CoNLL 2018 | 最佳论文揭晓:词嵌入获得的信息远比我们想象中的要多得多
选自arXiv
作者:Mikel Artetxe
机器之心编译
参与:李亚洲、路雪
本文经机器之心(微信公众号:almosthuman2014)授权转载,禁止二次转载
CoNLL 是自然语言处理领域的顶级会议,每年由 SIGNLL 组织举办。CoNLL 2018 大会将于 10 月 31 日-11 月 1 日在比利时布鲁塞尔举行,地点与 EMNLP 2018 一样(EMNLP 2018 将于 10 月 31 日-11 月 4 日举行)。
昨日,CoNLL 公布了最佳论文,由来自西班牙巴斯克大学 IXA NLP 组的 Mikel Artetxe 等人获得。该论文展示了词嵌入模型能够捕获不同层面的信息(如语义/句法和相似度/相关度),为如何编码不同的语言信息提供了新的视角,该研究还研究了内外部评估之间的关系。
近年来,词嵌入成为自然语言处理的核心主题。业内提出了多种无监督方法来高效地训练单词的密集型向量表征,且成功地应用到语法解析、主题建模、文档分类等多类任务。
虽然从理论角度理解这些模型是更加活跃的研究路线,但这些研究背后的基本思路都是为类似的单词分配类似的向量表征。由此,大部分词嵌入模型依赖来自大型单语语料库的共现统计信息(co-occurrence statistics),并遵循分布假设,也就是相似单词倾向于出现在相似语境中。
然而,上述论点没有定义「相似单词」的含义,且词嵌入模型实际中应该捕捉哪种关系也不完全清楚。因此一些研究者在真正相似度(如 car - automobile)与关联度(如 car - road)之间进行区分。从另一个角度来说,词语相似度可聚焦在语义(如 sing-chant)或者句法(如 sing-singing)上。我们把这两个方面作为相似度的两个坐标轴,且每一个坐标轴的两端为两种性质:语义/句法轴和相似度/关联度轴。
本论文提出了一种新方法来调整给定的任意嵌入向量集,使其在这些坐标轴中靠近特定端点。该方法受一阶和二阶共现研究的启发,可推广为词嵌入向量线性变换的连续参数,我们称之为相似度阶(similarity order)。虽然业内提出了多种学习特定词嵌入的方法,但之前的研究明确地改变了训练目标,且总是依赖知识库这样的外部资源。而本论文提出的方法可用做任意预训练词嵌入模型的后处理,不需要任何额外资源。同样,该研究表明,标准的词嵌入模型能够编码不同的语言信息,但能够直接应用的信息有限。此外,该研究也分析了该方法与内部评估和下游任务的关系。该论文主要贡献如下:
1. 提出了一个具备自由参数的线性变换,能够调整词嵌入在相似度/关联度和语义/句法坐标轴中的性能,并在词汇类推数据集和相似度数据集中进行了测试。
2. 展示了当前词嵌入方法的性能受到无法同时显现不同语言信息(例如前面提到的坐标轴)的限制。该研究提出的方法表明,词嵌入能够捕获的信息多于表面显现出的信息。
3. 展示了标准的内部评估只能给出一个静态的不完整图景,加上该研究提出的方法能够帮助我们更好地理解词嵌入模型真正编码哪些信息。
