
BERT的上下文嵌入非常昂贵,并且可能无法在所有情况下带来价值。让我们找出是什么情况!
使用诸如BERT或其任何后代之类的最新模型,既不是资源有限的,也不是预算有限的研究人员或从业人员。只有预训练的基于BERT的模型(用今天的标准几乎可以认为是很小的模型)在16个TPU芯片上花费了超过4天的时间,这需要花费数千美元。这甚至都没有考虑对模型进行进一步的微调或最终使用,这两者都只会增加总成本。
与其试图找出创建较小的Transformer模型的方法(我在之前的 文章中已经探讨过),不如退后一步去问:基于Transformer的模型的上下文嵌入何时真正值得使用?在什么情况下,可以使用较低的计算成本,非上下文嵌入(例如GloVe)甚至随机嵌入来达到类似的性能?数据集的特征是否可以指示何时是这种情况?这些是Arora等人提出的一些问题。上下文嵌入中的答案:什么时候值得?本文将概述他们的研究并重点介绍他们的主要发现。
研究
研究分为两个部分,首先检查训练数据量的影响,然后检查这些数据集的语言特性。
训练数据集数量作者发现,与BERT相比,训练数据量在确定GloVe和随机嵌入的相对性能方面起着关键作用。使用更多的训练数据,非上下文嵌入可以快速改进,并且在使用所有可用数据时,通常能够在5% 10%的BERT范围内执行。。
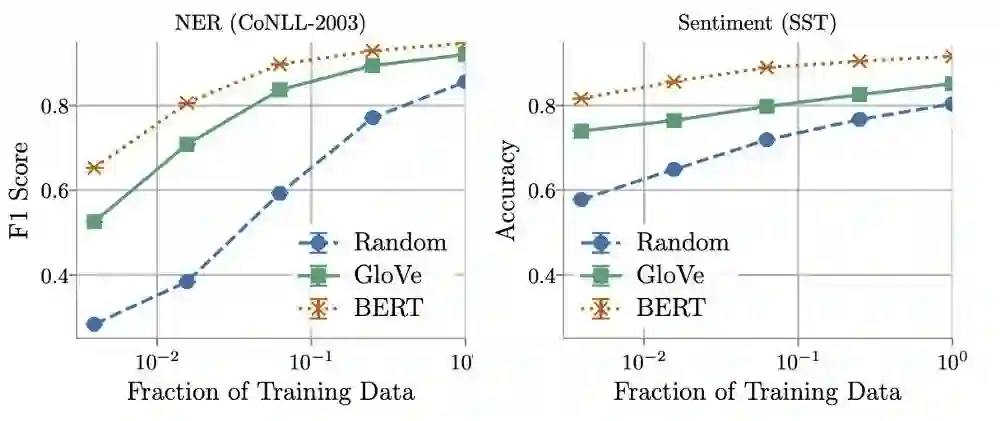
另一方面,作者发现在某些情况下可以用少 16倍的数据训练上下文嵌入,同时仍然与非上下文嵌入实现的最佳性能相匹配。这就提出了在推理成本(计算和存储)与标记数据成本之间进行权衡的方法,或者如Arora等人所述。把它: 机器学习从业者可能会发现,对于某些现实世界中的任务,效率的大幅度提高(使用非上下文嵌入时)是值得标注更多数据的成本。— Arora等
数据集的语言特征
对训练数据量的研究清楚表明,对于某些任务,上下文嵌入的性能要好于非上下文嵌入的性能,而在其他情况下,这些差异要小得多。这些结果促使作者想出是否有可能发现和量化语言属性,从而表明何时是这种情况。 为此,他们定义了三个度量标准,用于量化每个数据集和其中的项目的特征。根据设计,这些度量没有给出单个定义,而是用于编码哪些特征影响模型性能的直觉。这使我们可以针对我们研究的任务对它们进行解释,然后对其进行严格定义。因此,在下面的表格I中,将作者提出的度量与命名实体识别数据集的示例定义共享:
- 文本结构的复杂性。每个实体所跨越的令牌数量表明了复杂性。“乔治·华盛顿”跨越两个标记。
- 单词用法的歧义。每个令牌在训练数据集中分配的不同标签的数量。可以为“华盛顿”分配人员,位置和组织,这需要考虑其上下文。
- 看不见的单词的普遍性。令牌出现次数的倒数。如果前一个句子是我们的数据集,则单词“ of”将被赋值为1/2 = 0.5。 这些指标用于对数据集中的每个项目进行评分,以便我们将其分为“困难”和“简单”分区。这使作者能够比较同一数据集中这两个分区上的嵌入性能。



如果这些度量标准不提供信息,则两个分区的性能差异将相等。幸运的是,这不是作者发现的。相反,他们观察到,在42个案例中,有30个案例在困难分区上的上下文嵌入和非上下文嵌入之间的差异要比简单分区更高。 这意味着当BERT等模型的上下文嵌入胜过非上下文嵌入时,这些指标可用作代理!但是,反过来可能更有用- 指出GloVe的非上下文嵌入何时足以达到最新的性能。
结论
在Arora的论文《Contextual Embeddings: When Are They Worth It?》中,突出显示数据集的关键特征,这些特征指示何时应该使用上下文嵌入。首先,训练数据集的数量确定了非上下文嵌入的潜在用处和更好的地方。其次,数据集的特征也起着重要作用。作者能够定义三个度量标准,即文本结构的复杂性,单词用法的歧义以及看不见的单词的普遍性,这有助于我们理解使用上下文嵌入可能带来的潜在好处。

