知识在人工智能中起着至关重要的作用。最近,预训练语言模型(PLM)的广泛成功引起了人们对语言模型如何获取、维护、更新和使用知识的极大关注。尽管相关研究数量巨大,但对于知识在语言模型中如何在整个学习、调优和应用过程中循环,仍然缺乏统一的观点,这可能会阻止我们进一步理解当前进展或实现现有限制之间的联系。**本文通过将PLM中的知识生命周期划分为五个关键时期,并调研知识在构建、维护和使用时是如何循环的,来重新审视PLM作为基于知识的系统。**文中系统地回顾了知识生命周期各个阶段的现有研究,总结了目前面临的主要挑战和局限性,并讨论了未来的发展方向。
https://www.zhuanzhi.ai/paper/3eda52f060c0913316b9ae9c375835f5
从根本上说,人工智能是知识的科学——如何表示知识以及如何获取和使用知识。
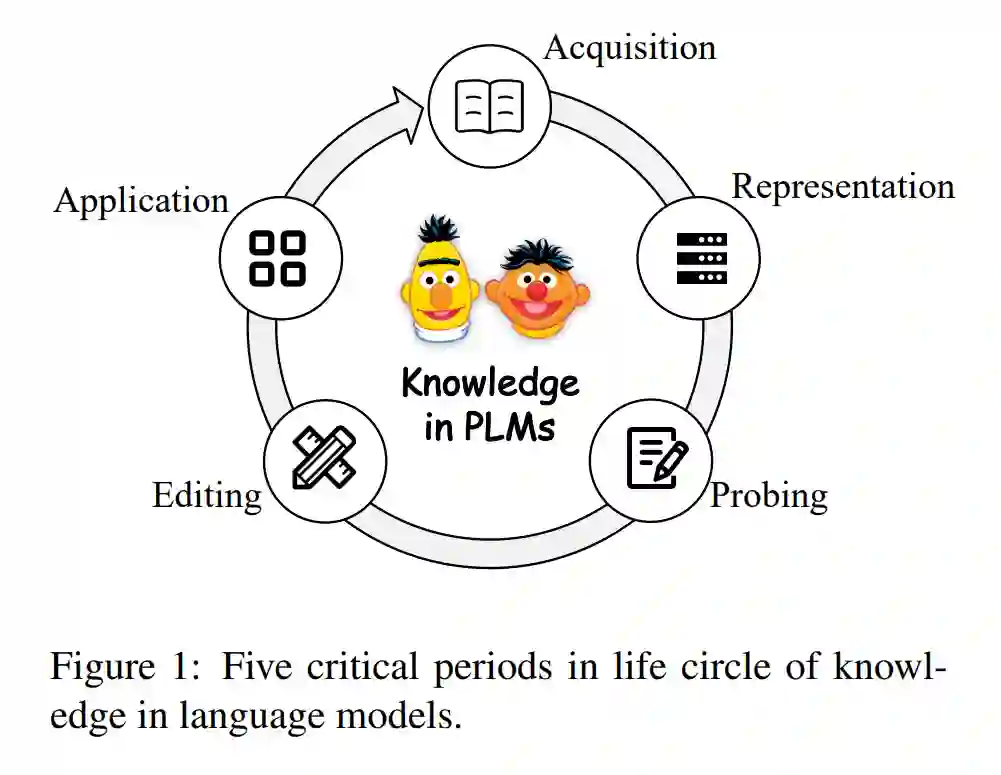
预训练语言模型的成功引起了人们对其隐含知识性质的极大关注。已经有许多研究关注预先训练的语言模型如何获取、维护和使用知识。沿着这些思路,人们探索了许多新的研究方向。例如,知识注入致力于将明确的结构化知识注入到PLMs中(Sun等人,2019;Zhang等人,2019;Sachan等人,2021)。知识探测旨在评估PLMs参数中存储的知识类型和数量(Petroni et al., 2019; Lin et al., 2019; Hewitt and Manning, 2019)。而知识编辑则致力于修改PLMs获得的不正确或不可取的知识(Zhu et al., 2020; De Cao et al., 2021; Mitchell et al., 2021)。尽管有大量的相关研究,但目前的研究主要集中在PLMs中知识过程的一个特定阶段,因此对知识如何在整个模型学习、调优和应用阶段中循环缺乏统一的观点。这种综合性研究的缺乏,使得我们难以更好地理解不同基于知识的任务之间的联系,难以发现PLMs中知识生命周期中不同时期之间的相关性,难以利用缺失的环节和任务来研究PLMs中的知识,也难以探索现有研究的不足和局限性。