4. 展示了该方法也能运用到下游任务中,但相比于使用一般词嵌入作为输入特征的监督系统,其效果在直接使用词嵌入相似度的无监督系统上更显著,因为监督系统有足够的表达能力来学习最优变换。
总之,该研究揭示了词嵌入如何表示不同语言信息,分析了它在内部评估和下游任务中所扮演的角色,为之后的发展开创了新机遇。
论文:Uncovering divergent linguistic information in word embeddings with lessons for intrinsic and extrinsic evaluation

论文链接:https://arxiv.org/abs/1809.02094
摘要:随着词嵌入最近取得成功,有人认为根本不存在词的理想表征,因为不同的模型倾向于捕捉不同且往往互不兼容的方面,如语义/句法和相似性/相关性。本论文展示了每个词嵌入模型捕获的信息多于直接显现的信息。线性转换无需任何外部资源就能调整模型的相似度阶,因此能够调整模型以在这些方面获得更好的结果,这为词嵌入编码不同的语言信息提供了新的视角。此外,我们还探索了内、外部评估的关系,我们在下游任务中的变换效果在无监督系统中的效果优于监督系统。
内部评估
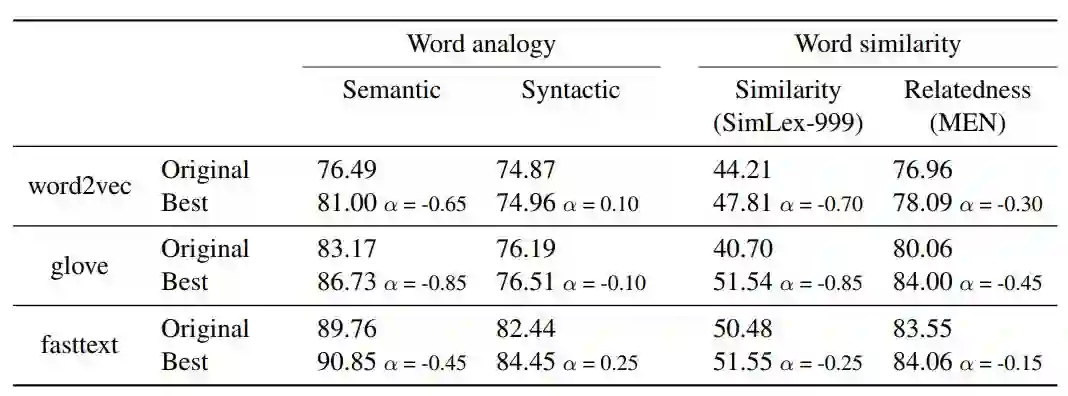
表 1:原始嵌入以及具备对应 α 值的最佳后处理模型的内部评估结果。评估指标是词汇类比任务的准确率和词语相似度的斯皮尔曼等级相关系数。
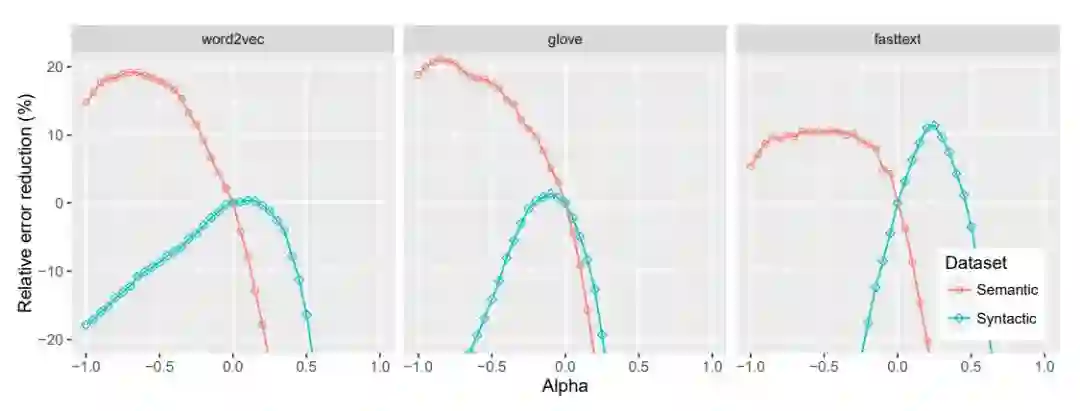
图 1:词汇类比任务中,不同 α 值所对应的相对误差减少,原始嵌入的 α = 0。
外部评估
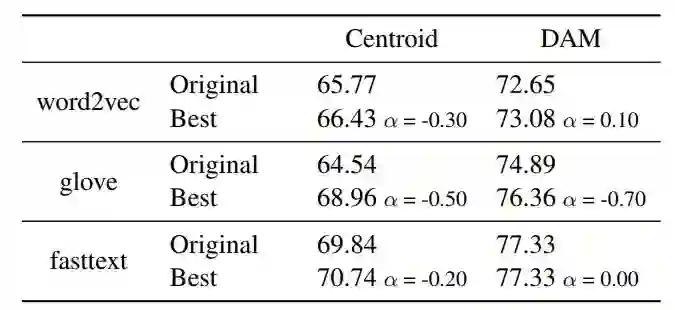
表 2:原始嵌入和具备对应 α 值的最佳后处理模型的语义文本相似度结果,衡量标准为皮尔逊相关系数。DAM 分数是 10 次运行的平均得分。
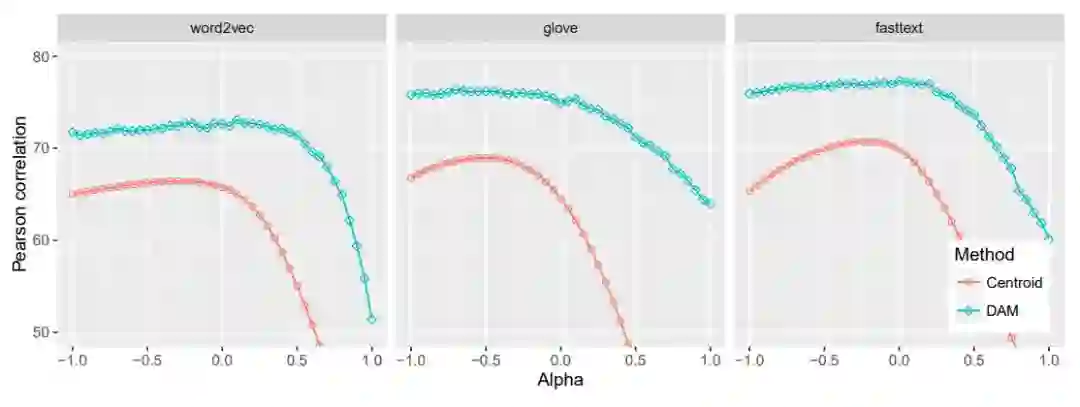
图 3:不同 α 值对应的语义文本相似度结果。DAM 分数是 10 次运行的平均得分。
讨论
我们认为该研究为嵌入编码不同语言信息提供了新的视角,其与内外部评估之间的关系如下所示:
标准内部评估提供的是不同词嵌入模型编码的静态、不完整信息图。
使用预训练嵌入作为特征的监督系统具备足够的表达能力来学习任务的最优相似度阶。
尽管我们的研究展示了嵌入捕获的默认相似度阶对较大的学习系统影响较小,但它未必是最优的整合策略。如果研究者认为某个相似度阶可能更适合某个下游任务,则他/她设计的整合策略很可能鼓励这个相似度阶,我们认为这是未来一个有趣的研究方向。例如,研究者可以设计正则化方法去惩罚预定义相似度阶的较大偏差。


推荐阅读
基础 | TreeLSTM Sentiment Classification
原创 | Simple Recurrent Unit For Sentence Classification
原创 | Attention Modeling for Targeted Sentiment
 欢迎关注交流
欢迎关注交流



