【导读】深度生成模型在数据生成方面具有很好的优势,但是在很多实际应用场景可能面临投毒攻击等威胁。本文探究攻击和模型架构之间的内在联系,更具体地说,深入生成模型的五个组成部分: 训练数据、潜在代码、GAN和VAEs的生成器/解码器、GAN和VAEs的识别器/编码器和生成的数据。
![]()
深度生成模型因其为各种应用生成数据的能力而备受关注,这些应用包括医疗保健、金融技术、监控等,其中最受欢迎的模型是生成对抗网络和变分自动编码器。然而,与所有机器学习模型一样,人们一直担心安全漏洞和隐私泄露,深度生成模型也不例外。近年来,这些模型发展迅速,以至于对其安全性的研究仍处于起步阶段。为了应对当前和未来针对这些模型的威胁,并在短期内为防御准备提供路线图,我们准备了这份关于GAN和VAEs安全性和隐私保护的全面和专门调研。我们的重点是探究攻击和模型架构之间的内在联系,更具体地说,深入生成模型的五个组成部分:训练数据、潜在代码、GAN和VAEs的生成器/解码器、GAN和VAEs的识别器/编码器和生成的数据。针对每个模型、组件和攻击,我们回顾了当前的研究进展,并确定了关键挑战。最后对该领域未来可能的攻击和研究方向进行了讨论。
https://www.zhuanzhi.ai/paper/ec2d0f84bfaa49189d9c478a3a76dcd4
深度生成模型的对抗性攻击
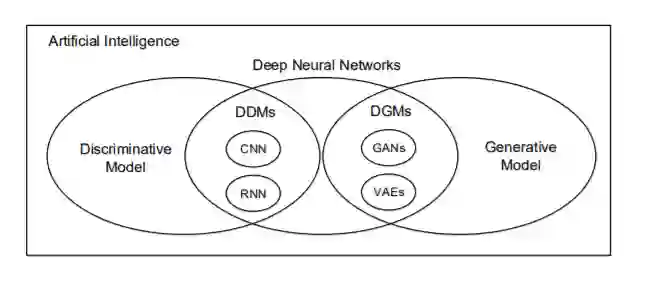
在过去的几年里,计算能力的提高使得深度神经网络在各种应用中取得了成功。在这一类别中,有两类深度学习模型:生成型和判别型。生成模型拟合我们可以在我们的世界中观察到的数据,比如貌似真实的人脸照片[1]。总的来说,这些被称为深度生成模型(DGMs)。另一种是将观察到的数据分成不同的类,如人脸识别、推荐系统等[2]。这类模型被称为深度判别模型(DDMs)[3]。最流行的DGM是生成对抗网络(GANs)[4]和变分自动编码器(VAEs)[5]。两者都广泛用于生成真实的照片[6],合成视频[7],翻译一个图像到另一个[8],等等。与传统DDMs一样,递归神经网络(RNN)[9]、卷积神经网络(CNN)[10]及其变体在情绪分析[11]、图像识别[12]、自然语言处理[13]、[14]等方面表现良好。AI景观关系图如图1所示。
![]()
人工智能有两个主要分支,生成模型和判别模型。这些模型的深层神经网络变体已经进化为生成侧的VAEs和GANs,以及判别侧的RNNs和CNNs。
与任何具有广泛影响的技术一样,模型安全和隐私问题是不可避免的。
当然,任何对手都有两个愿望。第一种是破坏模型,使它的工作不能令人满意。第二种是侵犯隐私。例如,破坏一个模型,一个攻击者可能会把一个本应生成人像肖像的模型变成一个生成鞋子[15]图片的模型,或者不是正确地将图片分类为熊猫,而是将它们归类为长臂猿[16]。侵犯隐私可能包括窃取训练数据或整个训练模型。一个著名的例子是,对手通过黑箱查询Amazon的机器学习即服务平台[17]提供的api复制了Amazon训练的模型。同样的策略被用来恢复训练集,从而获得私人信息[18],[19]。
中毒攻击[20],[21]和逃避攻击[16],[22]都试图强迫一个模型做不令人满意的工作。
