

以语音为中心的机器学习系统彻底改变了许多领先领域,从交通和医疗保健到教育和国防,深刻改变了人们的生活、工作和相互互动的方式。然而,最近的研究表明,许多以语音为中心的机器学习系统可能需要被认为更值得信任,以便更广泛地部署。具体来说,在机器学习研究领域,人们都发现了对隐私泄露、判别性能和对抗性攻击脆弱性的担忧。为了应对上述挑战和风险,人们做出了大量努力,以确保这些机器学习系统是值得信任的,特别是隐私、安全和公平。本文首次对与隐私、安全和公平相关的、以语音为中心的可信机器学习主题进行了全面的调研。除了作为研究界的总结报告外,本文指出了几个有希望的未来研究方向,以激励希望在该领域进一步探索的研究人员。 引言
在过去的几年中,机器学习(ML),特别是深度学习,在各种研究领域和应用中取得了巨大的突破,包括自然语言处理(Devlin等人,2018)、图像分类(He等人,2016)、视频推荐(Davidson等人,2010)、医疗保健分析(Miotto等人,2018),甚至掌握国际象棋游戏(Silver等人,2016)。深度学习模型通常由多个处理层组成,并结合了线性和非线性操作。尽管训练具有多层架构的深度学习模型需要积累大型数据集和访问强大的计算基础设施(Bengio等人,2021),但与传统的建模方法相比,训练后的模型通常达到最先进的(SOTA)性能。深度学习的广泛成功还允许更深入地了解人类状况(状态、特征、行为、交互)和革命性的技术,以支持和增强人类体验。除了ML在上述领域取得的成功,以语音为中心的ML也取得了重大进展。 言语是人类之间一种自然而突出的交流形式。它存在于人类生活的几乎每一个层面,无论是与朋友聊天、与同事讨论,还是与家人远程通话。以语音为中心的机器学习的进步使Siri、谷歌Voice和Alexa等智能助手的普遍使用成为可能。此外,以语音为中心的建模在人类行为理解、人机界面(HCI) (Clark等人,2019)和社交媒体分析方面创造了许多研究主题。例如,一些广泛研究的语音建模领域包括自动语音识别(Malik et al., 2021)、语音情感识别(Akçay和Oğuz, 2020)、自动说话人确认(Irum和Salman, 2019)和关键词识别(Warden, 2018)。
尽管ML系统有在广泛的以语音为中心的应用中广泛部署的前景,但在大多数这些系统中,两个交织在一起的挑战仍然没有解决:理解和阐明跨人和环境的丰富多样性,同时创建可信的ML技术,在所有环境中适用于每个人。信任是人类生活的基础,无论是信任朋友、同事、家庭成员,还是像人工智能服务这样的人工制品。传统上,机器学习从业者,如研究人员和决策者,使用系统性能(如F1分数)来评估机器学习系统。虽然大量的研究都集中在提高机器学习模型的系统性能上,但确保机器学习应用是可信的仍然是一个具有挑战性的课题。在过去的几年中,我们见证了大量针对可信人工智能和机器学习的研究工作,本文的目标是对相关研究活动进行全面的回顾,重点以语音为中心的机器学习。
