牛津Google等JAIR最新《自动强化学习AutoRL》综述论文,值得关注!

强化学习(RL)和深度学习的结合带来了一系列令人印象深刻的成就,许多人相信(深度)RL提供了一条通向一般有能力智能体的道路。然而,RL智能体的成功通常对训练过程中的设计选择高度敏感,这可能需要繁琐且容易出错的手动调优。这使得使用RL解决新问题具有挑战性,也限制了它的全部潜力。在机器学习的许多其他领域,AutoML已经表明,自动化这样的设计选择是可能的,当AutoML应用于RL时,也产生了有希望的初步结果。然而,自动强化学习(AutoRL)不仅涉及AutoML的标准应用,还包括RL特有的额外挑战,这自然产生了一套不同的方法。因此,AutoRL已经成为RL研究的一个重要领域,为从RNA设计到围棋等游戏的各种应用提供了希望。考虑到RL中考虑的方法和环境的多样性,许多研究在不同的子领域进行,从元学习到进化。在这项综述中,我们寻求统一AutoML领域,提供一个共同的分类,详细讨论每个领域,并提出开放问题的兴趣。
https://www.zhuanzhi.ai/paper/de9aef36d3d02e3e3ee193ad87077d58
引言
在过去的十年中,我们看到了一系列利用强化学习(RL, (Sutton & Barto, 2018))在各种领域(如游戏)训练智能体的突破(Mnih et al., 2015; Berner et al., 2019; Silver et al., 2016; Vinyals et al., 2019)和机器人(OpenAI et al., 2018),在现实世界的应用中取得了成功(Bellemare et al., 2020; Nguyen et al., 2021; Degrave et al., 2022)。因此,研究界的兴趣激增。然而,虽然RL取得了一些令人印象深刻的成就,但许多标题结果依赖于大量调优的实现,这些实现未能推广到预期领域之外。事实上,RL算法已经被证明对深度神经网络的超参数和架构非常敏感(Henderson et al., 2018; Andrychowicz et al., 2021; Engstrom et al., 2020),而有越来越多的额外设计选择,如代理的目标(Hessel等人,2019年)和更新规则(Oh等人,2020年)。人工同时优化如此多的设计选择是一件繁琐、昂贵、甚至容易出错的事情。自动化机器学习(AutoML, Hutter et al. (2019))在机器学习(ML)的其他领域也取得了显著的成功。然而,这些方法在RL中还没有产生显著的影响,部分原因是RL应用具有典型的挑战性,由于环境和算法的多样性,以及RL问题的非平稳性。
