

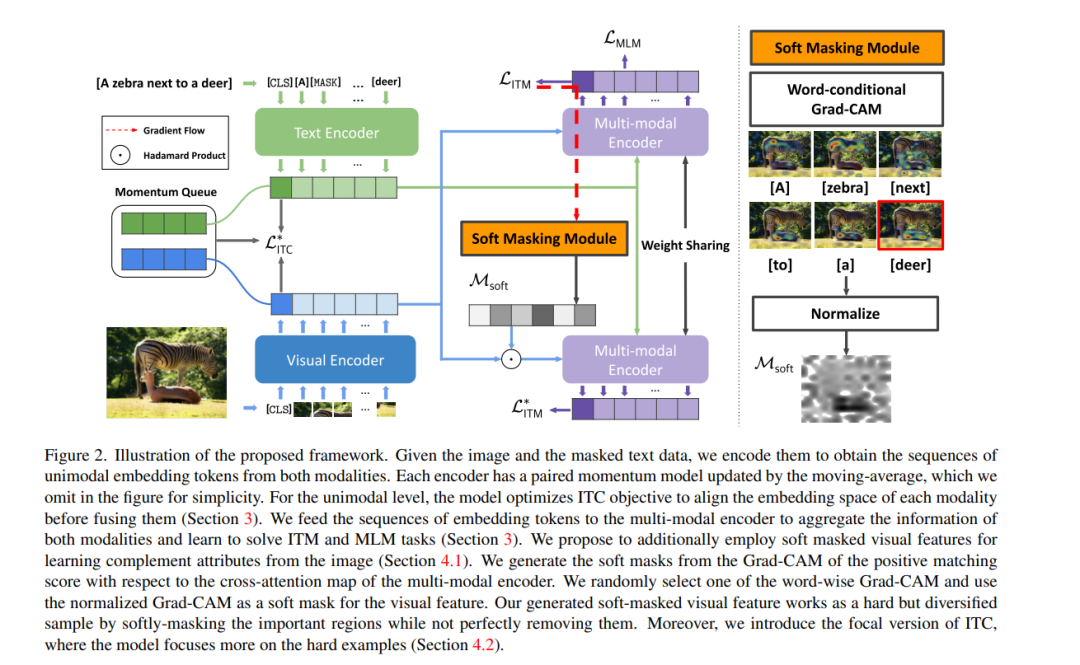
本文提出一种自监督学习框架内的视觉语言表示学习方法,通过引入新的操作、损失和数据增强策略。首先,通过软掩蔽图像中与对应标题中的某个单词最相关的区域,而不是完全删除它们,为图像文本匹配(image text matching, ITM)任务生成多样化的特征。由于该框架只依赖于没有细粒度注释的图像-标题对,通过使用多模态编码器计算单词条件视觉注意来识别每个单词的相关区域。通过提出图像-文本对比学习(ITC)目标的焦点损失,鼓励模型更多地关注难的但多样化的例子,这缓解了过拟合和偏差问题的固有局限性。通过挖掘各种示例,通过屏蔽文本和对图像渲染失真,对自监督学习进行多模态数据增强。这三种创新的结合对学习预训练模型是有效的,导致在多个视觉-语言下游任务上的出色表现。https://arxiv.org/abs/2304.00719
成为VIP会员查看完整内容

相关内容

CVPR 2023大会将于 6 月 18 日至 22 日在温哥华会议中心举行。CVPR是IEEE Conference on Computer Vision and Pattern Recognition的缩写,即IEEE国际计算机视觉与模式识别会议。该会议是由IEEE举办的计算机视觉和模式识别领域的顶级会议,会议的主要内容是计算机视觉与模式识别技术。
CVPR 2023 共收到 9155 份提交,比去年增加了 12%,创下新纪录,今年接收了 2360 篇论文,接收率为 25.78%。作为对比,去年有 8100 多篇有效投稿,大会接收了 2067 篇,接收率为 25%。
Arxiv
42+阅读 · 2023年4月19日
Arxiv
15+阅读 · 2020年2月28日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
15+阅读 · 2020年2月28日