CapsNet入门系列之二:胶囊如何工作
论智

作者 | Max Pechyonkin
编译 | weakish
编者按:继介绍胶囊网络背后的直觉之后,深度学习开发者,Medium知名博主Max Pechyonkin撰写了系列文章的第二篇,讨论胶囊是什么,胶囊是如何工作的。
介绍
在胶囊网络系列文章的第一篇,我谈到了这一全新架构背后的基本直觉和动机。在本文中,我将讨论胶囊是什么,胶囊是如何工作的,以及相关的一些直觉。我会在下一篇讨论囊间动态路由算法。
胶囊是什么
为了回答胶囊是什么的问题,我觉得应该参考引入胶囊的第一篇论文——Hinton等人的《Transforming Autoencoders》。下面摘抄的一段,对理解胶囊这个概念非常重要:
人工神经网络不应当追求“神经元”活动中的视角不变性(使用单一的标量输出来总结一个局部池中的重复特征检测器的活动),而应当使用局部的“胶囊”,这些胶囊对其输入执行一些相当复杂的内部计算,然后将这些计算的结果封装成一个包含信息丰富的输出的小向量。每个胶囊学习辨识一个有限的观察条件和变形范围内隐式定义的视觉实体,并输出实体在有限范围内存在的概率及一组“实例参数”,实例参数可能包括相对这个视觉实体的隐式定义的典型版本的精确的位姿、照明条件和变形信息。当胶囊工作正常时,视觉实体存在的概率具有局部不变性——当实体在胶囊覆盖的有限范围内的外观流形上移动时,概率不会改变。实例参数却是“等变的”——随着观察条件的变化,实体在外观流形上移动时,实例参数也会相应地变化,因为实例参数表示实体在外观流形上的内在坐标。
上面一段话非常凝练,我花了一番工夫才逐句逐句地弄清楚它在说什么。以下是我对上面一段话的理解:
人造神经元输出单个标量。此外,CNN(卷积神经网络)使用了卷积层,对于每个卷积核,在整个输入图像上复制同一内核的权重,然后输出一个2维矩阵,在这个矩阵中,每个数字是该卷积核对输入图像的一部分的卷积输出。所以我们可以把这个二维矩阵看作是重复特征检测器的输出。然后所有卷积核的二维矩阵堆叠在一起,以生成卷积层的输出。

CapsNet不仅可以辨识数字,还能基于其内部表示生成数字
接着,我们试图在神经元的活动中实现视角不变性。我们通过最大池化方法来达成这一点。最大池化持续地搜寻上述二维矩阵的区域,选取每个区域中最大的数字。结果我们得到了我们想要的——活动的不变性。不变性意味着,如果我们略微调整输入,输出仍然是一样的。然后活动就是神经元的输出信号。换句话说,在输入图像上,当我们稍微变换一下我们想要检测的对象时,由于最大池化,网络活动(神经元的输出)将保持不变,网络仍然能检测到对象。
上述机制并不怎么好,因为最大池丢失了有价值的信息,也没有编码特征之间的相对空间关系。我们应该转而使用胶囊,因为,所有胶囊检测中的特征的状态的重要信息,都将以向量的形式(神经元输出的则是标量)被胶囊封装。
上面这句话很重要,所以我在这里把它重复一遍:所有胶囊检测中的特征的状态的重要信息,都将以向量的形式被胶囊封装。
胶囊将特征检测的概率作为其输出向量的长度进行编码。检测出的特征的状态被编码为该向量指向的方向(“实例参数”)。所以,当检测出的特征在图像中移动或其状态不知怎的发生变化时,概率仍然保持不变(向量长度没有改变),但它的方向改变了。
想象一个胶囊,它检测图像中的面部,并输出长度为0.99的三维向量。接着我们开始在图像上移动面部。向量将在空间上旋转,表示检测出的面部的状态改变了,但其长度将保持固定,因为胶囊仍然确信它检测出了面部。这就是Hinton所说的活动等变性:神经活动将随着物体在图像中的“外观流形上的移动”而改变。与此同时,检测概率保持恒定,这才是我们应该追求的那种不变性,而不是CNN提供的基于最大池化的不变性。
胶囊是如何工作的
让我们比较下胶囊与人造神经元。下表总结了胶囊和神经元的不同:

