

“人工智能”(AI)最近在图像和语音识别等领域产生了深远的影响,这一进展已经转化为实际应用。然而,在药物发现领域,这样的进步仍然很少,原因之一是使用的数据本身。在这篇综述中,我们讨论了来自不同领域的数据的方面和差异,即图像、语言、化学和生物领域的数据,可用的数据量,以及它们与药物发现的相关性。未来需要我们对生物系统的理解,以及随后生成足够数量的与实际相关的数据,才能真正推进人工智能在药物发现领域的发展,发现具有新型作用模式的新型化学物质,并在临床中表现出理想的有效性和安全性。
https://www.sciencedirect.com/science/article/pii/S1359644621000428?via%3Dihub
人工智能已经改变了许多领域,可能最显著的是图像和语音识别领域,导致了自动护照控制和“虚拟助手”(也涉及隐私等相关问题)。从现在开始,聚焦于技术方面,图像识别方面的最新发展的起点可能是2010年由Schmidhuber和他的同事[1]发表的关于识别手写字符的论文。2012年NIPS发表了一篇关于AlexNet[2]的论文,成功地利用了深度神经网络对图像进行分类,从而使这一领域快速发展起来。这个进展不仅依赖特定的选择由作者(如使用连续卷积和汇聚层,使用修正线性(ReLU)单位,数据增加和dropout 层[3]],还有大量的标记数据可以从ImageNet库[4],以及图形处理单元(GPU)的使用。在语音识别方面,Hochreiter和他的同事[5]所做的诸如长期短时记忆(LSTM)的研究为最近的实际应用铺平了道路,比如在移动设备和虚拟助手上。
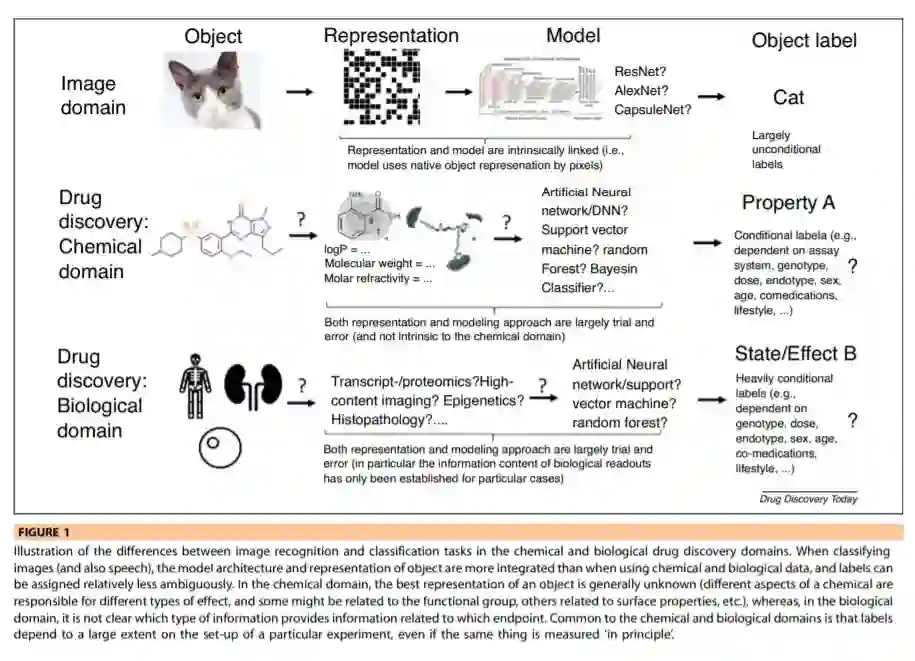
人工智能先前成功的领域,如图像分类和语音识别,在以下方面不同于药物发现领域中可用的化学和生物数据:(i)可用数据的数量; ii) 能够将其以合适的形式表示给计算机;iii)与可用数据本质一致的ML算法(例如,波形和RNNs,或图像和CNNs具有这种潜在的一致性,而化学和生物数据不存在这种一致性); iv)分配有意义标签的可能性(在药物发现领域很大程度上取决于情况,如剂量、基因型、试验设置等)。此外,近期的其他进展,如DeepMind在最近的CASP蛋白折叠竞赛中以较大优势获胜[67],也需要评估在药物发现的背景下,这究竟能让我们做些什么。对于蛋白质折叠领域来说,这确实是一个非常重要的发展,因为预测折叠后的蛋白质状态的精确度和速度现在是可能的。然而,在药物发现领域,任何药物的体内有效性和安全性的关键问题仍然和以前一样——我们可能会比以前对接更多的靶点(并进行基于结构的设计),以更快地发现配体;如何将其转化为体内情况是一个完全开放的问题,上面关于“配体”和“药物”发现的评论和以前一样适用。最近关于该主题的全面讨论参见[68]。简而言之,在图像上识别物体、预测蛋白质结构和识别安全有效的药物之间是有区别的。我们将在下面更详细地描述这些差异。
https://www.sciencedirect.com/science/article/pii/S1359644621000428?via%3Dihub



