【AAAI2020-清华大学】张量图卷积网络(TensorGCN)文本分类
【导读】 图神经网络(GNN,Graph Neural Networks)用于图结构数据的深度学习架构,具有强大的表征建模能力,将端到端学习与归纳推理相结合,业界普遍认为其有望解决深度学习无法处理的因果推理、可解释性等一系列瓶颈问题。图神经网络在文本分类也有深入的应用,AAAI2019有图卷积神经网络(GCN)文本分类详述,更进一步,在AAAI2020上,清华大学科大讯飞的学者提出张量卷积神经网络在文本分类的应用Tensor Graph Convolutional Networks for Text Classification,进一步提高文本分类的性能。

介绍
01
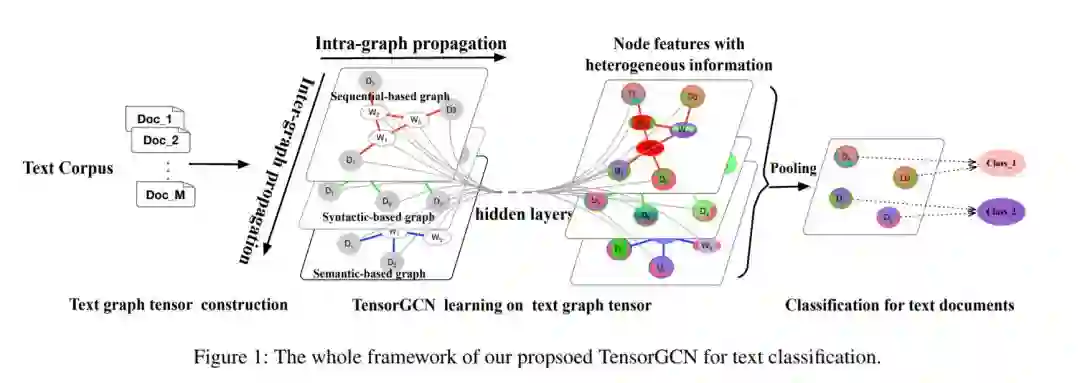
方法
02
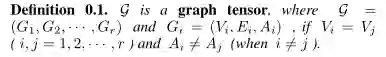
-
G_i是图张量G中的第i个图 -
V_i(丨V_i丨=n)是第i个图中的节点的集合 -
E_i是第i个图中的边的集合 -
A_i是第i个图的邻接矩阵
-
A_i是图向量G中第i个图的邻接矩阵
-
l表示GCN的层数 -
H^{l}_i图向量G中第i个图的特征矩阵 -
图特征张量H(0)表示初始化的输入特征

