深度强化学习探索算法最新综述,近200篇文献揭示挑战和未来方向
转载机器之心
作者:杨天培、汤宏垚、白辰甲、刘金毅等
强化学习是在与环境交互过程中不断学习的,⽽交互中获得的数据质量很⼤程度上决定了智能体能够学习到的策略的⽔平。因此,如何引导智能体探索成为强化学习领域研究的核⼼问题之⼀。本⽂介绍天津⼤学深度强化学习实验室近期推出的深度强化学习领域第⼀篇系统性的综述⽂章,该综述⾸次全⾯梳理了DRL和MARL的探索⽅法,深⼊分析了各类探索算法的挑战,讨论了各类挑战的解决思路,并揭⽰了未来研究⽅向。

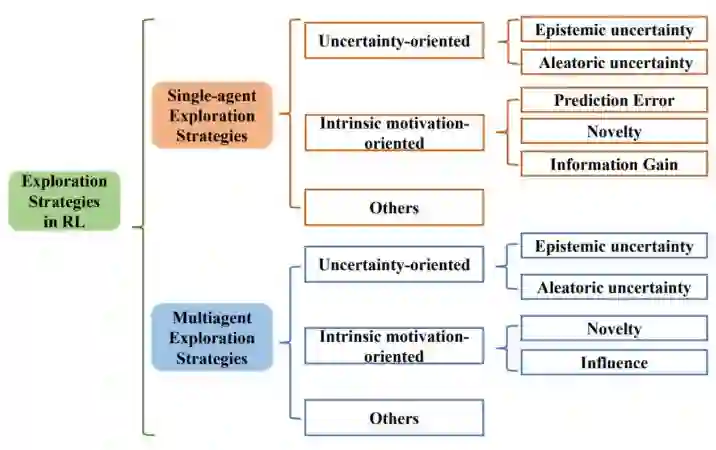
三类探索算法。该综述⾸次提出基于⽅法性质的分类⽅法,根据⽅法性质把探索算法主要分为基于不确定性的探索、基于内在激励的探索和其他三⼤类,并从单智能体深度强化学习和多智能体深度强化学习两⽅⾯系统性地梳理了探索策略。
四⼤挑战。除了对探索算法的总结,综述的另⼀⼤特点是对探索挑战的分析。综述中⾸先分析了探索过程中主要的挑战,同时,针对各类⽅法,综述中也详细分析了其解决各类挑战的能⼒。
三个典型benchmark。该综述在三个典型的探索benchmark中提供了具有代表性的DRL探索⽅法的全⾯统⼀的性能⽐较。
五点开放问题。该综述分析了现在尚存的亟需解决和进⼀步提升的挑战,揭⽰了强化学习探索领域的未来研究⽅向。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DRLE” 就可以获取《深度强化学习探索算法最新综述,近200篇文献揭示挑战和未来方向》专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月17日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月17日