**ML中的可信性在不同的文献中有不同的定义。**例如,Huang等人(2020)基于涉及认证过程和解释过程实施的行业生产实践规范描述了术语可信性。认证过程包括测试和验证模块,以检测输入数据中潜在的伪造或干扰。解释是解释机器学习为什么根据输入数据做出特定决策的能力。此外,欧盟发布的《可信人工智能伦理准则》(Smuha, 2019)承认,要被认为是可信的人工智能系统,必须遵守法律和法规,坚持道德原则,并强大地运行。最近,Liu等人(2022b)从安全性、公平性、可解释性、隐私、可问责性和环境友好方面总结了可信人工智能。同样,我们的审查认为,可信的核心设计元素是鲁棒性、可靠性、安全性、安全性、包容性和公平性。基于这些标准,本文从隐私、安全和公平的角度综述了关于以语音为中心的可信机器学习的文献,如图1.1所示:
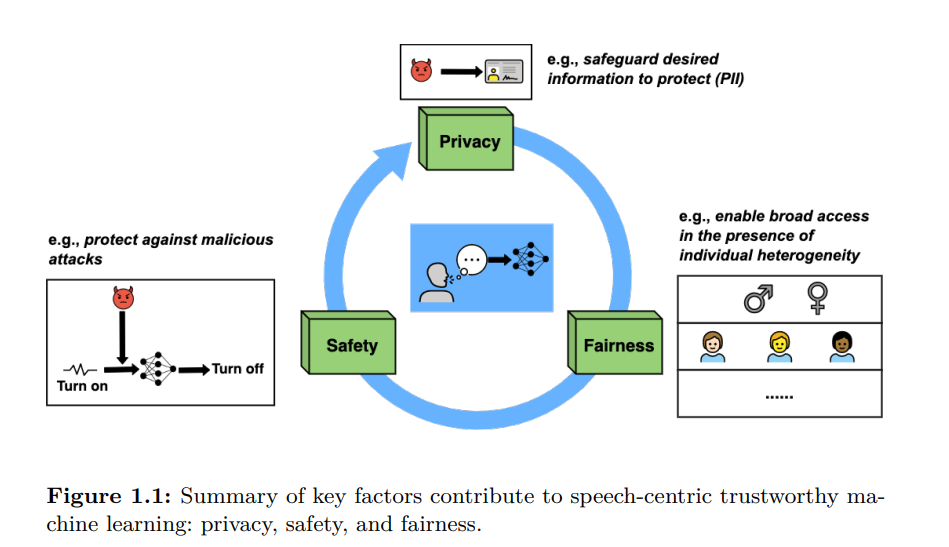
**隐私: **以语音为中心的ML系统严重依赖于收集来自、关于和针对潜在敏感环境和上下文中的人的语音数据,例如家庭、工作场所、医院和学校。语音数据的收集经常引起人们对侵犯用户隐私的严重担忧,例如泄露人们可能希望保密的敏感信息(Liu等人,2021)。至关重要的是,要确保由个人共享或由ML系统收集的语音数据受到保护,免受任何不合理和未经授权的使用。
安全性: 在过去几年中,研究人员发现机器学习系统普遍容易受到对抗性攻击,这些攻击旨在利用模型预测函数中的漏洞进行恶意的目的(Goodfellow等人,2014)。例如,通过对语音数据引入足够小的扰动,恶意行为者可以导致关键词检测模型对所需的输入语音命令进行错误分类。因此,一个可信的机器学习系统必须对恶意攻击者可能故意更改的相同输入输出一致。
**公平性:**最近人们知道机器学习系统的行为可能不公平。机器学习系统为什么会虐待人是多方面的(Mehrabi等人,2021)。一个因素是社会方面,由于训练数据或整个机器学习开发过程中的假设/决策中的社会偏见,机器学习系统产生有偏的输出。导致人工智能不公平的另一个原因是数据集特征的不平衡,某些群体的数据样本有限。因此,模型需要考虑某些人群的需求。同样重要的是要注意,部署不公平的机器学习系统可能会放大社会偏见和数据不平衡问题。为了评估以语音为中心的机器学习系统的可信性,机器学习从业者需要评估机器学习模型是否对个人或群体表现出区分性。
**本文的其余部分组织如下。**第2节简要总结了流行的以语音为中心的任务、数据集和SOTA建模框架。第3节全面讨论了以语音为中心的机器学习系统中的安全考虑。第4节讨论了语音建模中的隐私风险和防御。第5节回顾了语音建模任务中出现的公平性问题。第6节阐述了以语音为中心的可信机器学习的潜在发展和未来的挑战。最后,第7节总结了本文的主要观点。
具体而言,我们的贡献总结如下:
-
据我们所知,这是第一个对设计可信的、以语音为中心建模的机器学习进行全面回顾的综述工作。我们调研了大部分已经发表和预印本的工作,包括自动语音识别、语音情感识别、关键词识别和自动说话人验证。
-
创建了分类法,以系统地审查与以语音为中心的机器学习系统可信性相关的设计支柱。我们进一步比较了关于每个关键因素的各种文献。
3.本文讨论了设计以语音为中心的机器学习系统面临的突出挑战,这些系统面临着与隐私、安全和公平相关的可信性考虑。在文献综述的基础上,讨论了有待解决的挑战,并提出了几个有希望的未来方向。