胶囊和神经元的重要差别
让我们回顾一下第一篇的内容,神经元从其他神经元接收输入标量,然后乘以标量权重并相加。接着将总和传递给非线性激活函数(有很多种非线性激活函数,CNN设计时选择其中的一种),非线性激活函数接受这个输入标量,并根据自身定义输出一个标量。该标量将成为神经元的输出,并作为其他神经元的输入。下面的列表和示意图概览了整个过程。本质上,人造神经元可以用3个步骤来表示:
输入标量的标量加权
加权输入标量之和
标量到标量的非线性变换

左:胶囊;右:人工神经元
另一方面,胶囊具有上面3个步骤的向量版,并新增了输入的仿射变换这一步骤:
输入向量的矩阵乘法
输入向量的标量加权
加权输入向量之和
向量到向量的非线性变换
下面,让我们更细致地看下胶囊内部发生的4个运算步骤。
1.输入向量的矩阵乘法
胶囊接收的输入向量(上图中的u1、u2和u3)来自下层的3个胶囊。这些向量的长度编码了下层胶囊检测出的相应对象的概率,向量的方向编码了检测出的对象的一些内部状态。让我们假定下层的胶囊分别检测眼睛、嘴巴和鼻子,而输出胶囊检测面部。
接着将这些向量乘以相应的权重矩阵W,W编码了低层特征(眼睛、嘴巴和鼻子)和高层特征(面部)之间的空间关系和其他重要关系。例如,矩阵W2j可能编码鼻子和面部的关系:面部以鼻子为中心,其大小是鼻子大小的10倍,并且面部在空间上的朝向和鼻子的朝向相对应,因为它们都位于同一平面上。矩阵W1j和W3j背后的直觉与此类似。乘以这些矩阵后,我们得到的是高层特征的预测位置。换句话说,û1表示根据检测出的眼睛的位置,面部应该在什么位置,û2表示根据检测出的嘴巴的位置,面部应该在什么位置,û3表示根据检测出的鼻子的位置,面部应该在什么位置。
到目前为止,直觉上你应该意识到:如果这三个低层特征的预测指向的位置和状态与面部的位置和状态相同,那么面部必然存在。

鼻子、嘴巴和眼睛胶囊预测的面部位置很接近,面部必然存在
2.输入向量的标量加权
初看起来这个步骤和人造神经元的对应步骤很接近,然而,神经元的权重是通过反向传播学习的,而胶囊则使用“动态路由”,这是一种确定每个胶囊的输出的新方法。这个算法将是本系列下一篇的内容,这里只谈一些直觉。

低层胶囊将其输出发送给对此表示“同意”的高层胶囊。这是动态路由算法的精髓
上图中,一个低层胶囊需要“决定”将它的输出发送给哪个高层胶囊。它将通过调整权重C做出决定,胶囊在发送输出前,先将输出乘以这个权重。胶囊将决定是把输出发给左边的胶囊J,还是发给右边的胶囊K。
目前为止,高层胶囊已经接收到来自其他低层胶囊的许多向量。所有这些输入以红点和蓝点表示。这些点聚集的地方,意味着低层胶囊的预测互相接近。比如,胶囊J和K中都有一组聚集的红点,因为那些胶囊的预测很接近。
所以,低层胶囊该把它的输出发给胶囊J还是胶囊K呢?这个问题的答案正是动态路由算法的精髓。低层胶囊的输出乘以相应的矩阵W后,远离胶囊J中“正确”预测的红色聚集,另一方面,在胶囊K中,它将落在非常接近于“真”预测的红色群组中。低层胶囊具备测量哪个高层胶囊更能接受其输出的机制,并据此自动调整权重,使对应胶囊K的权重C变高,对应胶囊J的权重C变低。
3.加权输入向量之和
这一步骤表示输入的组合,和通常的人工神经网络差不多。我认为这一步没什么特别的(除了它是向量的和而不是标量的和)。所以我们可以直接进入下一步。
4.“压缩”:新颖的向量到向量非线性变换
CapsNet的另一大创新是新颖的非线性激活函数,这个函数接受一个向量,然后在不改变方向的前提下,压缩它的长度到1以下。

