
题目: Should All Cross-Lingual Embeddings Speak English?
摘要:
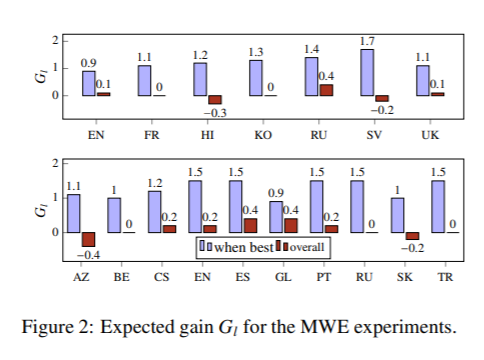
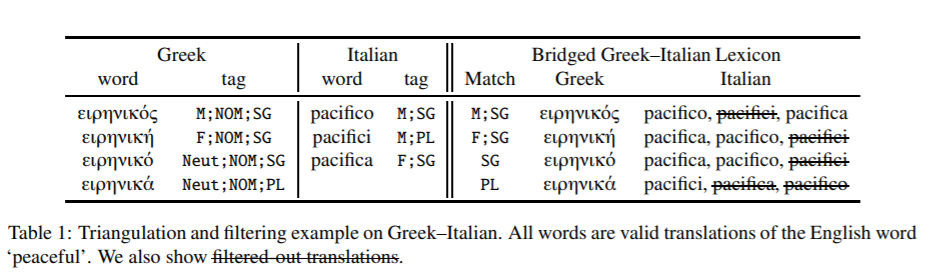
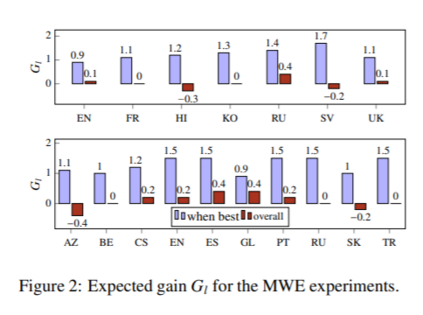
最近关于跨语言词嵌入的研究大多以英语为中心。绝大多数词汇归纳评价词典都介于英语和另一种语言之间,在多语言环境下学习时,默认选择英语嵌入空间作为中心。然而,通过这项工作,我们对这些实践提出了挑战。首先,我们证明了中心语言的选择对下游词汇归纳和零标注词性标注性能有显著的影响。其次,我们都扩展了一个以英语为中心的标准评估词典集合,以包括所有使用三角统计的语言对,并为代表不足的语言创建新的词典。对所有这些语言对的现有方法进行评估,有助于了解它们是否适合对来自遥远语言的嵌入进行校准,并为该领域带来新的挑战。最后,在我们的分析中,我们确定了强跨语言嵌入基线的一般准则,扩展到不包括英语的语言对。
成为VIP会员查看完整内容
相关内容

相关VIP内容
相关资讯
相关论文