例如,虽然许多研究试图评估语言模型中的知识,这些语言模型已经进行了预训练,但很少有研究致力于调研为什么PLMs可以在没有任何知识监督的情况下从纯文本中学习,以及PLMs如何表示或存储这些知识。与此同时,许多研究者试图将各种结构性知识明确地注入到PLMs中,但很少有研究提出通过挖掘背后的知识获取机制来帮助PLMs更好地从纯文本中获取特定类型的知识。因此,相关研究可能会过度关注于几个方向,而不能全面理解、维护和控制PLMs中的知识,从而限制了改进和进一步应用。本文从知识工程的角度,系统地回顾了预训练语言模型中与知识相关的研究。受认知科学研究的启发(Zimbardo和Ruch, 1975;和知识工程(Studer et al., 1998;Schreiber等人,2000),我们将预训练语言模型视为基于知识的系统,并研究了知识在预训练模型中获得、维护和使用时如何循环的生命周期(Studer等人,1998;Schreiber et al., 2000)。具体地,我们将预训练语言模型中的知识生命周期划分为以下五个关键时期,如图1所示:
知识获取是指语言模型从文本或其他知识源中学习各种知识的过程。 知识表示研究不同类型的知识如何在plm参数中转换、编码和分布的内在机制。 知识探测,旨在评估当前PLM包含不同类型知识的情况。 知识编辑,试图编辑或删除语言模型中包含的知识。 知识应用,试图从预训练语言模型中提取或利用知识进行实际应用。
对于每一个时期,我们将梳理现有的研究,总结主要的挑战和局限性,并讨论未来的发展方向。基于统一的视角,我们能够理解和利用不同时期之间的紧密联系,而不是将它们视为独立的任务。例如,理解PLMs的知识表示机制有助于研究人员设计更好的知识获取目标和知识编辑策略。提出可靠的知识探测方法,可以帮助我们找到适合PLM的应用,并深入了解其局限性,从而促进改进。通过综述,全面总结当前研究的进展、挑战和局限性,帮助研究人员从一个新的视角更好地理解整个领域,并从统一的角度阐述未来如何更好地规范、表示和应用语言模型中的知识的方向。
