【导读】分布式机器学习Distributed Machine Learning是学术界和工业界关注的焦点。最近来自荷兰的几位研究人员撰写了关于分布式机器学习的综述,共33页pdf和172篇文献,概述了分布式机器学习相对于传统(集中式)机器学习的挑战和机遇,讨论了用于分布式机器学习的技术,并对可用的系统进行了概述,从而全面概述了该领域的最新进展。
论文地址: https://www.zhuanzhi.ai/paper/161029da3ed8b6027a1199c026df7d07
摘要 在过去的十年里,对人工智能的需求显著增长,而机器学习技术的进步和利用硬件加速的能力推动了这种增长。然而,为了提高预测的质量并使机器学习解决方案在更复杂的应用中可行,需要大量的训练数据。虽然小的机器学习模型可以用少量的数据进行训练,但训练大模型(如神经网络)的输入随着参数的数量呈指数增长。由于处理训练数据的需求已经超过了计算机器计算能力的增长,因此需要将机器学习的工作负载分布到多台机器上,并将集中式的学习任务转换为分布式系统。这些分布式系统提出了新的挑战,首先是训练过程的有效并行化和一致模型的创建。本文概述了分布式机器学习相对于传统(集中式)机器学习的挑战和机遇,讨论了用于分布式机器学习的技术,并对可用的系统进行了概述,从而全面概述了该领域的最新进展。
1. 引言
近年来,新技术的快速发展导致了数据采集的空前增长。机器学习(ML)算法正越来越多地用于分析数据集和构建决策系统,因为问题的复杂性,算法解决方案是不可行的。例如控制自动驾驶汽车[23],识别语音[8],或者预测消费者行为[82]。
在某些情况下,训练模型的长时间运行会引导解决方案设计者使用分布式系统来增加并行性和I/O带宽总量,因为复杂应用程序所需的训练数据很容易达到tb级的[29]。在其他情况下,当数据本身就是分布式的,或者数据太大而不能存储在一台机器上时,集中式解决方案甚至都不是一个选项。例如,大型企业对存储在不同位置的[19]的数据进行事务处理,或者对大到无法移动和集中的天文数据进行事务处理[125]。
为了使这些类型的数据集可作为机器学习问题的训练数据,必须选择和实现能够并行计算、数据分布和故障恢复能力的算法。在这一领域进行了丰富多样的研究生态系统,我们将在本文中对其进行分类和讨论。与之前关于分布式机器学习([120][124])或相关领域的调查([153][87][122][171][144])相比,我们对该问题应用了一个整体的观点,并从分布式系统的角度讨论了最先进的机器学习的实践方面。
第2节深入讨论了机器学习的系统挑战,以及如何采用高性能计算(HPC)的思想来加速和提高可扩展性。第3节描述了分布式机器学习的参考体系结构,涵盖了从算法到网络通信模式的整个堆栈,这些模式可用于在各个节点之间交换状态。第4节介绍了最广泛使用的系统和库的生态系统及其底层设计。最后,第5节讨论了分布式机器学习的主要挑战
2. 机器学习——高性能计算的挑战?
