学界 | 北大、微软提出NGra:高效大规模图神经网络计算
选自 arxiv
作者:Lingxiao Ma 等
机器之心编译
参与:Geek AI、Chita
本文介绍了第一个基于图的神经网络并行处理框架,该框架提出的一种新模型可以在大型图上实现高效的计算。
目前,深度学习技术通常以深度神经网络(DNN)的形式展现。由于其在语音、视觉和自然语言处理等领域所取得的成功,深度学习技术越来越受欢迎。在这些领域中,底层数据表征的坐标通常具有规则的网格结构,这有利于包含大量类似于单指令多数据流(SIMD)数据并行运算的硬件加速机制(例如 GPU)。目前,将深度学习模型应用在具有不规则图结构的数据上成为了一种新兴的趋势 [9, 22, 25, 13, 15, 4, 5, 29],这种趋势是由诸如社交网络、知识图谱、以及生物信息学和神经科学(例如,蛋白质之间的交互或大脑中的神经元连接)中的图形的重要性所驱动的。这种趋势也促使人们在其目标应用(例如,分类、嵌入、问答系统)上取得了当前最佳的结果。这些基于图的神经网络(GNN)通常将神经网络模型应用在图中与顶点和边相关的特征上,传播运算结果并进行聚合,从而生成下一级的特征。
现有的解决方案都不能很好地支持 GNN。现有的图处理引擎 [28,26,11,6,41] 往往会提供一个类似于信息收集(Gather)——应用(Apply))——结果分发(Scatter)的 GAS 顶点程序模型,但这种方式无法在图结构中表达和支持神经网络架构。TensorFlow[3]、PyTorch[2]、MxNet[8]、CNTK[42] 等深度学习框架旨在将神经网络表示为数据流图,但并不直接支持图传播模型。此外,它们都不能提供处理大型图所需的可扩展性,也不支持基于 GPU 的图传播 operator(将图传播转换为稀疏操作)的高效实现。当前缺乏对这些需求的支持严重限制了充分挖掘大规模 GNN 潜力的能力,同时也为 DNN 与大型图结构的结合在系统层面上提出了巨大的挑战。
在本文中,作者介绍了首次实现支持大规模 GNN 的 NGra 系统,它从一个易于表达的编程模型发展到一个可扩展的、高效 GPU 并行处理引擎。NGra 将数据流与顶点程序的抽象自然地结合在了一个名为 SAGA-NN(Scatter-Apply Edge Gather-Apply Vertex with Neural Networks)的新模型中。SAGA 可以被认为是一个 GAS 模型的变体,SAGA-NN 模型中由用户定义的函数使用户能够通过使用数据流抽象(而不是使用那些为处理传统图问题如 PageRank、连通分量、最短路径而设计的算法)在顶点或边数据(以张量形式被处理)上表达神经网络计算。
