近年来,人工智能(AI)及其应用引发了极大的兴趣。这一成就可以部分归因于人工智能子领域的进步,包括机器学习(ML)、计算机视觉(CV)和自然语言处理(NLP)。深度学习是机器学习的一个子领域,它采用人工神经网络的概念,使这些领域增长最快。因此,视觉和语言的融合引发了很多关注。这些任务的创建方式恰当地示范了深度学习的概念。本文对最先进的方法、关键模型设计原则进行了全面和广泛的回顾,并讨论了现有的数据集、方法及其问题表述和评估措施,用于VQA和视觉推理任务,以理解视觉和语言表示学习。本文还提出了该研究领域的一些潜在未来路径,希望我们的研究可以产生新的想法和新方法,以处理现有的困难和开发新的应用。
https://www.zhuanzhi.ai/paper/c05fe89db0bbc0ddc6f7535150f36371
1. 引言
深度神经网络(DNNs)的最新进展促进了人工智能(AI)许多领域的研究,如自然语言处理(NLP)和计算机视觉(CV)。随着计算资源的指数级增长和数据集规模的不断增大,卷积神经网络(CNN)[1]、循环神经网络(RNNs)[2]和自编码器[3]等DNNs模型在目标检测[4]、机器翻译[5]、图像标题生成[6]、语音识别[7]等机器学习(ML)任务中取得了巨大的胜利。尽管如此,在处理混合了两个通常独立领域的语义和视觉数据的问题时,仍然存在一些好奇心。解决集成问题的方法应该支持视觉或文本信息的全面知识。
