CapsNet入门系列之一:胶囊网络背后的直觉
论智

作者 | Max Pechyonkin
编译 | weakish
编者按:Geoffrey Hinton,深度学习的开创者之一,反向传播等神经网络经典算法的发明人,上个月发表了论文,介绍了全新的胶囊网络模型,以及相应的囊间动态路由算法。深度学习开发者,Medium知名博主Max Pechyonkin最近撰文,深入浅出地介绍了胶囊网络背后的直觉。
介绍
上个月,Geoffrey Hinton和他的团队发表了两篇论文,介绍了一种全新的神经网络,这种网络基于一种Hinton称为胶囊(capsule)的结构。 此外,还发表了囊间动态路由算法,用来训练新提出的胶囊网络。

Geoffrey Hinton花了数十年的时间思考胶囊
对于深度学习社区的每一个人而言,这都是一个重磅新闻。首先,Hinton是深度学习的开创者之一,也是现在广泛使用的众多模型和算法的发明者。其次,这两篇论文引入了全新的东西。这些东西很让大家激动,因为这很可能激发一大波新研究和酷炫应用。
在这篇文章中,我将解释为什么这个新架构如此重要,还有它背后的直觉。我会另外发布一篇文章,介绍这个架构的技术细节。
不过,在谈论胶囊之前,让我们先回顾一下卷积神经网络,现今深度学习的主力。
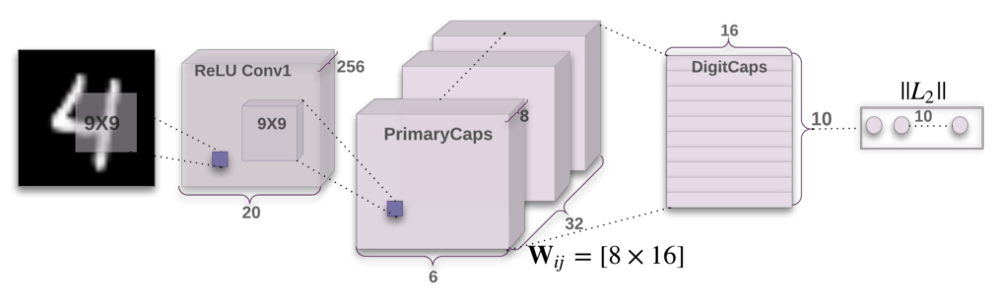
论文中的CapsNet架构
CNN的重大缺陷
CNN(卷积神经网络)的表现令人印象深刻。 它是如今深度学习如此流行的一个原因。CNN可以做到令人惊叹的事情,一些过去人们觉得计算机在很长很长的时期内做不到的事情。尽管如此,CNN有其局限性,还有一个根本性的缺陷。
让我们考虑一个非常简单的非技术性例子。想象一张脸,想一下它是由哪些部件组成的?代表脸型的椭圆、两只眼睛、一个鼻子和一个嘴巴。对于CNN来说,仅仅这些对象的存在就是一个非常强烈的暗示,意味着图像中有一张脸。而组件的朝向和空间上的相对关系对CNN来说并不是很重要。
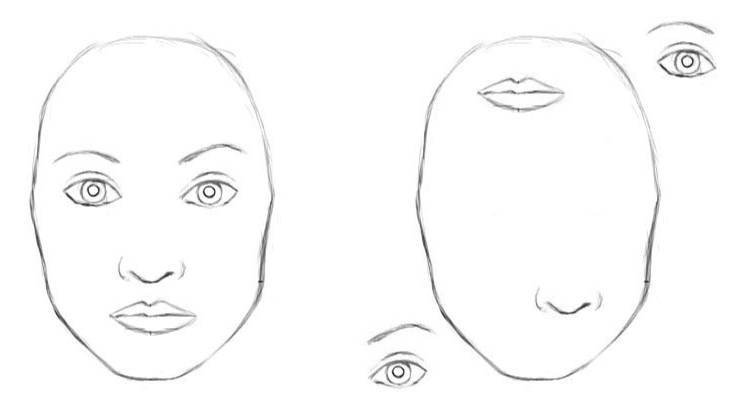
对于CNN而言,两张图片是类似的,因为它们包含相似的部件
CNN是如何工作的呢?CNN的主要部分是卷积层,用于检测图像像素中的重要特征。较深的层(更接近输入的层)将学习检测诸如边缘和颜色渐变之类的简单特征,而较高的层则将简单特征组合成复杂一些的特征。最后,网络顶部的致密层组合高层特征并输出分类预测。
需要重点理解的是,高层特征将低层特征组合为加权和,前一层的激活与下一层神经元的权重相乘并相加,接着传递到非线性激活函数。在这一配置中,组成高层特征的低层特征之间并不存在位姿(平移和旋转)关系。CNN解决这个问题的方法是使用最大池化或后续卷积层来减少通过网络的数据的空间大小,从而增加了上层网络神经元的“视野”,因此它们得以检测输入图像较大区域的高阶特征。卷积网络表现惊人,甚至在众多领域产生了超越人类的效果,其支柱正是最大池化。不过,可不要被它的表现迷惑了。虽然CNN的效果比之前的任何模型都好,最大池化依然损失了有价值的信息。
Hinton自己就表示,最大池化表现如此优异是一个巨大的错误,是一场灾难:
卷积神经网络使用的池化操作是一个巨大的错误,它表现如此优异则是一场灾难。
当然,你可以不使用最大池化,基于传统的CNN取得不错的结果,然而这仍旧没有解决一个关键问题:
卷积神经网络的内部数据表示没有考虑简单和复杂对象之间的重要空间层级。
上文提到的例子,图片中存在两只眼睛、一张嘴和一个鼻子,仅仅这些并不意味着图片中存在一张脸,我们还需要知道这些对象彼此之间的朝向关系。
将三维世界硬编码为神经网络:逆图形法
计算机图形学,基于几何数据内部的分层表示,构造可视图像。注意,这类表示的结构需要考虑对象的相对位置。这些内部表示存储在计算机内存中。几何化的对象以数组表示,对象间的相对位置关系和朝向以矩阵表示。接着,特定的软件接受这些表示作为输入,并将它们转化为屏幕上的图像。这叫做渲染。

