

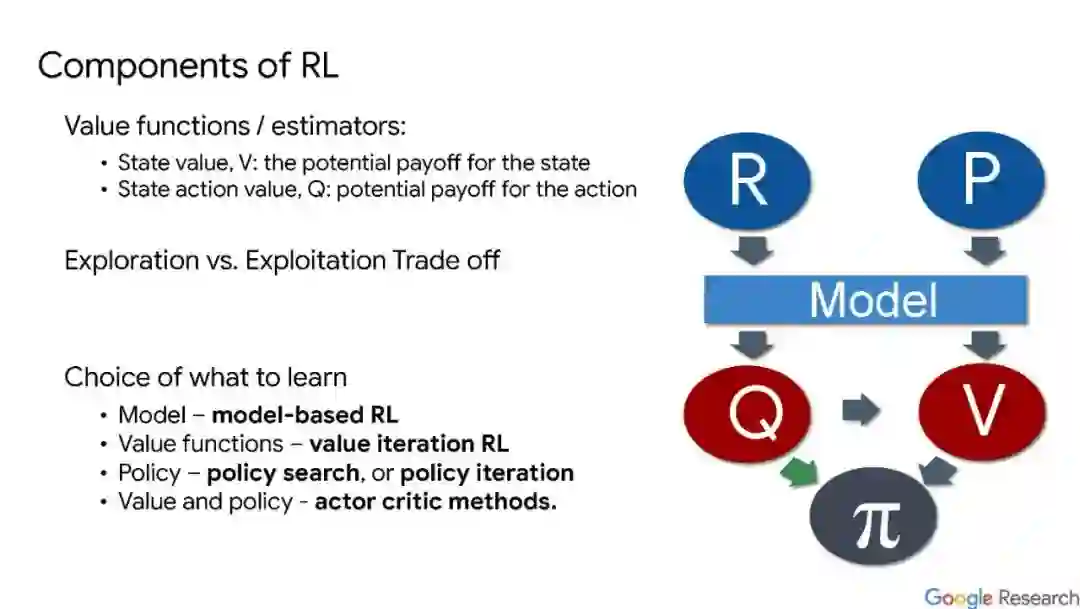
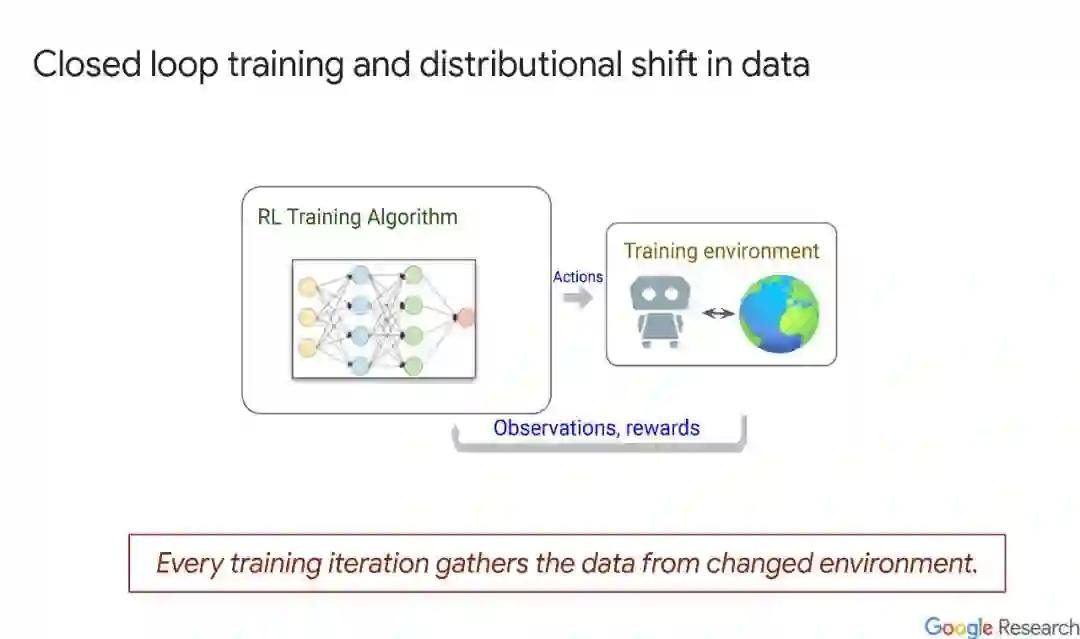
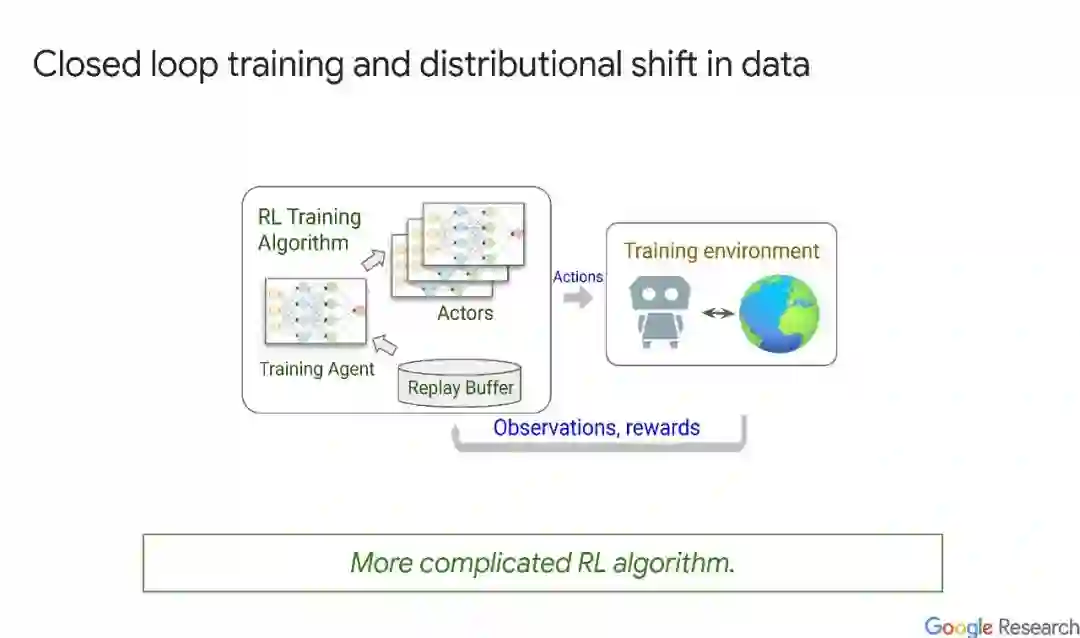
训练强化学习(RL)系统在实际任务中表现良好是困难的,原因有很多。一个重要的原因是,工程师和应用研究人员面临着大量的设计选择,旨在将现实世界的问题表示为部分可观察马尔可夫决策(POMDP)抽象,这不足以捕捉问题的所有方面。因此,工程师通过试验和错误,优化RL系统设计,直到达到令人满意的性能。这是一个累人、耗时和低效的过程。learn to learn和Auto RL将这个过程的部分自动化,允许用户专注于更高层次的设计问题。在本教程中,我们将回顾当前建立的技术,如环境、算法、表示和奖励学习,并讨论可用的工具、它们如何以及为什么工作,以及它们何时会失败。最后,由于这是一个新兴的领域,我们将总结该领域的未来前景和面临的开放问题。





成为VIP会员查看完整内容
相关内容
相关主题


相关VIP内容
相关资讯