尽管最近取得了一些进展,但在一些需要对关系和图结构数据进行推理的研究领域,如场景图[8]和自然语言理解,智能体和人脑之间仍然存在巨大的差距。人类可以快速识别物体、它们在网格上的位置和图像等欧几里得数据,推断它们的关系,识别活动,并响应关于图像的随机问题。建立一个具有计算机视觉和自然语言能力的系统模型,该系统可以回答关于图像的随机问题,这似乎很鼓舞人心。
有效地解决上述及相关问题可以带来许多可能的应用。例如,视觉障碍者可以受益于视觉场景理解,这允许他们通过生成的描述获取有关场景的信息并提出有关问题。理解监控视频是另一个用途。[9]、自动驾驶[10]、视觉解说机器人、人机交互[11]、城市导航[12]等解决这些问题通常需要对图像内容进行更高层次的推理。鉴于基础和应用研究的广泛跨度,近年来进行了各种调查,以提供视觉和语言任务集成的彻底概述。另一方面,这些研究侧重于涉及语言和视觉融合的特定任务,如图像描述[13-15]视觉问答[16,17]、动作识别[18]和视觉语义[19]。
本文对最先进的方法、关键模型设计原则进行了全面和广泛的回顾,并讨论了用于VQA和视觉推理任务的现有数据集和方法,以理解视觉和语言表示学习。首先,以视觉和语言表示学习任务为例介绍了视觉问答(VQA)和视觉推理。详细探索了现有的标注数据集驱动的这些领域的巨大进步。然后,进一步介绍了视觉问答和视觉推理的现有方法和最新进展;最后,讨论了存在的问题和未来可能的研究方向。
2. 视觉与语言
视觉和语言(V+L)研究是CV和NLP交叉的一个迷人的领域,它受到了两个群体的大量关注。许多V+L挑战促使组合式多模态表示学习取得了重大进展,已经在大规模人工标注数据集上进行了基准测试。V+L的基础是视觉理解主题,例如流行的ResNet,它提取CNN特征。其次是语言理解,其最终目标是多模态学习。
