【牛津大学&DeepMind】自监督学习教程,141页ppt
借助现代的高容量模型,大数据已经推动了机器学习的许多领域的革命,但标准方法——从标签中进行监督学习,或从奖励功能中进行强化学习——已经成为瓶颈。即使数据非常丰富,获得明确指定模型必须做什么的标签或奖励也常常是棘手的。收集简单的类别标签进行分类对于数百万计的示例来说是不可能的,结构化输出(场景解释、交互、演示)要糟糕得多,尤其是当数据分布是非平稳的时候。
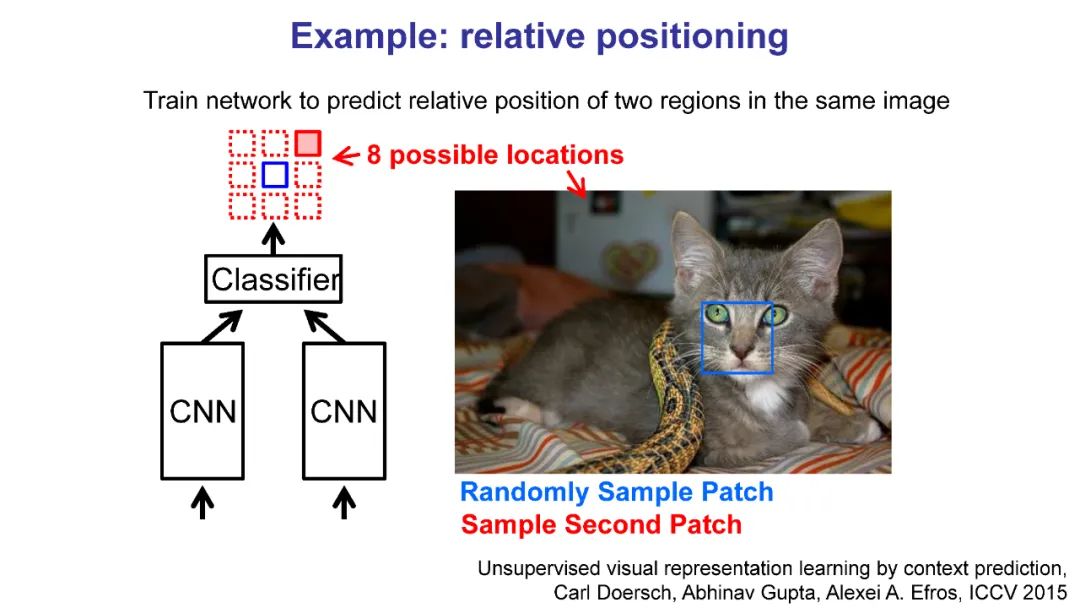
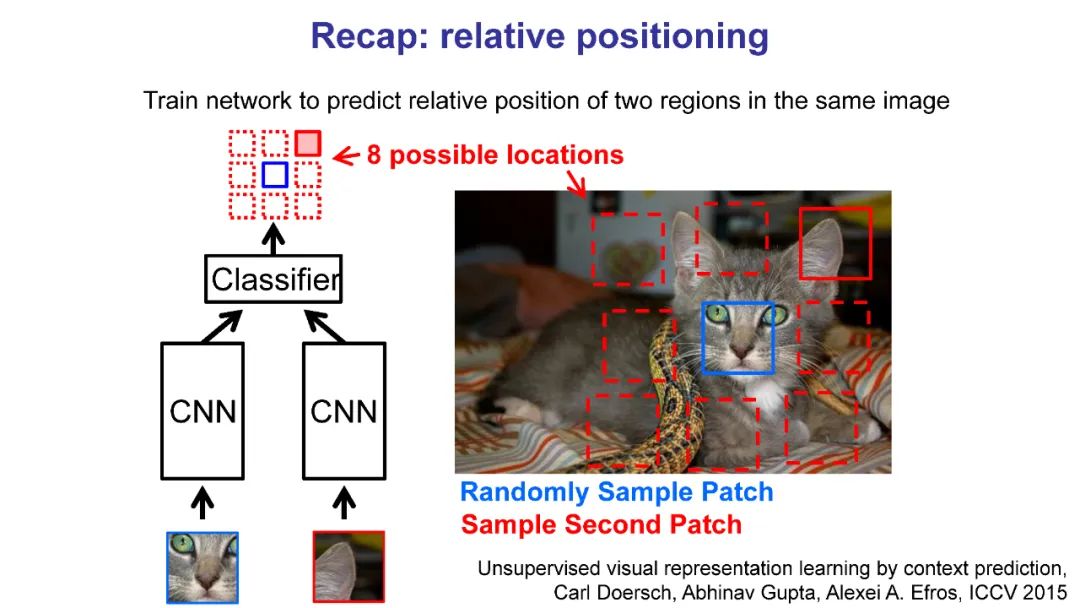
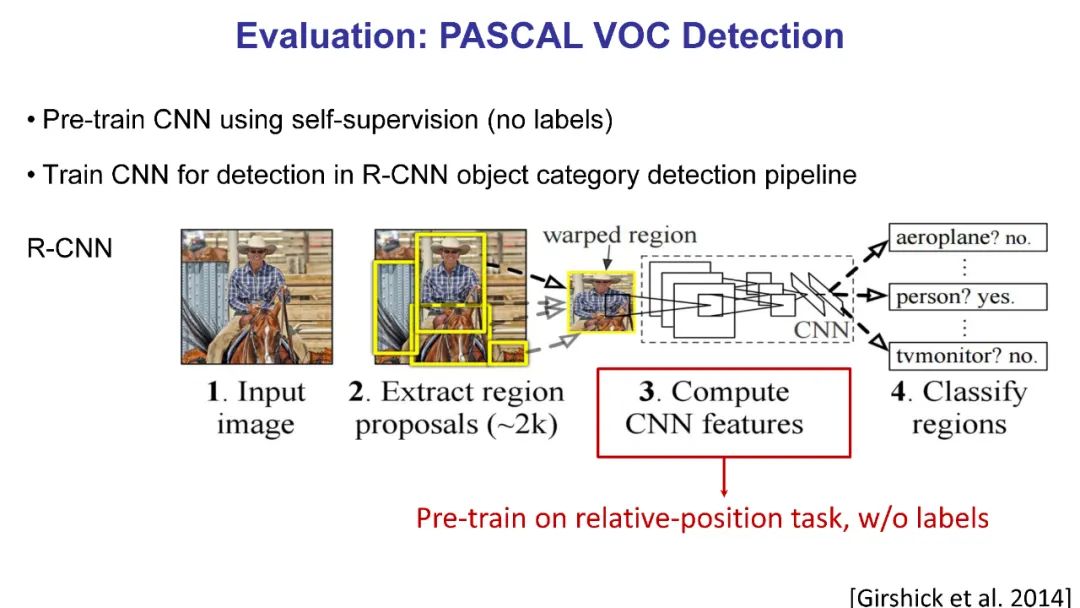