我们的贡献总结如下:
建议将预训练语言模型作为基于知识的系统重新审视,并将PLM中的知识生命周期划分为五个关键时期。 对于每个时期,回顾了现有的研究,总结了每个方向的主要挑战和缺点。 基于这篇综述,讨论了当前研究的局限性,并揭示了潜在的未来方向。
概述在本节中,我们将介绍本综述的总体结构,详细描述图2所示的分类法,并讨论每个关键时期的主题。
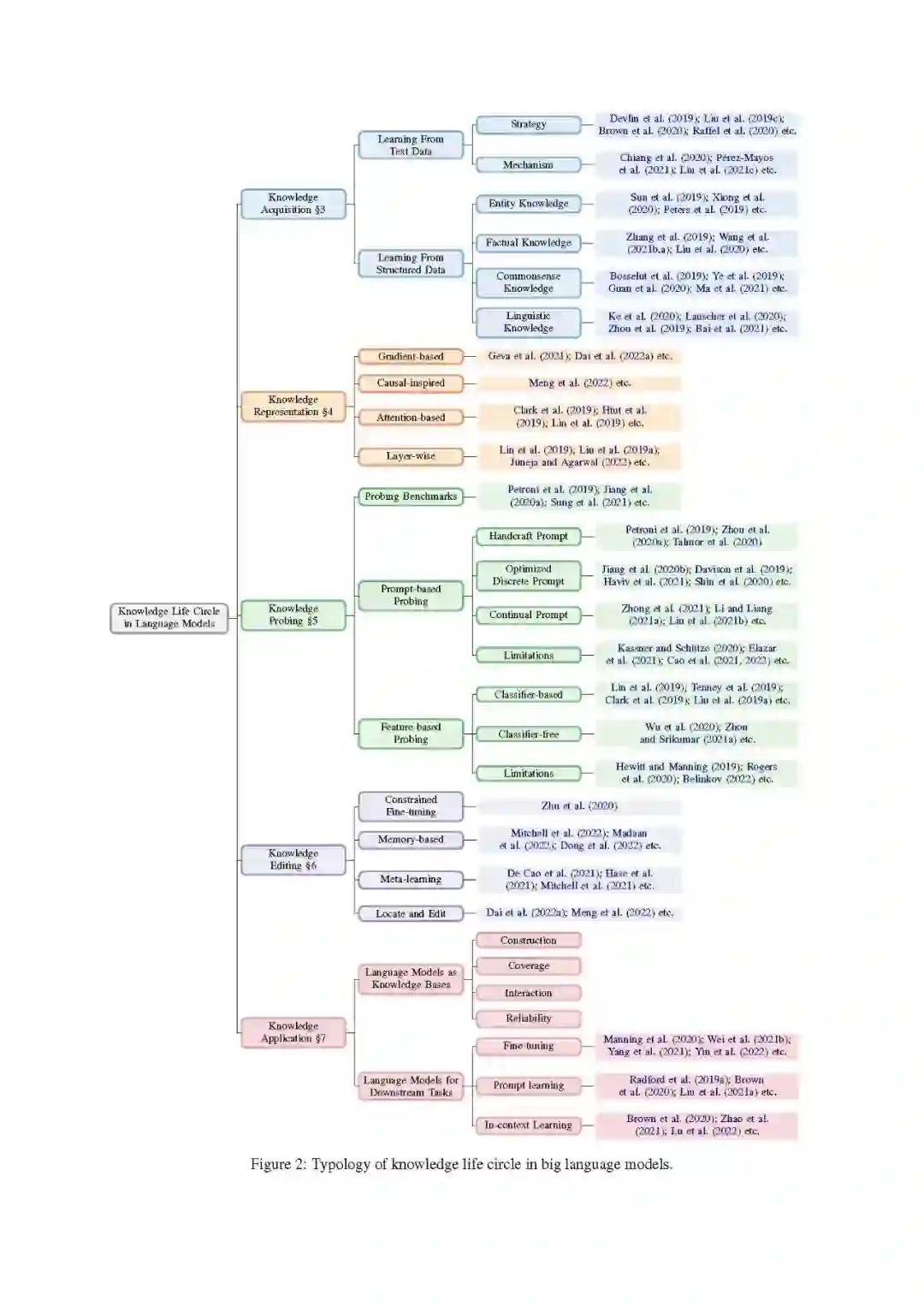
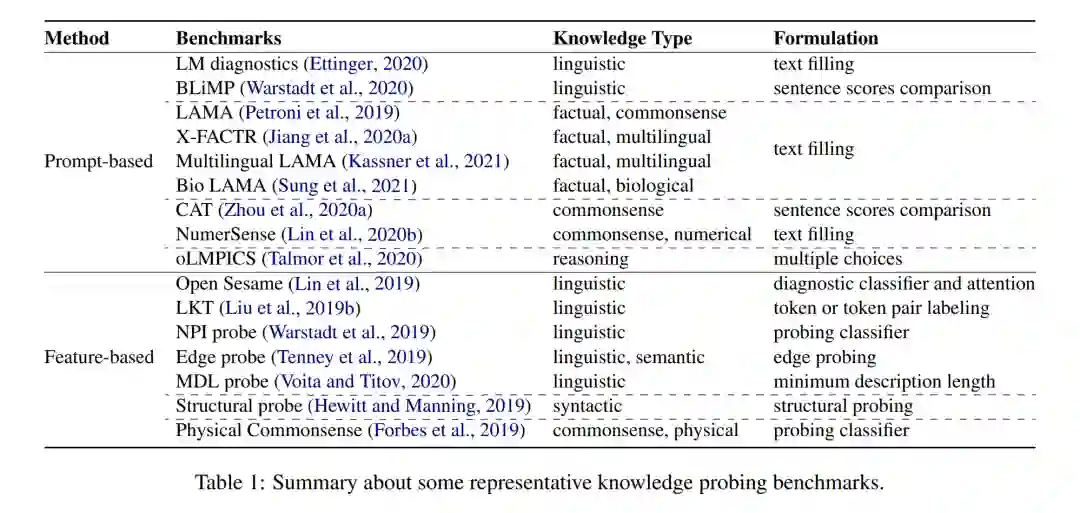
**知识获取是语言模型的知识学习过程。目前,知识获取主要有两种来源:纯文本数据和结构化数据。**为了从文本数据中获取知识,语言模型通常在大规模文本语料库上进行自监督学习(Devlin等人,2019;Liu等人,2019c;Brown等人,2020;Raffel等人,2020)。本综述将重点关注预训练语言模型如何从纯文本中获取知识的方法和机制(Chiang等人,2020;Pérez-Mayos等,2021;刘等,2021c)。为了从结构化数据中获取知识,目前的研究主要集中在从不同类型的结构化数据中注入知识。结构化数据的主要类别包含实体知识(Sun等人,2019;熊等,2020;Peters等人,2019),事实知识(Zhang等人,2019;王志强,杨志强,杨志强;Liu等人,2020),常识知识(Bosselut等人,2019;Ye等人,2019;Guan等人,2020;Ma等人,2021)和语言知识(Ke等人,2020;Lauscher等人,2020;Zhou等人,2019;Bai等人,2021)。我们将在第3节中讨论它们。**知识表示旨在研究语言模型如何在其密集参数中编码、存储和表示知识。**对知识表示机制的研究将有助于更好地理解和控制PLMs中的知识,也可能启发研究者更好地理解人类大脑中的知识表示。