这项综述的目的是展示自动强化学习(AutoRL)领域,作为一套方法,在不同程度上自动化RL流程。AutoRL服务于解决各种各样的挑战: 一方面,RL算法的脆弱性阻碍了在新领域的应用,特别是在从业者缺乏大量资源来搜索最优配置的领域。在许多设置中,为一个完全看不见的问题手动查找甚至是中等强度的超参数集都可能是非常昂贵的。AutoRL已经被证明可以在这种情况下帮助解决重要问题,例如设计RNA (Runge et al.,2019年)。另一方面,对于那些受益于更多计算的人来说,增加算法的灵活性显然可以提高性能(Xu et al.,2020; Zahavy et al.,2020; Jaderberg et al.,2017)。这已经在著名的AlphaGo智能体中得到了展示,它通过使用贝叶斯优化(BO)得到了显著的改进(Chen et al., 2018)。早在20世纪80年代(Barto & Sutton, 1981),可被认为是AutoRL算法的方法就被证明是有效的。然而,近年来AutoML的流行导致了更先进技术的初步应用(Runge et al.,2019; Chiang et al., 2019)。与此同时,进化群体几十年来一直在进化神经网络及其权重(Stanley & Miikkulainen, 2002),其中的方法鼓舞了那些被证明对现代RL有效的方法(Jaderberg et al.,2017)。此外,最近元学习的流行导致了一系列寻求自动化RL过程的工作(Houthooft et al., 2018; Xu et al., 2018; Kirsch et al., 2020)。
在本文中,我们试图提供这些方法的分类。在这样做的过程中,我们希望通过思想的交叉碰撞,开辟出一系列未来的工作,同时也向RL研究人员介绍一套技术,以提高他们的算法的性能。我们相信AutoRL在帮助强化学习的潜在影响方面发挥了重要作用,无论是在开放式研究还是实际的现实应用中,这项综述可以为那些希望利用其潜力的人形成一个起点。
此外,我们希望将对AutoML感兴趣的研究人员更广泛地吸引到AutoRL社区,因为AutoRL带来了独特的挑战。特别是,RL存在非平稳性问题,因为agent所训练的数据是当前策略函数。此外,AutoRL还包含针对RL问题的环境和算法设计。我们相信这些挑战将需要重要的未来工作,因此概述了整个论文的开放问题。
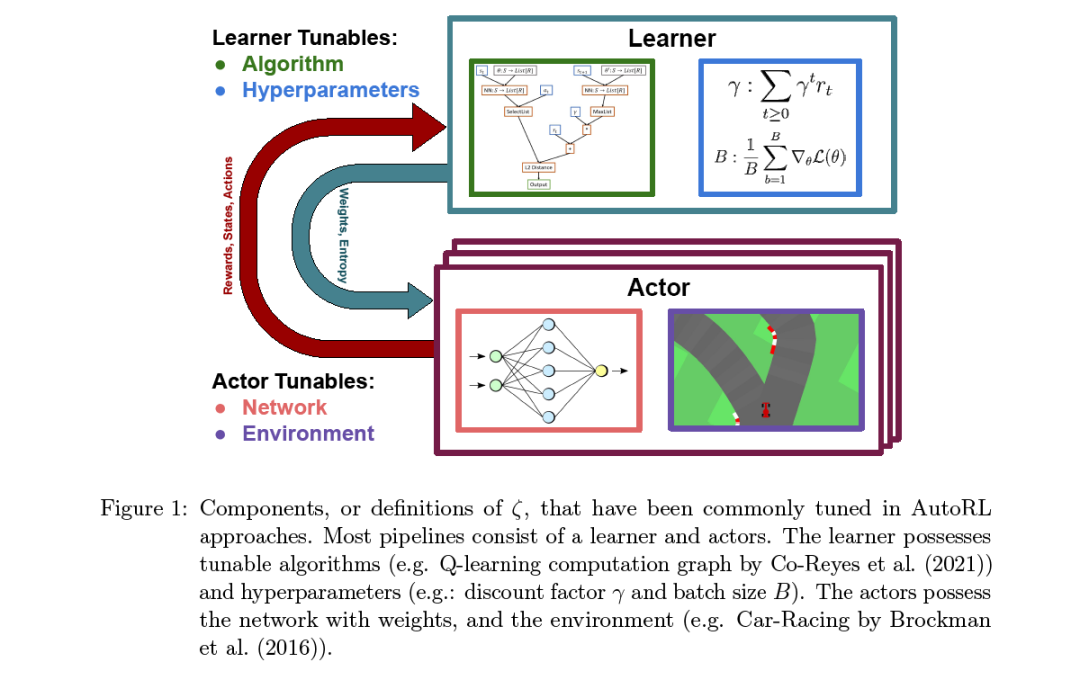
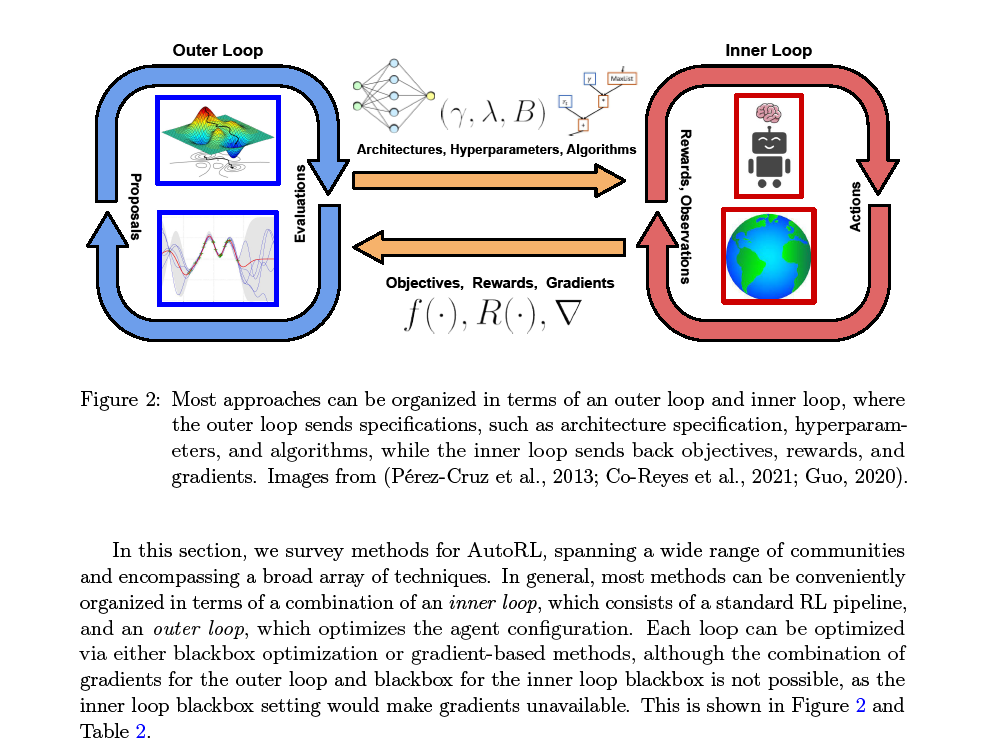
我们的论文结构如下。在第2节中,我们描述了形式化AutoRL问题所需的背景和符号,然后形式化这个问题,并讨论了评估它的各种方法。然后,我们简要地总结了各种类型的RL算法,然后描述了AutoRL问题特有的非平稳性。在第3节中,我们讨论了需要自动化的AutoRL问题的各种组件,包括环境、算法、它们的超参数和架构。在第4节中,我们提供了一个分类,并在该分类之后的子节中调研了当前的AutoRL方法。在第5节中,我们将讨论各种公开可用的基准测试及其应用领域。最后,在第6节中,我们讨论了AutoRL的未来方向。