胶囊 (向量神经) 网络
斯蒂文认为机器学习有时候像婴儿学习,特别是在物体识别上。比如婴儿首先学会识别边界和颜色,然后将这些信息用于识别形状和图形等更复杂的实体。比如在人脸识别上,他们学会从眼睛和嘴巴开始识别最终到整个面孔。当他们看一个人的形象时,他们大脑认出了两只眼睛,一只鼻子和一只嘴巴,当认出所有这些存在于脸上的实体,并且觉得“这看起来像一个人”。
斯蒂文首先给他的女儿悠悠看了以下图片,看她是否能自己学会认识图中的人(金·卡戴珊)。

斯蒂文接下来用几张图来考她:

悠悠
图中有两只眼睛一个鼻子一张嘴巴,图中的物体是个人。

斯蒂文

正确!

悠悠
图中有两只眼睛一个鼻子一张嘴巴,图中的物体是个人。
斯蒂文
错误!嘴巴长到眼睛上还是个人吗?

悠悠
图中有一大块都是黑色的,图中的物体好像是头发。
斯蒂文
错误!这只是把第一张图颠倒一下,怎么就变成头发了?
斯蒂文很失望,觉得她第二、三张都应该答对,但是他对悠悠要求太高了,要知道现在深度学习里流行的卷积神经网络 (convolutional neural network, CNN) 给出的答案也和悠悠一样,如下:
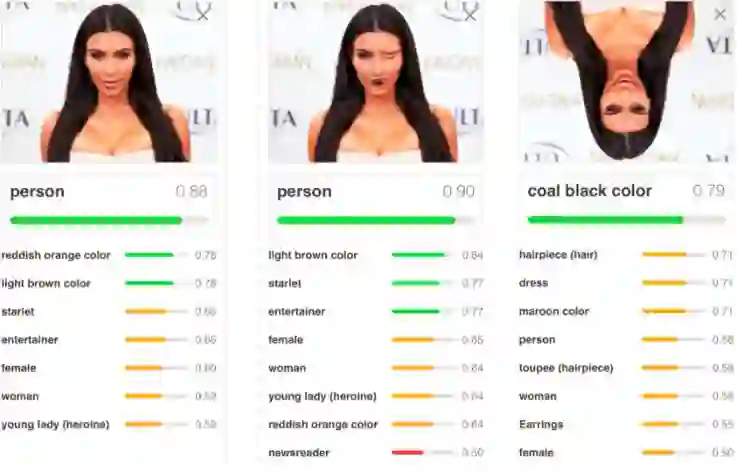
第一张 CNN 给出的答案是人,概率为 0.88,正确;第二张 CNN 给出的答案也是人,概率为 0.90 ,开玩笑在?第三张 CNN 给出的答案是黑发,概率为 0.79 ,呵呵,和悠悠一样天真。
CNN 弄错的两张图也是因为它的两个缺陷:
CNN 对物体之间的空间关系 (spatial relationship) 的识别能力不强,比如卡戴珊的嘴巴和眼睛换位置了还被识别成人?
CNN 对物体旋转之后的识别能力不强 (微微旋转还可以),比如卡戴珊倒过来就被识别成头发了?
Convolutional neural networks are doomed. -- Hinton
大神 Hinton 如此说道“卷积神经网络要完蛋了”,因此他最近也提出了一个 Capsule 的东西,直译成胶囊。但是这个翻译丢失了很多重要的东西,个人认为叫做向量神经元 (vector neuron) 甚至张量神经元 (tensor neuron) 更贴切。正式介绍 Capsule 的这篇文章在 2017 年 11 月 7 日才出来,论文名字叫《Dynamic Routing Between Capsules》,有兴趣的同学跟我走一遭吧。
第一章 - 前戏王
1.1 物体姿态
1.2 不变性和同变性
1.3 全连接层
1.4 卷积神经网络
第二章 - 理论皇
2.1 胶囊定义
2.2 神经元类比
2.3 工作原理
2.4 动态路由
2.5 网络结构
第三章 - 实践狼
3.1 帆船房子
3.2 代码解析
总结和下帖预告

1.1
物体姿态
为了正确的分类和识别物体,保持物体部分之间的分层姿态 (hierarchical pose) 关系是很重要的。姿态主要包括平移 (translation)、旋转 (rotation) 和放缩 (scale) 三种形式。
在拍摄人物时,我们调动照相机的角度从 3D 的人生成 2D 的照片。照出来的人物照角度多种多样,但人是个整体 (脸和身体对于人的相对位置不会变)。因此我们不想定义相对于相机的所有对象 (脸和身体),而将它们定义一个相对稳定的坐标系 (coordinate frame) 中,然后仅仅通过转动相机来照出不同角度的照片。
在创建这些图形时,我们首先会定义脸和身体相对于人的位置,更进一层,我们会定义眼睛和嘴巴对于相对于脸的位置,但不是相对于人的位置。因为之前已经有了脸相对于人的位置,现在又有了眼睛相对于脸的位置,那么也有了眼睛相对于人的位置。本质上,你将有层次的创建一个完整的人,而所需要的数学工具就是姿态矩阵 (pose matrix),这个矩阵定义所有对象相对于照相机的视点 (viewpoint),并且还表示了部件与整体之间的关系。
In order to correctly do classification and object recognition, it is important to preserve hierarchical pose relationships between object parts. -- Hinton
Hinton 认为,为了正确地进行分类和对象识别,重要的是保持对象部分之间的分层姿态关系。后面讲到的 Capsule 就符合这个重要直觉,它结合了对象之间的相对关系,并以姿态矩阵来表示。
完整内容请点击 “阅读原文”
转自:王的机器



