

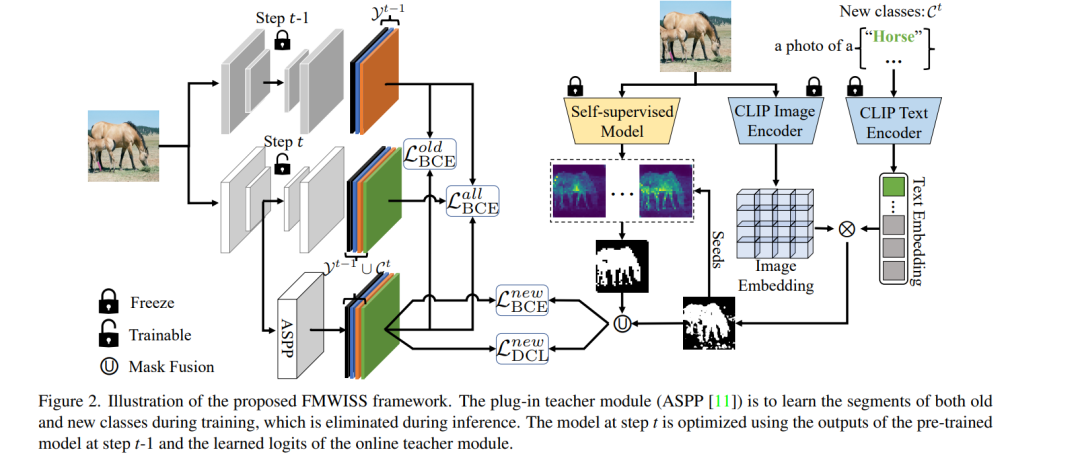
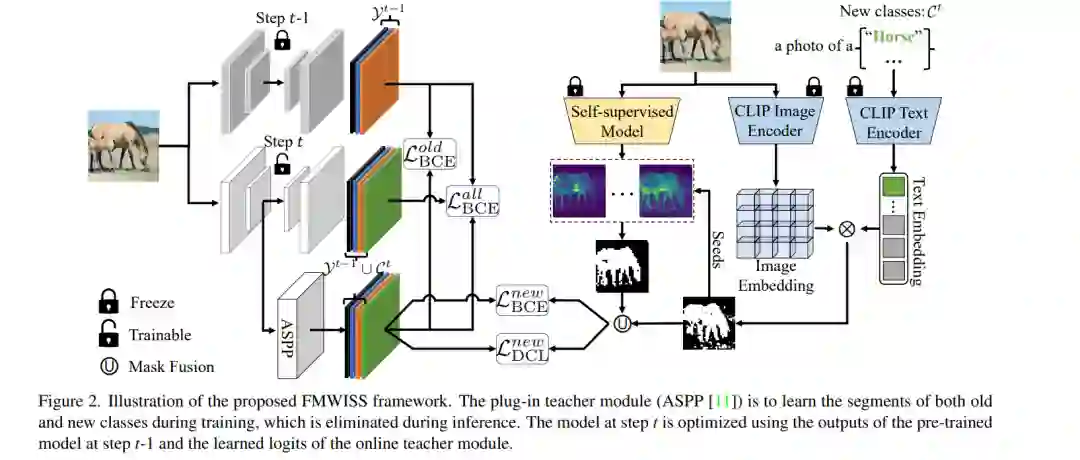
现代语义分割增量学习方法通常基于密集标注来学习新的类别。尽管取得了很好的结果,但逐像素标记是昂贵和耗时的。弱增量语义分割学习(WILSS)是一项新颖而吸引人的任务,旨在从廉价且广泛可用的图像级标签中学习分割出新的类别。尽管效果相当,但图像级标签无法提供定位每个分割的细节,这限制了WILSS的性能。这启发我们思考如何改进和有效利用给定图像级标签的新类的监督,同时避免忘记旧类。本文提出一种新的数据高效的WILSS框架FMWISS。本文提出基于预训练的协同分割,以提取互补的基础模型的知识,以生成密集的伪标签。用师生架构进一步优化了有噪声的伪掩码,其中插件式教师用提出的密集对比损失进行了优化。提出了基于内存的复制粘贴增强,以改善旧类的灾难性遗忘问题。在Pascal VOC和COCO数据集上的实验结果表明,FMWISS在15-5 VOC的数据集上取得了70.7%和73.3%的性能提升,分别比当前最好的方法提升了3.4%和6.1%。 https://antoyang.github.io/vid2seq.html
成为VIP会员查看完整内容

相关内容

CVPR 2023大会将于 6 月 18 日至 22 日在温哥华会议中心举行。CVPR是IEEE Conference on Computer Vision and Pattern Recognition的缩写,即IEEE国际计算机视觉与模式识别会议。该会议是由IEEE举办的计算机视觉和模式识别领域的顶级会议,会议的主要内容是计算机视觉与模式识别技术。
CVPR 2023 共收到 9155 份提交,比去年增加了 12%,创下新纪录,今年接收了 2360 篇论文,接收率为 25.78%。作为对比,去年有 8100 多篇有效投稿,大会接收了 2067 篇,接收率为 25%。
Arxiv
2+阅读 · 2023年4月20日
Arxiv
0+阅读 · 2023年4月20日
Arxiv
0+阅读 · 2023年4月20日
Arxiv
0+阅读 · 2023年4月19日


相关VIP内容
相关资讯