计算机图形接受对象的内部表示并产生图像,人类大脑恰恰相反。胶囊网络的方法与大脑类似
受此想法的启发,Hinton主张,大脑做的,和渲染正好相反。他把这个叫做逆图形,从眼睛接收到的视觉信息中,大脑解析出我们周围世界的分层表示,并尝试匹配已学习到的模式和存储在大脑中的关系。辨识就是这样进行的。关键的想法是大脑中物体的表示并不依赖于视角。
那么我们现在要考虑的问题是:我们如何在神经网络中建模这些分层关系?答案源自计算机图形学。在三维图形中,三维对象之间的关系可以用位姿表示,位姿的本质是平移和旋转。
Hinton主张,为了正确地分类和辨识对象,保留对象部件间的分层位姿关系很重要。这是让你理解胶囊理论为何如此重要的关键直觉。它结合了对象之间的相对关系,在数值上表示为4维位姿矩阵。
当数据的内部表示内建这些关系时,模型非常容易理解它看到的是以前见过的东西,只不过是另一个视角而已。考虑下面的图片。你可以轻易辨识出这是自由女神像,尽管所有的图像显示的角度都不一样。这是因为你脑中的自由女神像的内部表示并不依赖视角。你大概从没有见过和这些一模一样的图片,但你仍然能立刻知道这是自由女神像。

尽管拍摄的角度不同,你的大脑可以轻易辨识这些都是同一对象。CNN却没有这样的能力
对CNN而言,这个任务非常难,因为它没有内建对三维空间的理解。而对于CapsNet而言,这个任务要容易得多,因为它显式地建模了这些关系。相比之前最先进的方法,使用CapsNet的论文能够将错误率降低45%(由约20%降低到约12%),这是一个巨大的提升。
胶囊方法的另一大益处在于,相比CNN需要的数据,它只需要学习一小部分数据,就能达到最先进的效果(Hinton在他关于CNN错误的著名演说中提到了这一点)。 从这个意义上说,胶囊理论实际上更接近人脑的行为。为了学会区分数字,人脑只需要几十个例子,最多几百个例子。而CNN则需要几万个例子才能取得很好的效果。这看起来像是在暴力破解,显然要比我们的大脑低级。
为什么这么久
这个想法非常简单,不可能没有人想到过!事实上,Hinton数十年来一直在思考这个想法。没有发表的原因很简单,以前技术上没有实现的方法。其中一个原因是,在大约2012年之前,基于GPU进行运算的时代之前,计算机还不够强大。另一个原因是,没有一种算法可以实现并成功学习胶囊网络。这和反向传播的历史有些相似,人工神经元的概念早在20世纪40年代就出现了,而直到20世纪80年代中期,随着反向传播算法的实现,我们才能成功地训练深度网络。(实际上,反向传播算法在20世纪60年代就提出了,但直到1982年才应用到神经网络上。)
同样,胶囊这个概念本身并不算新,Hinton之前也提到过它,但是直到现在才出现了一种能够实现它的算法。这个算法叫做“囊间动态路由”。它允许胶囊之间相互通信,并创建类似计算机图形中场景图的表示。

和其他模型相比,胶囊网络在辨识上一列和下一列的图片属于同一类、仅仅视角不同方面,表现要好很多。最新的论文降低了45%的错误率,这是压倒性的优势
结论
胶囊引入了一个用于深度学习的新构件,以更好地建模神经网络中内部知识表示的分层关系。胶囊背后的直觉非常简单优雅。
Hinton和他的团队提出了一种训练这种胶囊组成的网络的方法,并在一个简单的数据集上成功完成训练,达到了最先进的效果。这是非常鼓舞人心的。
尽管如此,挑战依旧存在。胶囊网络的当前实现比其他现代深度学习模型慢很多。时间会告诉我们,是否能够快速高效地训练胶囊网络。此外,我们需要看看胶囊网络在更困难的数据集上和不同领域是否仍然表现良好。
无论如何,胶囊网络是一个非常有趣的模型,而且它现在就能工作。假以时日,它肯定会进一步发展,同时有助于深度学习应用领域的进一步扩展。
胶囊网络系列的第一篇就到这里了。在第二篇,我将逐步引导你了解CapsNet的内部机制,敬请期待。
原文地址:https://medium.com/@pechyonkin/understanding-hintons-capsule-networks-part-i-intuition-b4b559d1159b
本文系论智编译,转载请联系本公众号获得授权。