近年来,机器学习技术在越来越复杂的应用中得到了广泛应用。虽然出现了各种相互竞争的方法和算法,但所使用的数据表示在结构上惊人地相似。机器学习工作负载中的大多数计算都是关于向量、矩阵或张量的基本转换——这是线性代数中众所周知的问题。优化这些操作的需求是高性能计算社区数十年来一个非常活跃的研究领域。因此,一些来自HPC社区的技术和库(如BLAS[89]或MPI[62])已经被机器学习社区成功地采用并集成到系统中。与此同时,HPC社区已经发现机器学习是一种新兴的高价值工作负载,并开始将HPC方法应用于它们。Coates等人,[38]能够在短短三天内,在他们的商用现货高性能计算(COTS HPC)系统上训练出一个10亿个参数网络。You等人[166]在Intel的Knights Landing(一种为高性能计算应用而设计的芯片)上优化了神经网络的训练。Kurth等人[84]证明了像提取天气模式这样的深度学习问题如何在大型并行高性能计算系统上进行优化和快速扩展。Yan等人[163]利用借鉴于HPC的轻量级概要分析等技术对工作负载需求进行建模,解决了在云计算基础设施上调度深度神经网络应用程序的挑战。Li等人[91]研究了深度神经网络在加速器上运行时对硬件错误的弹性特性,加速器通常部署在主要的高性能计算系统中。
与其他大规模计算挑战一样,加速工作负载有两种基本的、互补的方法:向单个机器添加更多资源(垂直扩展或向上扩展)和向系统添加更多节点(水平扩展或向外扩展)。
3. 一个分布式机器学习的参考架构

图1 机器学习的概述。在训练阶段,利用训练数据和调整超参数对ML模型进行优化。然后利用训练后的模型对输入系统的新数据进行预测。
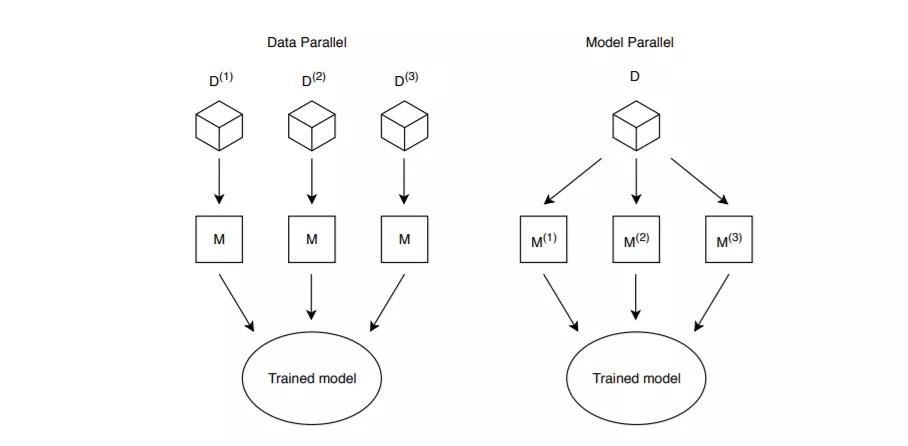
图2 分布式机器学习中的并行性。数据并行性在di上训练同一个模型的多个实例!模型并行性将单个模型的并行路径分布到多个节点。