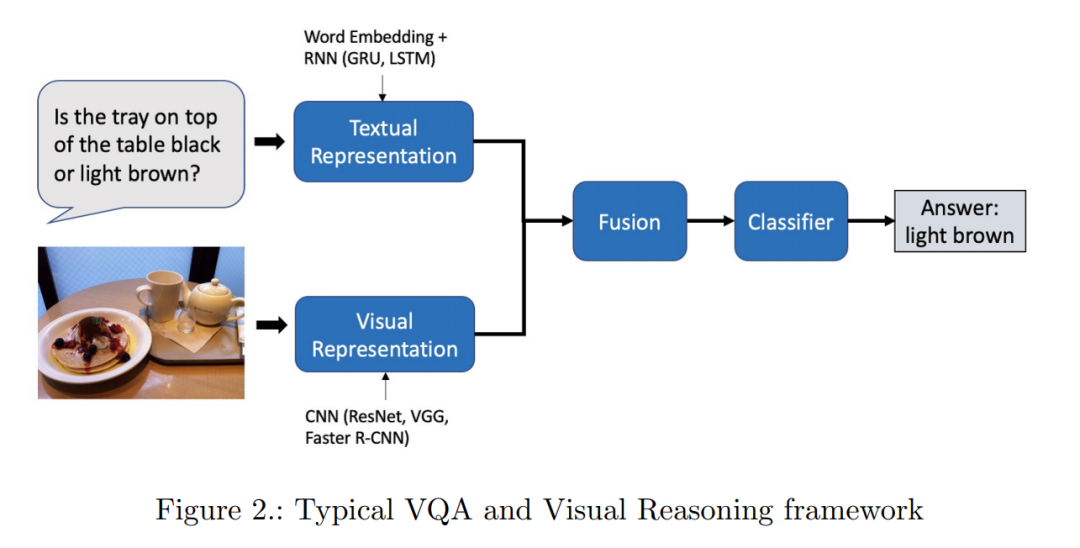
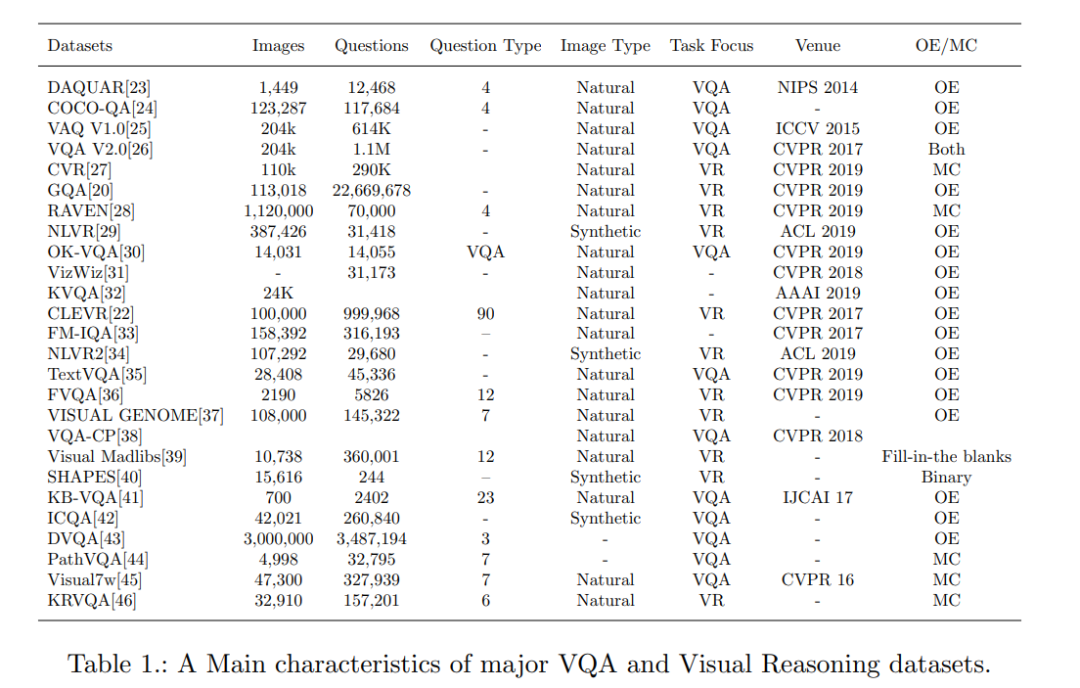
3. 数据集
我们有许多大规模的标注数据集,这些数据集正在推动这一领域的巨大进步。VQA领域是如此复杂,一个合适的数据集应该足够大,以表示现实世界中问题和视觉材料中的各种各样的选项。事实上,在过去的几年里,有许多流行的数据集来解决VQA和视觉推理的挑战。我们将在接下来的几节中讨论在这项艰巨任务中经常使用的数据集。
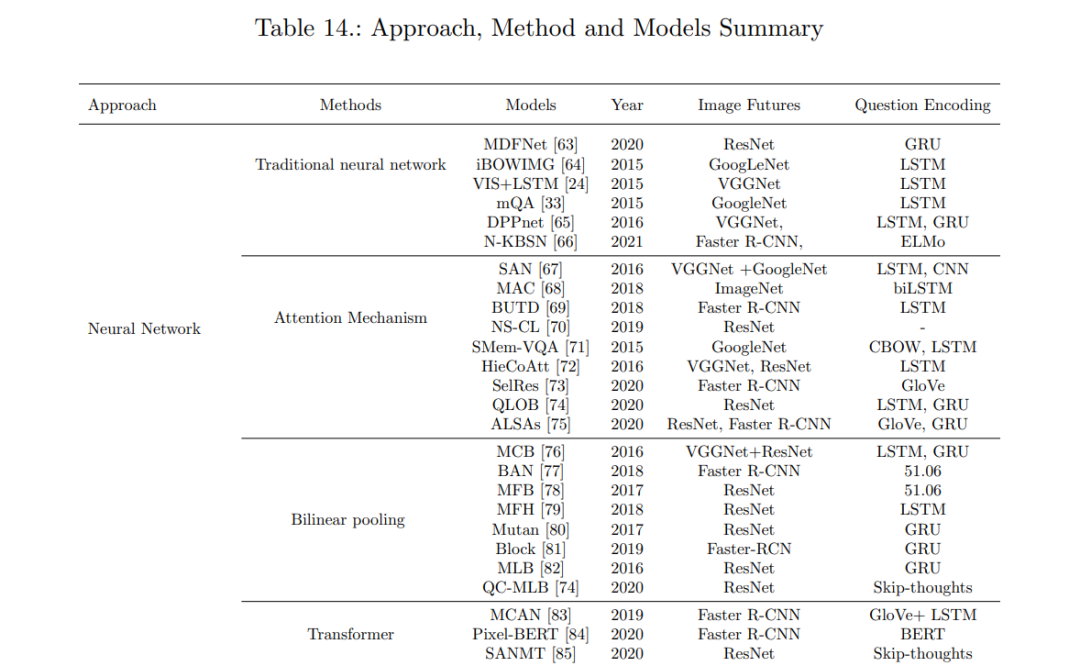
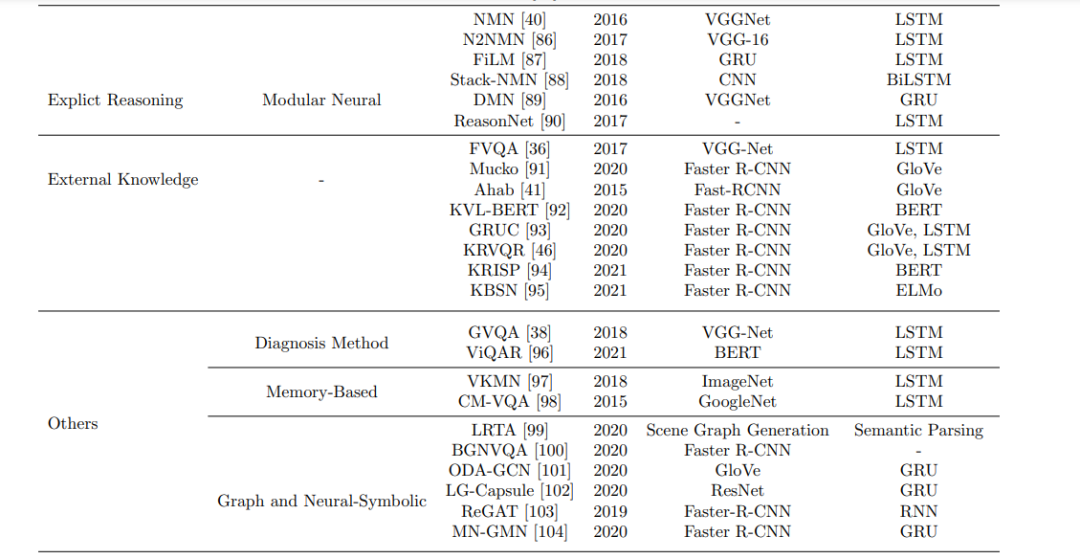
4. 方法
在过去的五年中,发展了大量的视觉问答和视觉推理方法。另一方面,所有已知的方法都是从问题和图像中提取特征,然后将特征组合起来给出答案。词袋模型(BOW)[61],长短期记忆网络(LSTM)[62],门控循环单元(GRU),编码器和跳过思维向量都可以用于文本。在ImageNet上预训练的CNN是最受欢迎的图像特征选择。在生成答案时,大多数技术都将问题表示为分类练习。因此,这些技术之间的主要区别在于它们如何合并文本和视觉数据。例如,将它们连接起来并通过线性分类器运行。此外,贝叶斯模型也可以用来表示问题、图像和答案特征分布之间的核心关系。在本节中,我们将介绍几种最近为VQA和视觉推理任务提出的架构。将这些模型分为三个主要部分:外部知识、神经网络和显式推理。下面我们将更详细地讨论每一节。