
当前,强化学习(包括深度强化学习DRL和多智能体强化学习MARL)在游戏、机器⼈等领域有⾮常出⾊的表现,但尽管如此,在达到相同⽔平的情况下,强化学习所需的样本量(交互次数)还是远远超过⼈类的。这种对⼤量交互样本的需求,严重阻碍了强化学习在现实场景下的应⽤。为了提升对样本的利⽤效率,智能体需要⾼效率地探索未知的环境,然后收集⼀些有利于智能体达到最优策略的交互数据,以便促进智能体的学习。近年来,研究⼈员从不同的⻆度研究RL中的探索策略,取得了许多进展,但尚⽆⼀个全⾯的,对RL中的探索策略进⾏深度分析的综述。
本⽂介绍深度强化学习领域第⼀篇系统性的综述⽂章Exploration in Deep Reinforcement Learning: A Comprehensive Survey。该综述⼀共调研了将近200篇⽂献,涵盖了深度强化学习和多智能体深度强化学习两⼤领域近100种探索算法。总的来说,该综述的贡献主要可以总结为以下四⽅⾯:
-
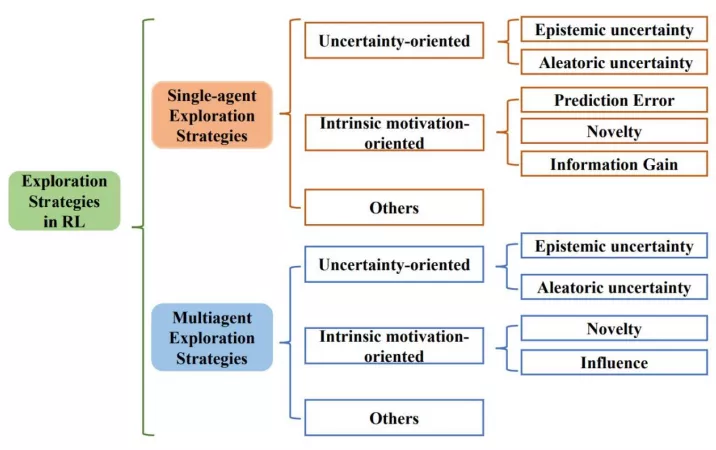
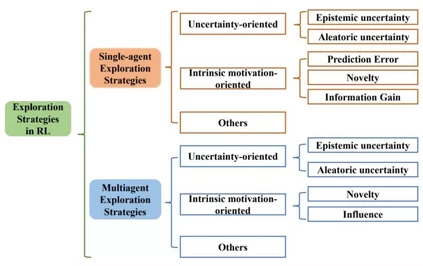
三类探索算法。该综述⾸次提出基于⽅法性质的分类⽅法,根据⽅法性质把探索算法主要分为基于不确定性的探索、基于内在激励的探索和其他三⼤类,并从单智能体深度强化学习和多智能体深度强化学习两⽅⾯系统性地梳理了探索策略。
-
四⼤挑战。除了对探索算法的总结,综述的另⼀⼤特点是对探索挑战的分析。综述中⾸先分析了探索过程中主要的挑战,同时,针对各类⽅法,综述中也详细分析了其解决各类挑战的能⼒。
-
三个典型benchmark。该综述在三个典型的探索benchmark中提供了具有代表性的DRL探索⽅法的全⾯统⼀的性能⽐较。
-
五点开放问题。该综述分析了现在尚存的亟需解决和进⼀步提升的挑战,揭⽰了强化学习探索领域的未来研究⽅向。
成为VIP会员查看完整内容
相关内容


相关VIP内容
相关资讯
相关论文