自监督学习是一个很有前途的替代方法,其中开发的代理任务允许模型和代理在没有明确监督的情况下学习,这有助于对感兴趣的任务的下游性能。自监督学习的主要好处之一是提高数据效率:用较少的标记数据或较少的环境步骤(在强化学习/机器人技术中)实现可比较或更好的性能。
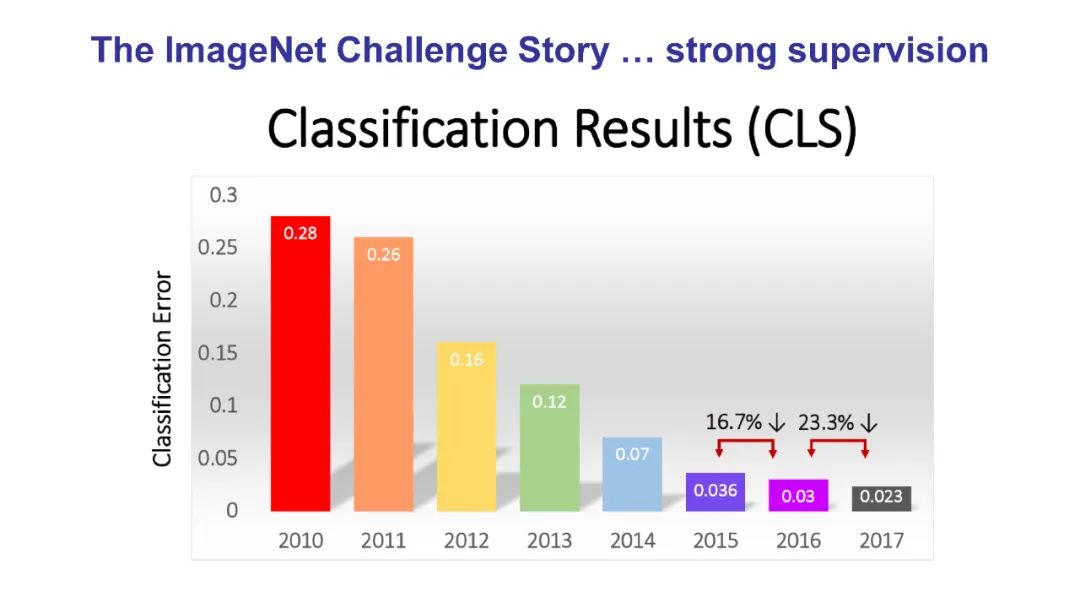
自监督学习(self-supervised learning, SSL)领域正在迅速发展,这些方法的性能逐渐接近完全监督方法。
























专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SL141” 可以获取《自监督学习141页ppt》专知下载链接索引



登录查看更多
相关内容

Arxiv
4+阅读 · 2018年3月26日




相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年3月26日