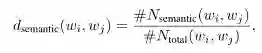
-
d_semantic(w_i, w_j)表示词w_i与w_j之间的边权重 -
#N_semantic(w_i, w_j)表示两个词在语料库中的所有句子/文档中具有语义关系的次数 -
#N_total表示两个词在整个语料库中出现在同一句子/文档中的次数。
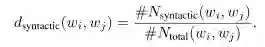
-
d_semantic(w_i, w_j)表示词w_i与w_j之间的边权重 -
#N_semantic(w_i, w_j)是两个词在语料库中的所有句子/文档中具有句法依赖关系的次数 -
#N_total表示两个词在整个语料库中出现在同一句子/文档中的次数。
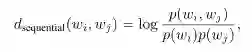
-
p(w_i,w_j)是单词对(w_i,w_j)在同一滑动窗口中出现的概率,可以通过下式计算:
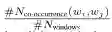
-
#N_windows是整个文本语料库的滑动窗口总数 -
#N_co-ocurence(w_i,w_j)是单词对(w_i,w_j)在整个文本语料库的相同滑动窗口中出现的次数。 -
p(w_i)是单词w_i出现在文本语料库上固定窗口中的概率:
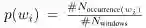
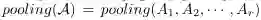
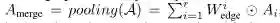
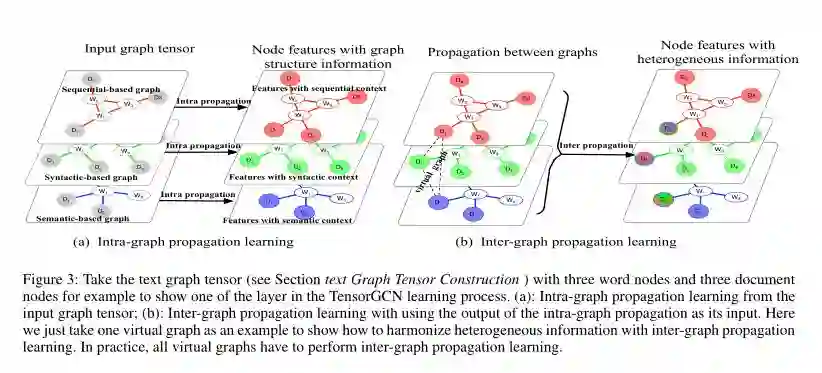
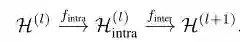
-
H^{l}∈R^{r×n×d_l} -
f_intra和f_inter分别表示图内传播和图间传播
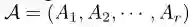
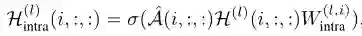
-
^A是由一系列归一化对称邻接矩阵组成的归一化对称图邻接张量 -
W^(l,i)_intra是第i个图在第l层的权重矩阵
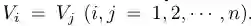
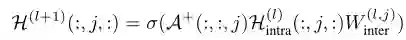
-
H^{l+1}∈R^{r×n×d_l+1}是图间传播的输出,也是TensorGCN中l+1层的输入特征张量 -
W^(l,j)_inter是图间传播的可训练权重 -
A^+(:,:,j)既不用于对称归一化也不添加自连接 -
虚拟图中的所有节点彼此连接,并且边权重被设置为1
实验
03

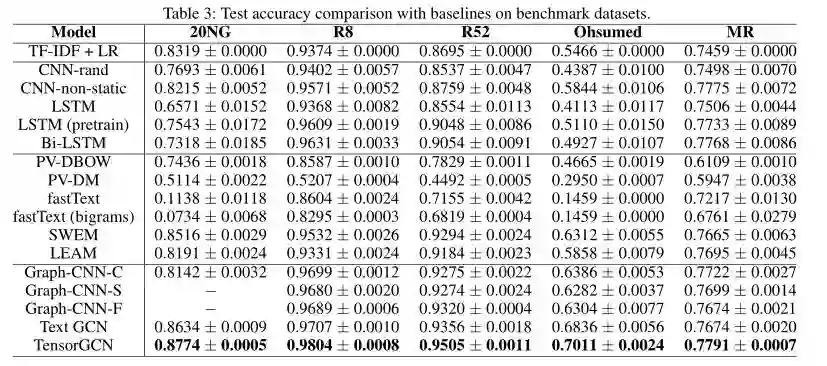
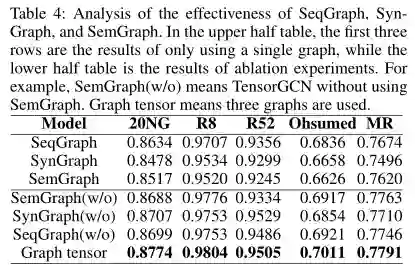
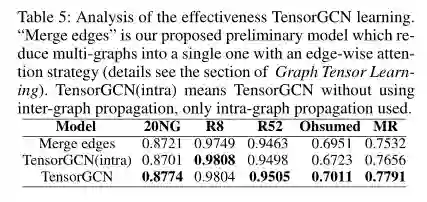
结论
04
便捷查看下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“TGCN” 就可以获取《张量图卷积网络(TensorGCN)文本分类》专知资源链接索引



登录查看更多
相关内容

专知会员服务
76+阅读 · 2020年1月16日
专知会员服务
80+阅读 · 2019年11月5日
Arxiv
13+阅读 · 2019年5月22日




相关VIP内容
专知会员服务
76+阅读 · 2020年1月16日
专知会员服务
80+阅读 · 2019年11月5日
相关资讯
相关论文
Arxiv
13+阅读 · 2019年5月22日