在训练阶段进行投毒攻击,并试图在阵型阶段损害模型的能力。回避攻击在测试阶段起作用,其目的是为训练的模型提供对抗输入,使其产生不满意的输出。对抗性输入通常被称为对抗性例子。在组件级别,有几种不同类型的攻击。在数据层,我们有成员推理攻击,它试图推断一个给定样本是否属于模型的训练集[18],还有模型反演攻击,它试图根据一些先验信息和模型的输出[19]重建部分或全部的训练数据。在属性层,我们有属性推断攻击,它试图推断数据[23]的敏感属性。模型提取攻击在模型级别工作。这是一个严重的威胁试图复制整个训练模型[17]。尽管对这些针对DGMs的攻击的研究还处于起步阶段,但关于与DDMs相关的安全和隐私问题,已有大量健康的文献。例如,Papernot等人提出了一个详细的安全与隐私攻击的对抗性框架,其中包括对抗性示例、成员推理攻击策略以及一些防御方法[24]。针对场景和应用,Liu等人对攻击类型和保护方案类型[25]进行了分类。Serban等人详细阐述了对抗的例子,包括他们的建设,防御策略,和转移能力[26]。由于差异隐私是减轻隐私泄露的最有效措施之一,Gong等人发表了一篇关于差异隐私机器学习[27]的全面综述。关于DDMs,特别是CNNs和RNNs的调查也有0个,见[28]-[32]。
正如本次综述所显示的,对于DGMs而言,工作要少得多。我们综述揭示了以下研究论文: 中毒攻击[33]、[34]; 规避攻击[15],[35]- [40]; 成员推理攻击[41]- [46]; 属性推断攻击[46],模型提取攻击[47]。据我们所知,没有关于DGMs的安全和隐私的综述。然而近年来,GANs和VAEs的发展使得DGMs得到了越来越多的关注,既有善意的,也有恶意的。因此,我们认为现在是彻底调研这些攻击以及它们的防御的时候了。通过比较DGM攻击和DDM攻击及其已知防御,我们可能能够识别它们之间的一些关键差距。
在基本层面上,对抗性攻击是关于策略的演变。上面提到的攻击最初是为判别模型设计的,DGM与DDM的目的非常不同。因此,训练算法和模型架构也有很大的不同。因此,要对DGM进行传统的攻击,必须对攻击策略进行更新。单一的攻击策略无法揭示这种演变的总体方向。相反,需要进行全面的综述
进化后的攻击是否会成为通用的DGM是另一个担忧。因为VAEs和GANs有多种变体,例如beta-VAEs[48]和Wasserstein GANs[49]以及其他不太流行的DGMS类型,所以通用性是有意义的。
简要介绍了最流行的DGM——VAEs和GANs,从它们的标准模型结构和训练程序开始,以DGM和DDM体系结构的比较结束。
分析各种攻击的可行性,考虑到两个对抗目标——破坏模型的正常功能和危及隐私——以及模型各个组件的脆弱性。本节还对常见的攻击策略进行了分类。
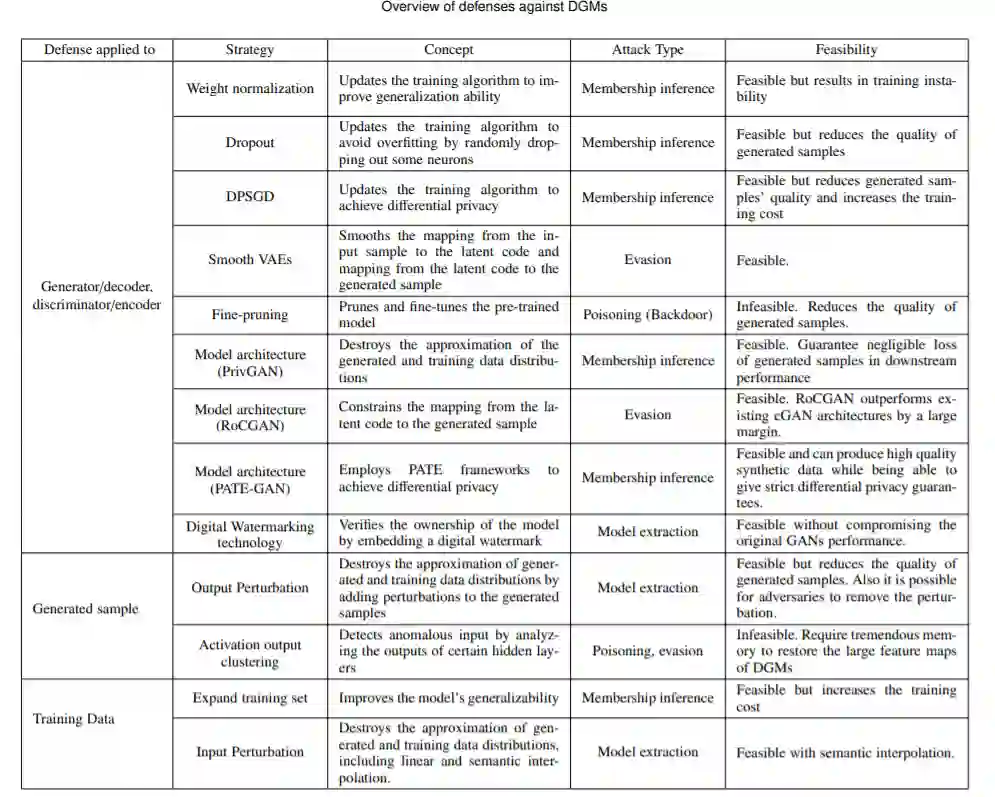
对现有防御方案的总结和可能的防御方法的讨论,考虑到防御的稀缺性,这构成了未来研究的主要方向。
对其他值得进一步关注的富有成果的研究机会的建议。
![]()
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
专知,专业可信的人工智能知识分发
,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取5000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取5000+AI主题知识资源