与在深度神经网络上的情况一样,高效使用 GPU 对 GNN 的性能至关重要,而且由于处理大型图结构的额外挑战,对 GPU 的使用就显得更为关键了。为了实现超越 GPU 物理限制的可扩展性,NGra 显式地将图结构划分(顶点和边数据)成块,将一个在 SAGA-NN 模型中表达的 GNN 算法转成了具有块粒度 operator 的数据流图,通过该数据流图,作者可以在单个或多个 GPU 上进行基于块的并行流处理。
然后,NGra 引擎的效率在很大程度上取决于 NGra 如何管理和调度并行流的处理过程,以及如何在 GPU 上实现关键的图传播 operator(结果分发和信息收集)。NGra 十分关注数据的位置,从而尽量减少 GPU 内存内外的数据交换,最大限度地提高 GPU 内存中数据块的重用性,同时以流形式同时进行数据迁移和计算。对于多 GPU 的情况,它使用了一种基于环的流机制,通过在 GPU 之间直接交换数据块来避免主机内存中的冗余数据迁移。SAGA-NN 模型中的结果分发和信息收集阶段执行沿着边的顶点数据传播,在稀疏结构上表现为矩阵乘法。众所周知,在像 GPU 这样数据并行的硬件上执行稀疏的矩阵操作是非常困难的。因此,NGra 将图传播引擎支持的特殊 operator 引入到数据流图中,并优化其在 GPU 上的执行。请注意,与其 基于 GPU 的图引擎所关注的传统图处理场景不同,在 GNN 的场景下,由于每个顶点的数据可能就是一个特征向量,而不是简单的标量,可变顶点数据本身可能无法被容纳到 GPU 设备内存中。因此,本文的方案更倾向于利用每个顶点数据访问中的并行性来提高内存访问效率。
作者使用顶点程序抽象和用于图传播过程的自定义 operater 对 TensorFlow 进行扩展,从而实现 NGra。结果证明 NGra 可以被扩展,然后通过利用单个服务器的主机内存和 GPU 的计算能力,实现在(包含数百万顶点和数百特征维度以及数亿边的)大型图上对 GNN 算法的支持,而这不能直接通过使用现有的深度学习框架实现。与可以通过 GPU 支持的小型图上的 TensorFlow 相比,NGra 可以取得大约 4 倍的运算加速。作者还对 NGra 中的多个优化所带来的性能提升进行了广泛的评估,以证明它们的有效性。
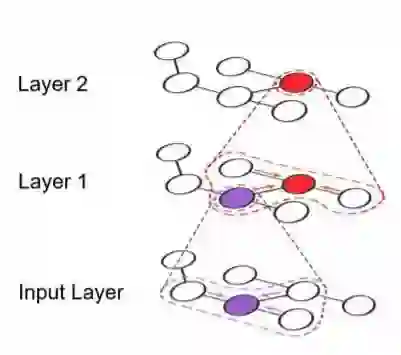
图 1:双层 GNN 的前馈运算过程
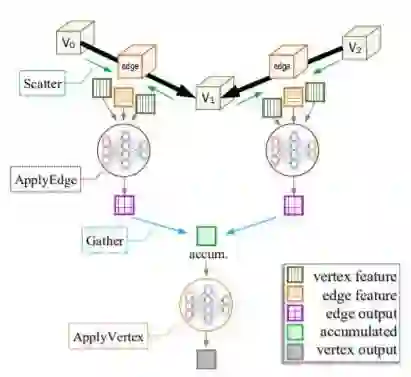
图 3:GNN 中每一层的 SAGA-NN 运算流程
NGra 系统
