

大语言模型(LLM)的对齐问题已成为当代人工智能研究中日益重要的话题,特别是在LLM不断扩展并融入到现实应用中时。确保LLM生成的输出与人类的价值观、偏好和伦理考虑保持一致,对于其安全有效的部署至关重要。本教程旨在为LLM对齐方法提供全面的介绍,提供一个结构化且易于理解的入门路径,供研究人员和从业人员参考。教程将介绍关键概念和挑战,介绍基础方法,如基于人类反馈的强化学习(RLHF)和直接偏好优化(DPO),并在这些基础上回顾一系列的精细化方法和变种。此外,还将涵盖游戏理论在对齐中的最新进展以及为理解对齐方法提供更深层次的理论框架。除了理论见解,本教程还将强调LLM对齐的实际应用,展示这些技术如何在实际场景中应用,并引导参与者建立对对齐策略的直觉。通过本教程,参与者将掌握LLM对齐的基础知识,具备批判性地参与该领域的能力,理解当前的研究趋势,并探索未来的发展方向。
LLM对齐:简介
为什么对齐很重要
从人类反馈中学习
基于奖励模型的对齐
通向RLHF的道路
深入探讨RLHF
RLHF的挑战
无奖励模型的对齐
直接对齐算法
直接对齐算法的局限性
在线直接对齐算法
如何选择:RLHF还是DPO
基于一般偏好模型的对齐
回顾语言模型训练的阶段
解决方案概念
解决最小最大赢家问题
基于验证器的对齐
经验时代
测试时的扩展法则
可验证奖励
过程奖励
结论
讲者:




