量(用不同的颜色比标记)表示野生型序列的变异位点和GO terms的平均,将野生型序列的变异位点和GO terms的平均拼接在一起,以获得由1280*2+1024*2+200*3=5208个特征组成的最终表示。
该向量被输入到预测器,预测器包括一个主成分分析(PCA)来降低输入维度(从5208降到2400)以及一个支持向量机(SVM),作为输出,将二元分类为良性/可能良性(B/LB,负类,得分<0)或致病性/可能致病性(P/LP,阳性,得分>=0)。作者应用lsotonic Regression来获得校准的概率。
为了选择最佳的输入编码,作者进行了不同的实验来测试各种组合输入特征。使用不同的输入特征,用交叉验证训练了几个独立的SVM+PCA模型,并使用MCC评分选择最优模型。GO term提供了全局蛋白质信息。它们的嵌入表征没有考虑特定的变异位点。如果仅考虑平均嵌入GO term的向量进行预测,则预测性能非常低,MCC为0.27。不同的输入编码对应不同的预测器,其执行方式不同。
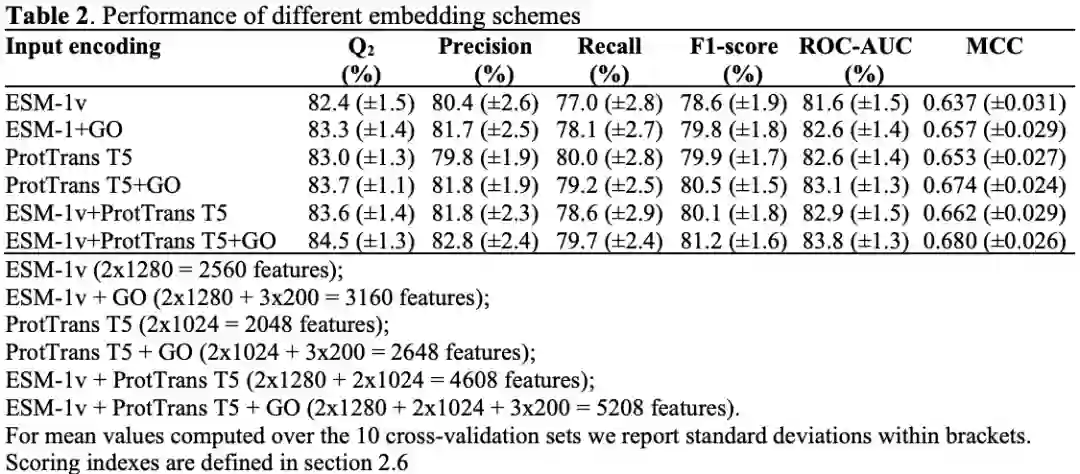
GO嵌入表征包含在最终的输入,MCC都会提高2或3个百分点(比较ESM-1v,ProTrans T5和ESN-1v+ProTrans T5(带GO编码或不带GO编码))。
最后选择用ESM-1v+ ProtTrans T5 + GO编码训练的模型作为最优模型。
02
ESM-1b+ProtTrans蛋白质预训练模型预测蛋白质二级与三级结构属性

为了丰富序列信息,蛋白质语言模型已经成为多序列比对的可替代方法用来丰富的编码序列信息,以及改进下游预测任务,如生物物理、结构和功能特性。
这里作者展示了将传统one-hot编码与两种不同的语言模型(ProtTrans和ESM-1b)的嵌入相结合,在预测蛋白质1D二级和三级结构特性(包括骨架扭转角、溶剂可及性和接触数)的准确性上超越单序列技术。
这一巨大的改进使得基于多序列比对生成的序列谱预测这些1D结构特性的精度达到或优于当前最先进的技术。二级和三级结构特性的高精度预测表明,在没有同源序列的情况下,可以对蛋白质结构进行高精度预测,这是后AlphaFold2时代的剩余阻碍。
作者将蛋白质序列的one-hot编码、蛋白质序列语言模型ESM-1b、ProtTrans模型的输出拼接,作为下游任务分类和回归模型的输入。
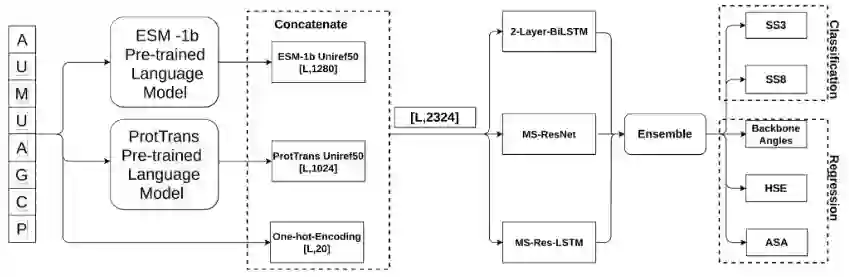
其中one-hot的维度为L*20,其中L为蛋白质的长度。ESM-1b的嵌入uniref50数据集上训练的模型生成的,并且输出维度大小为L*1280。ProtTrans模型也在Uniref50进行了训练,并使用T5-XL模型生成嵌入L*1024的大小,将这些特征串联起来,达到大小为L*2324的最终输入特征。
分类输出是从分类模型中提取出来的,其中有11个输出节点专门用于的蛋白质的二级结构。使用蛋白质二级结构字典(DSSP)来指定三态(SS3)和八态(SS8)二级结构。作者还预测了回归范畴的一堆结构性质。包括溶剂可及表面积(ASA)、蛋白质骨架角(ψ、φ、θ和τ)、半球暴露(HSE)和接触数(CN)。这些输出与之前的SPOT-1D5和SPOT-1D-Single方法中的预测相同。
作者开发的SPOT-1D-LM与基于单序列的预测因子SPOT-1D-single、ProteinUnet,SPIDERSingle3,PSIPRED-single和ASA-Quick方法进行了比较。也与基于profiled的方法SPOT-1D和NetSurfP-2.0进行了比较(对应代码在下面)。
在预测三态(SS3)和8态(SS8)下的二级结构、溶剂可及性(ASA)、半球暴露上升(HSE-u)、下降(HSE-d)、接触数(CN)方面的性能,TEST2018的主干角(ψ、φ、θ和τ)。性能指标包括SS3和SS8的精度、ASA、HSE-u、HSE-d和CN的相关系数以及角度的平均绝对误差。

作者基于ESM-1b、ProtTrans、one-hot组合表征的方法在多项任务都取得了最优的结果。
03
代码链接
所有上述方法代码地址:https://github.com/jas-preet/ SPOT-1D-Single, https://codeocean.com/capsule/2521196/tree/v1, https://servers.sparks-lab. org/downloads/SPIDER3-Single_np.tgz, http://bioinfadmin.cs.ucl.ac.uk/downloads/psipred/, http://mamiris.com/GENN+ASAquick.tgz, https://sparks-lab.org/downloads/, and https://services. healthtech.dtu.dk/service.php?NetSurfP-2.0。
如果要了解ESM-1b和ProtTrans预训练模型,翻看下面两篇公众号文章:
Facebook 2.5亿个蛋白质序列的预训练模型:自监督语言模型学习生物学特性
伯克利Roshan Rao 157页博士论文:训练,评估和理解蛋白质序列的进化模型
代码地址:
https://github.com/facebookresearch/esm
https://github.com/agemagician/ProtTrans

