

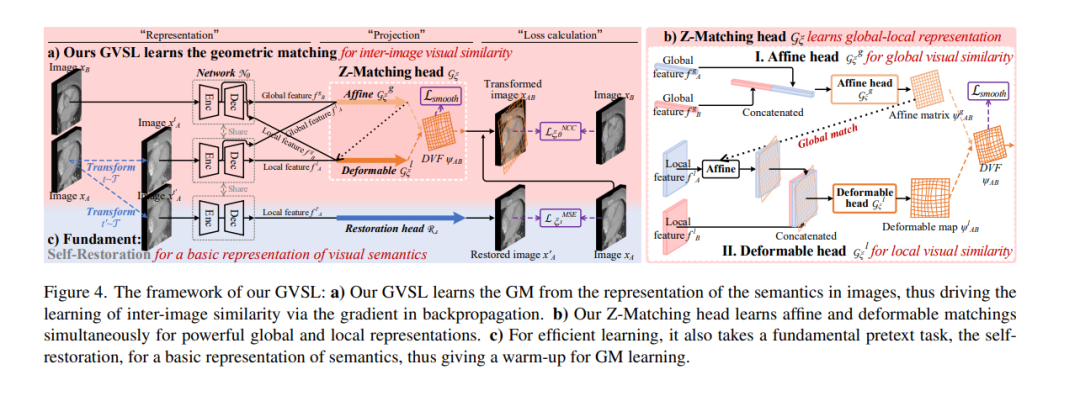
图像间共享大量相同的语义区域,学习图像间相似性对于三维医学图像自监督预训练至关重要。然而,度量中缺乏语义先验以及3D医学图像语义无关的差异性,使得获取可靠的图像间相似性度量具有挑战性,阻碍了相同语义的一致性表示学习。本文研究了这项任务的挑战性问题,即为相同语义特征的聚类效果学习图像之间的一致表示。提出了一种新的视觉相似性学习范式——几何视觉相似性学习,将拓扑不变性先验信息嵌入到图像间相似性的度量中,以实现语义区域的一致表示。为了推动这一范式,文中进一步构建了一种新的几何匹配头——Z-matching头,以协同学习语义区域的全局和局部相似性,指导不同尺度层次的图像间语义特征的高效表示学习。实验表明,通过学习图像间相似性进行的预训练,在四个具有挑战性的3D医学图像任务上产生了更强大的场景内、场景间和全局-局部迁移能力。我们的代码和预训练模型将公开提供。 https://arxiv.org/pdf/2303.00874.pdf
成为VIP会员查看完整内容
相关内容

CVPR 2023大会将于 6 月 18 日至 22 日在温哥华会议中心举行。CVPR是IEEE Conference on Computer Vision and Pattern Recognition的缩写,即IEEE国际计算机视觉与模式识别会议。该会议是由IEEE举办的计算机视觉和模式识别领域的顶级会议,会议的主要内容是计算机视觉与模式识别技术。
CVPR 2023 共收到 9155 份提交,比去年增加了 12%,创下新纪录,今年接收了 2360 篇论文,接收率为 25.78%。作为对比,去年有 8100 多篇有效投稿,大会接收了 2067 篇,接收率为 25%。
Arxiv
0+阅读 · 2023年4月21日
Arxiv
0+阅读 · 2023年4月20日
Arxiv
0+阅读 · 2023年4月20日


相关VIP内容
相关资讯