NGra 以用户接口的形式提供了数据流和定点程序抽象的组合。在这种抽象之下,NGra 主要由以下几部分组成:(1)一个将 SAGA-NN 模型中实现的算法转换为块粒度数据流图的前端,它使得大型图上的 GNN 计算可以在 GPU 中被实现;(2)一个制定最小化主机与 GPU 设备内存之间数据迁移调度策略的优化层,它能够找到进行融合操作和去除冗余计算的机会;(3)一组高效的传播操作内核,它支持针对 GPU 中重复的数据迁移和计算的基于流的处理;(4)在运行时执行数据流。由于 NGra 在很大程度上利用了现有的基于数据流的深度学习框架来实现在运行时执行数据流,因此作者将重点放在本节前三个框架的设计上,因为它们是 NGra 系统的主要贡献。
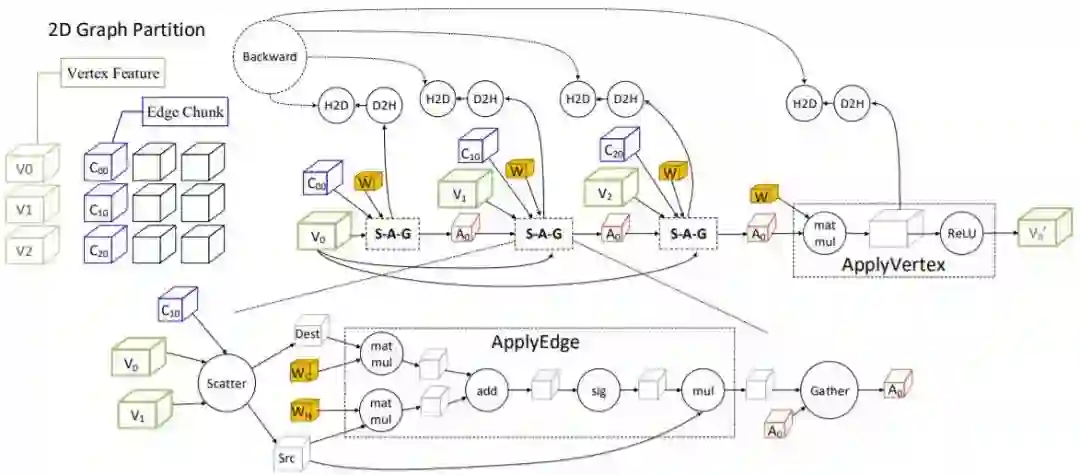
图 4:用于 G-GCN 层上目标区间 V0 的基于块的数据流图。为了得到更清晰的可视化结果,在连接到 D2H 时,SAG 阶段输出张量置换被隐藏在了 SAG 的子图中。
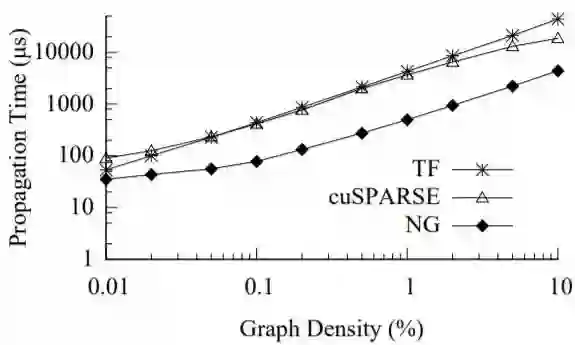
图 13:TensorFlow(TF),cuSPARSE,以及 NGra(NG)在不同密度的图上传播内核的时间。
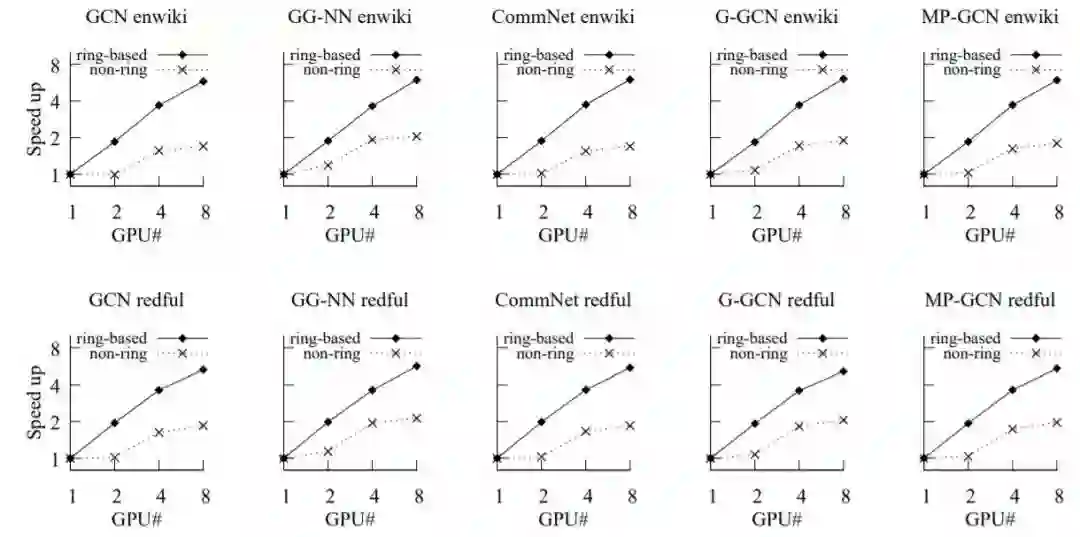
图 16: 在大型图上的不同应用中使用 NGra 的加速情况
论文:Towards Efficient Large-Scale Graph Neural Network Computing

论文地址:https://arxiv.org/abs/1810.08403
最近的深度学习模型已经从低维的常规网格(如图像、视频和语音)发展到了高维的图结构数据(如社交网络、大脑连接和知识图谱)上。这种演进催生了基于大型图的不规则和稀疏模型,这些模型超出了现有深度学习框架的设计范围。此外,这些模型不容易适应在并行硬件(如 GPU)上的有效大规模加速。
本文介绍了基于图的深度神经网络(GNN)的第一个并行处理框架 NGra。NGra 提出了一种新的 SAGA-NN 模型,用于将深度神经网络表示为顶点程序,其每一层都具有定义好的(结果分发、应用边、信息收集、应用顶点)图操作阶段。该模型不仅可以直观地表示 GNN,而且便于映射到高效的数据流表示。NGra 通过自动图形划分和基于块的流处理(使用 GPU 核心或多个 GPU),显式地解决了可扩展性的挑战,它仔细考虑了数据位置、并行处理和数据迁移的重叠等问题。NGra 虽然是稀疏的,但通过对 GPU 上的结果分发/信息收集 operator 进行高度优化,进一步提高了效率。本文的评估结果表明,NGra 可以扩展到任何现有框架都无法直接处理的大型真实图结构上,同时即使是在小规模的 TensorFlow 的多基线设计上,也可以实现高达 4 倍的加速。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


