
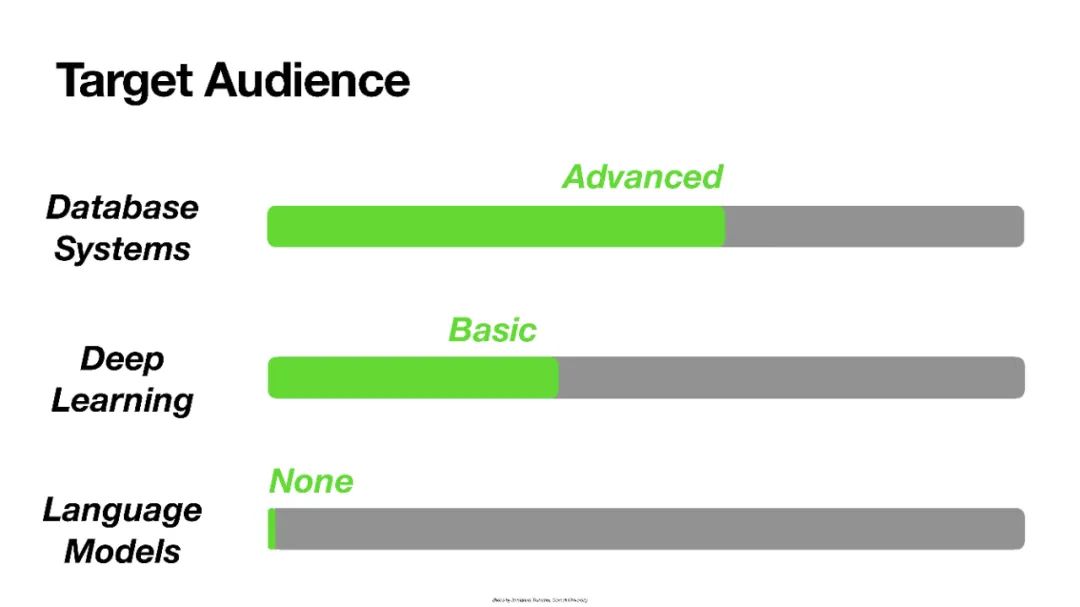
大型语言模型最近在许多自然语言处理基准测试中提高了技术水平。最新一代的模型可以应用于各种任务,几乎不需要专门的训练。该技术为数据管理上下文中的应用程序创造了各种机会。本教程将向参与者介绍语言模型的基本背景,讨论使用语言模型的不同方法,并对可用的库和api进行概述和简短演示。生成自然语言的模型和GPT-3 Codex等完成程序代码或从自然语言指令生成代码的模型都将被考虑在内。最后,本教程将讨论数据库社区最近的研究,这些研究利用了传统数据库系统环境中的语言模型,或提出了基于它们的新系统架构。本教程针对数据库研究人员。不需要有语言模型的背景知识。本教程的目标是向数据库研究人员介绍最新一代的语言模型,以及它们在数据管理领域中的用例。
最近,随着大型“语言模型”的出现,自然语言处理(NLP)领域发生了革命性的变化,这些“语言模型”使用大量的无标记文本[35]进行训练。给定足够多的训练数据和可训练的参数,这样的模型能够处理广泛的任务,很少或不需要专门的训练[2]。这种模型在数据库领域的应用范围非常广泛。它的范围从新的接口[25,30]到新的系统架构[29],基于最新一代语言模型支持的数据表示和处理机制。本教程的目的是向数据库研究人员介绍这些模型提供的可能性,提供使它们可访问的库和api的指针[22,35],并回顾数据库社区利用这些模型的最新研究。本教程将介绍处理和生成自然语言文本的语言模型[4,6],以及从自然语言描述[3]生成程序代码的最新模型。它将包括例子和现场演示,为与会者提供对可解决问题范围的直觉。


成为VIP会员查看完整内容
相关内容
相关VIP内容
相关资讯
相关论文