压缩输入向量的标量而不改变其方向
公式右边的蓝色矩形缩放输入向量至单位长度,左边的红色矩形进行一些额外的缩放。记住,输出向量的长度代表胶囊检测的给定特征的概率。
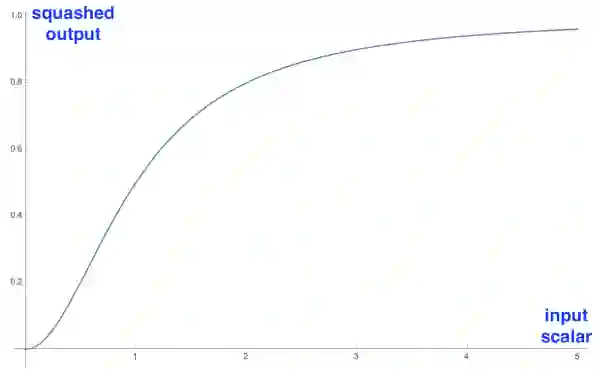
新非线性变换方法的图形(标量版本)。真实应用中的函数操作向量
上图是应用于一维向量(标量)的压缩函数。我用它来演示函数有趣的非线性形态。
只有可视化一维情况比较可行。实际应用中,这个函数会接受一个向量并输出一个向量,很难可视化。
结论
本篇讨论了什么是胶囊,它执行的是什么样的运算,以及相应的一些直觉。我们看到,胶囊的设计基于人造神经元的设计,但将其扩展到了向量形式,使其具有更强大的表示能力。它还引入了矩阵权重来编码不同层的特征之间的重要层次关系。 结果成功地实现了设计者的目标:随着输入变化的神经元活动等变性和特征检测概率的不变性。
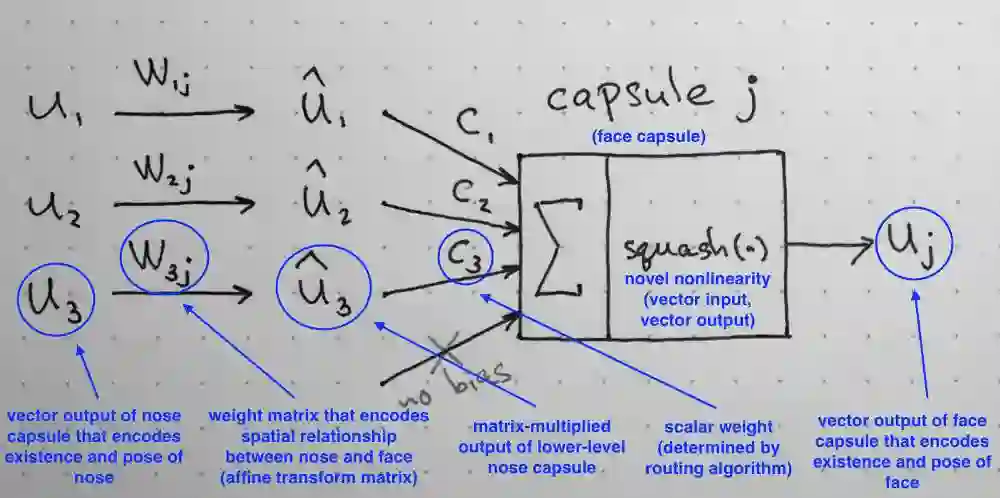
胶囊内部机制的概览。注意这里没有偏置量,因为已经包含在W矩阵中了
为了完结这个系列,我还会写两篇文章,一篇介绍囊间动态路由算法,另一篇详细介绍胶囊网络的架构,敬请期待。