目前,PLMs中知识表示分析的策略包括基于梯度的(Geva等人,2021;Dai等人,2022a)、因果启发(孟等人,2022)、基于注意力的(Clark等人,2019;Htut等人,2019;Lin等人,2019)和分层(Lin等人,2019;Liu等人,2019a;Juneja和Agarwal, 2022)方法。我们将在第4节中讨论它们。**知识探测的目的是评估当前的PLMs对特定类型的知识的影响。**目前,对PLMs中的知识进行探测主要采用两种策略:1)基于提示的探测,通常构建知识指示的提示,然后使用这些自然语言表达式查询PLMs (Petroni et al., 2019;Jiang等,2020a;Sung等人,2021;《福布斯》等人,2019;Zhou等,2020a)。例如,用“The capital of France is .”查询PLMs,以评估PLMs是否存储了相应的知识。同时,为了提高plm的性能,一系列研究致力于优化两个离散的提示(Jiang等人,2020b;Davison等人,2019;Haviv等人,2021;Shin等人,2020)和持续空间(Zhong等人,2021;李和梁,2021a;Liu等,2021b)。尽管基于提示的探索得到了广泛应用,但许多研究也指出,仍然存在一些悬而未决的问题,如不一致(Elazar等人,2021;Kassner和Schütze, 2020;Jang等人,2022;Cao等人,2022),不准确(perner等人,2020;钟等,2021;Cao et al., 2021)和不可靠(Cao et al., 2021;Li et al., 2022a),并对基于提示探测的数量结果提出质疑。2)基于特征的探测,通常冻结原始plm的参数,并根据其内部表示或注意力权重评估PLM在探测任务上的表现。我们将现有的基于特征的探测研究分类为基于分类器的探测(Lin等人,2019;Tenney等人,2019;Clark等人,2019;Liu等人,2019a)和无分类器探测(Wu等人,2020;Zhou和Srikumar, 2021a)根据是否引入了额外的分类器。由于大多数方法引入了额外的参数或训练数据,基于特征的探测的主要缺点是结果应归因于PLM中的知识还是通过额外的探测学习到的探测任务。我们将在第5节中讨论它们。
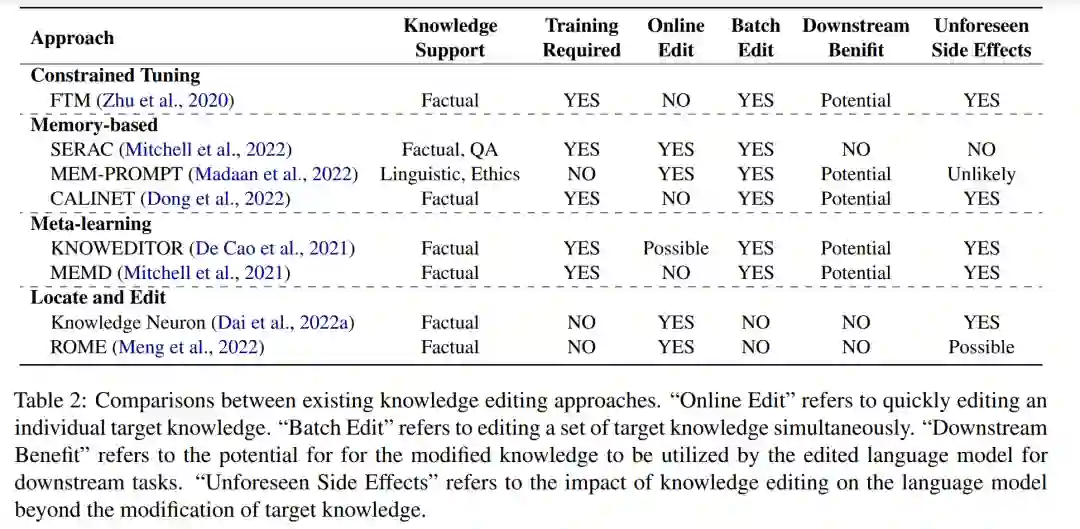