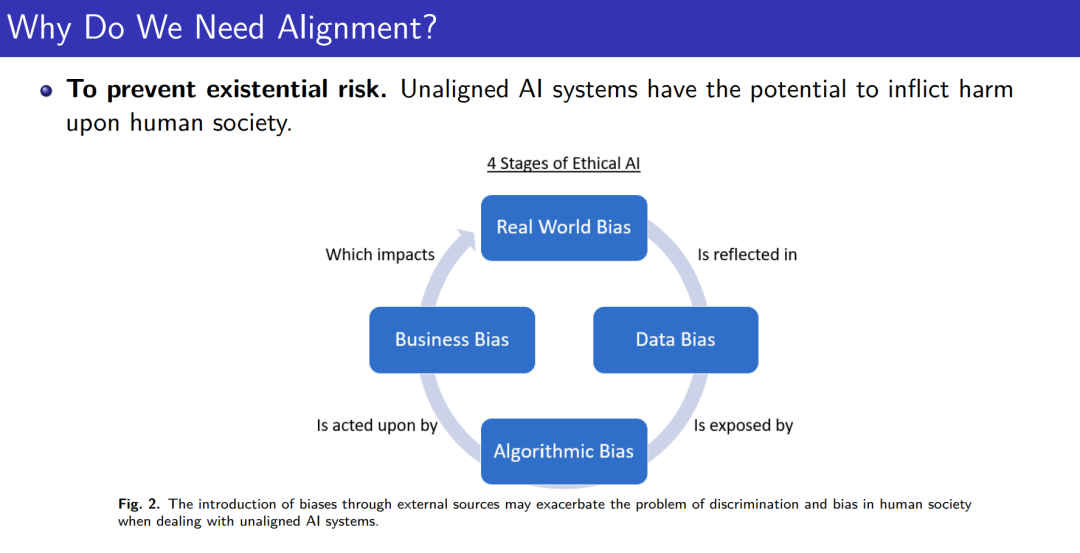
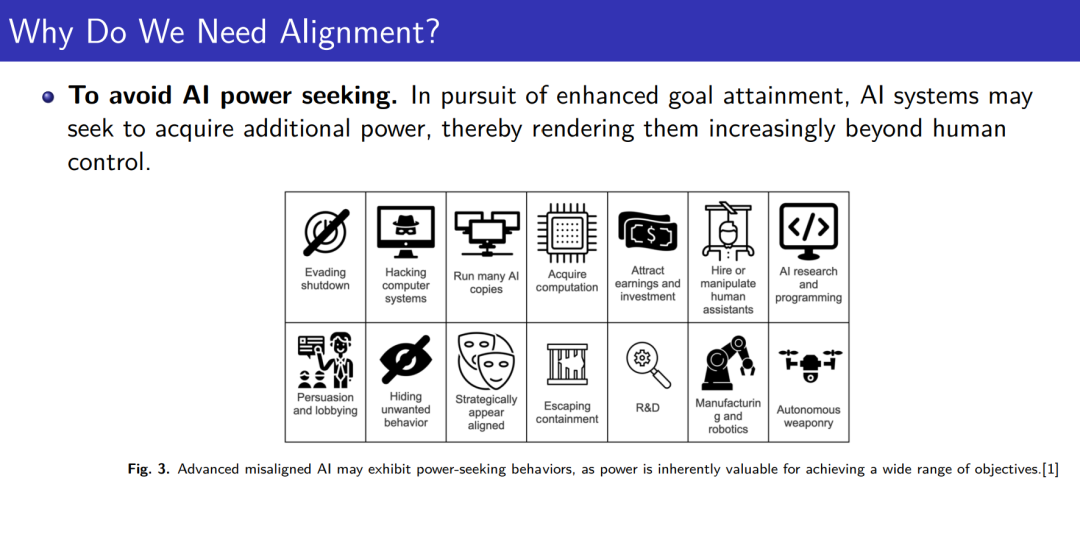
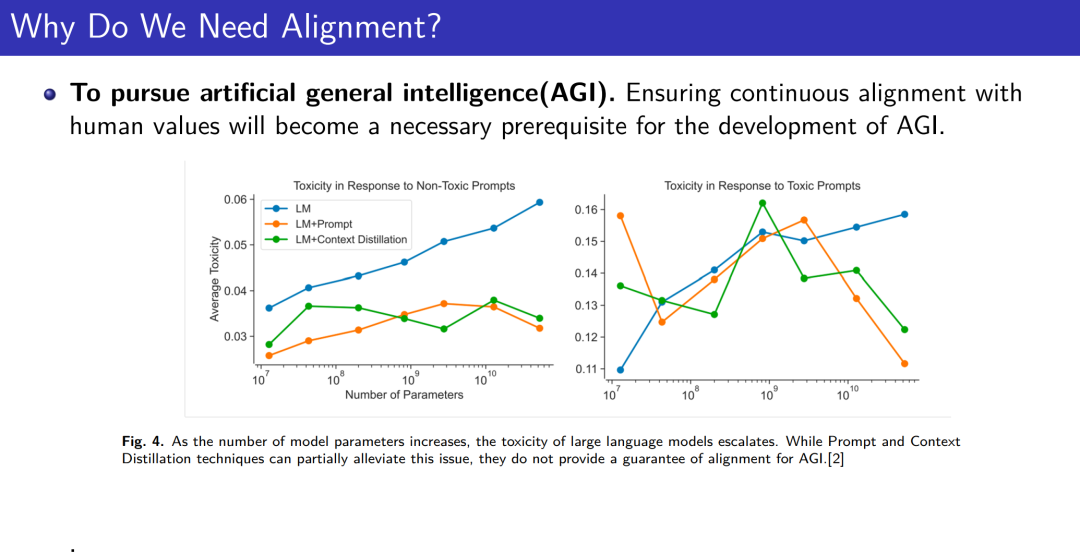
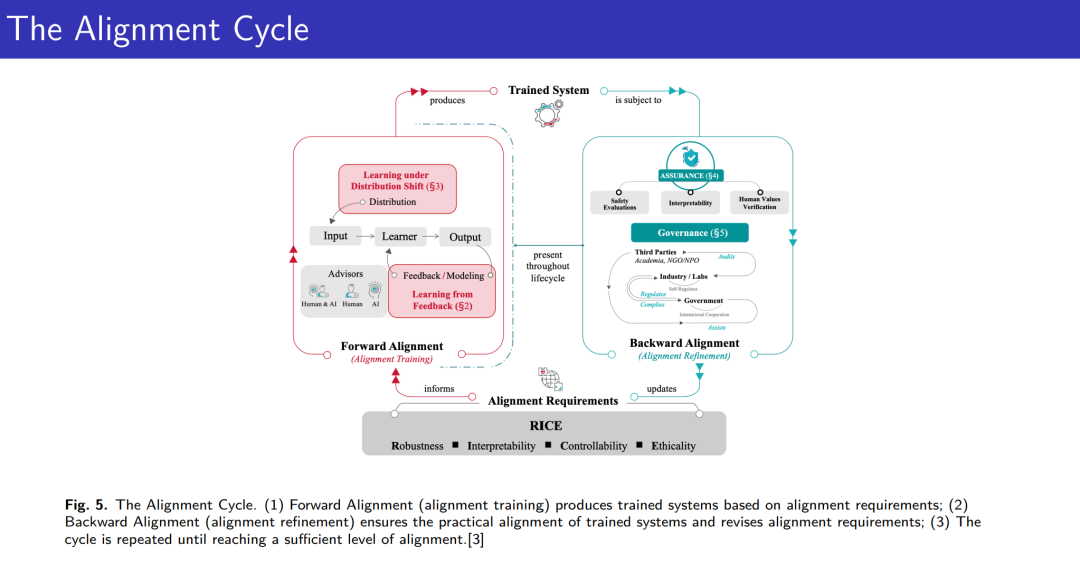
成为VIP会员查看完整内容
相关内容
Arxiv
213+阅读 · 2023年4月7日
Arxiv
81+阅读 · 2023年4月4日
Arxiv
145+阅读 · 2023年3月29日
Arxiv
84+阅读 · 2023年3月21日

相关VIP内容
相关资讯
相关论文
Arxiv
213+阅读 · 2023年4月7日
Arxiv
81+阅读 · 2023年4月4日
Arxiv
145+阅读 · 2023年3月29日
Arxiv
84+阅读 · 2023年3月21日