机器学习算法
机器学习算法学习根据数据做出决策或预测。我们根据以下三个特征对当前的ML算法进行了分类:
反馈、在学习过程中给算法的反馈类型
目的、期望的算法最终结果
方法、给出反馈时模型演化的本质
反馈 训练算法需要反馈,这样才能逐步提高模型的质量。反馈有几种不同类型[165]:
包括 监督学习、无监督学习、半监督学习与强化学习
目的 机器学习算法可用于各种各样的目的,如对图像进行分类或预测事件的概率。它们通常用于以下任务[85]: 异常检测、分类、聚类、降维、表示学习、回归
每一个有效的ML算法都需要一种方法来迫使算法根据新的输入数据进行改进,从而提高其准确性。通过算法的学习方式,我们识别出了不同的ML方法组: 演化算法、随机梯度下降、支持向量机、感知器、神经网络、规则机器学习、主题模型、矩阵分解。
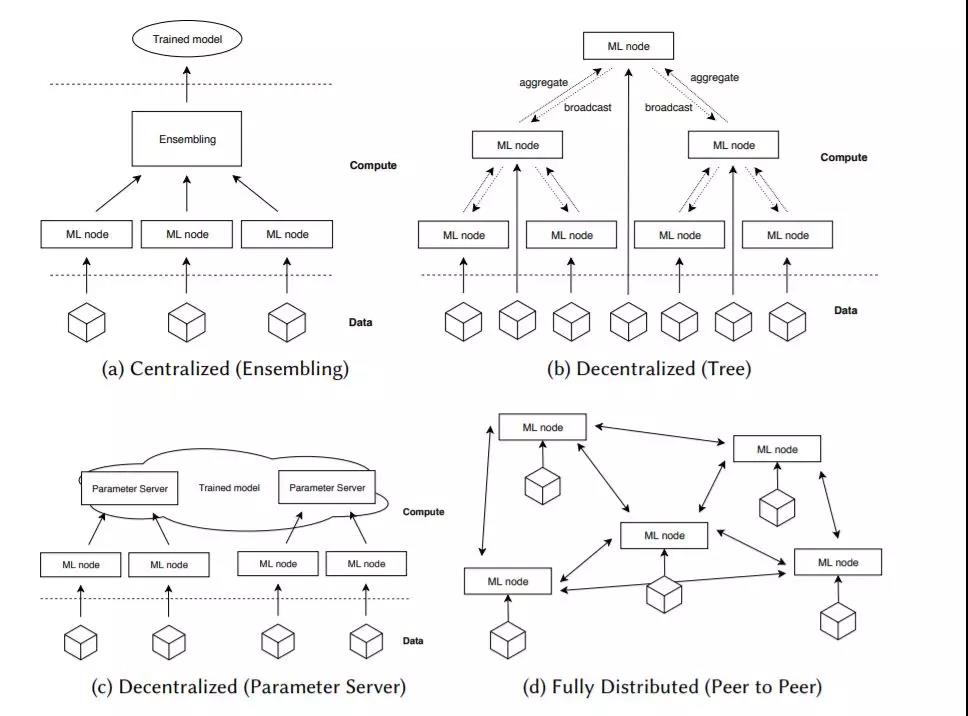
图3所示:基于分布程度的分布式机器学习拓扑
4. 分布式机器学习生态系统
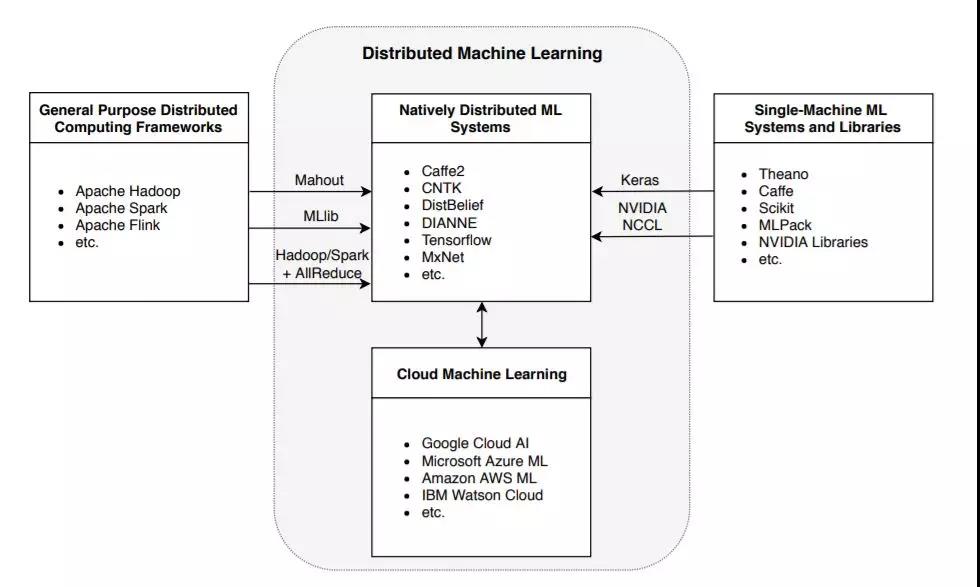
图4所示。分布式机器学习生态系统。通用分布式框架和单机ML系统和库都在向分布式机器学习靠拢。云是ML的一种新的交付模型。
5 结论和当前的挑战
分布式机器学习是一个蓬勃发展的生态系统,它在体系结构、算法、性能和效率方面都有各种各样的解决方案。为了使分布式机器学习在第一时间成为可行的,必须克服一些基本的挑战,例如,建立一种机制,使数据处理并行化,同时将结果组合成一个单一的一致模型。现在有工业级系统,针对日益增长的欲望与机器学习解决更复杂的问题,分布式机器学习越来越普遍和单机解决方案例外,类似于数据处理一般发展在过去的十年。然而,对于分布式机器学习的长期成功来说,仍然存在许多挑战:性能、容错、隐私、可移植性等。