**知识编辑旨在修改产品生命周期中不正确的知识或删除不良信息。**由于PLMs学习到的不可避免的错误和知识的更新,可靠有效的知识编辑方法对PLMs的可持续应用至关重要。目前的方法包括约束微调(Zhu等人,2020),基于记忆的(Mitchell等人,2022;Madaan等人,2022;Dong等人,2022),元学习启发(De Cao等人,2021;Hase等人,2021年;Mitchell等人,2021)和基于位置的方法(Dai等人,2022a;孟等,2022)。我们将在第6节讨论它们。
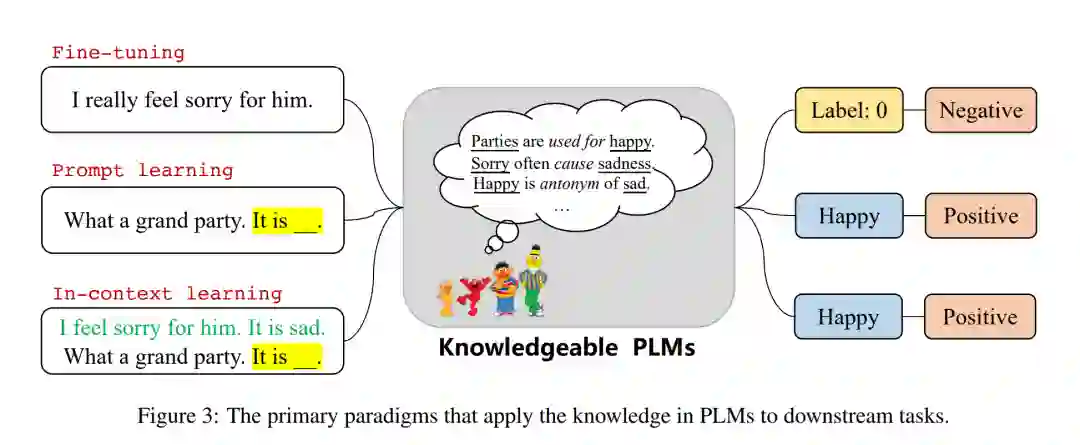
**知识应用旨在从PLMs中提取或利用特定的知识,以使进一步的应用受益。**目前,PLMs中的知识主要有两种应用范式:1)语言模型作为知识库(LMs-as-KBs),将语言模型视为密集的知识库,可以用自然语言直接查询以获得特定类型的知识(Petroni等人,2019;Heinzerling和Inui, 2021年;蒋等人,2020b;王等人,2020;Cao等,2021;Razniewski等人,2021年;AlKhamissi等人,2022)。从构建、覆盖率、交互性和可靠性4个方面对结构化知识库与LMs-as-KBs (Razniewski et al., 2021)进行了全面比较;2)下游任务的语言模型,通过微调直接在下游NLP任务中使用包含特定类型知识的plm (Manning等人,2020;Wei等,2021b;Yang等人,2021;Yin等人,2022),快速学习(Radford等人,2019a;Brown等人,2020;Liu等人,2021a)和上下文学习(Brown等人,2020;Zhao等人,2021;陆等人,2022)。我们将在第7节讨论它们。