

在大量标记语音数据上使用监督学习算法训练的深度神经网络在各种语音处理应用中取得了显著的性能,往往在相应的排行榜上处于领先地位。然而,训练这些系统依赖于大量带注释的语音这一事实,为继续发展最先进的性能造成了可扩展性瓶颈,而且对在语音领域部署深度神经网络构成了更根本的障碍,因为标记数据本质上是罕见的,昂贵的,或耗时的收集。
与带注释的语音相比,未转录的音频通常积累起来要便宜得多。在这篇论文中,我们探索使用自我监督学习——一种学习目标由输入本身产生的学习范式——来利用这种易于扩展的资源来提高口语技术的性能。提出了两种自监督算法,一种基于"未来预测"的思想,另一种基于"从未被掩码中预测被掩码"的思想,用于从未标记语音数据中学习上下文化语音表示。我们证明了我们的自监督算法能够学习表征,将语音信号的高级属性,如语音内容和说话人特征转换为比传统声学特征更容易获得的形式,并证明了它们在提高深度神经网络在广泛的语音处理任务中的性能方面的有效性。除了提出新的学习算法,我们还提供了广泛的分析,旨在理解学习的自监督表示的属性,以及揭示使一个自监督模型不同于另一个的设计因素。 https://dspace.mit.edu/handle/1721.1/144761
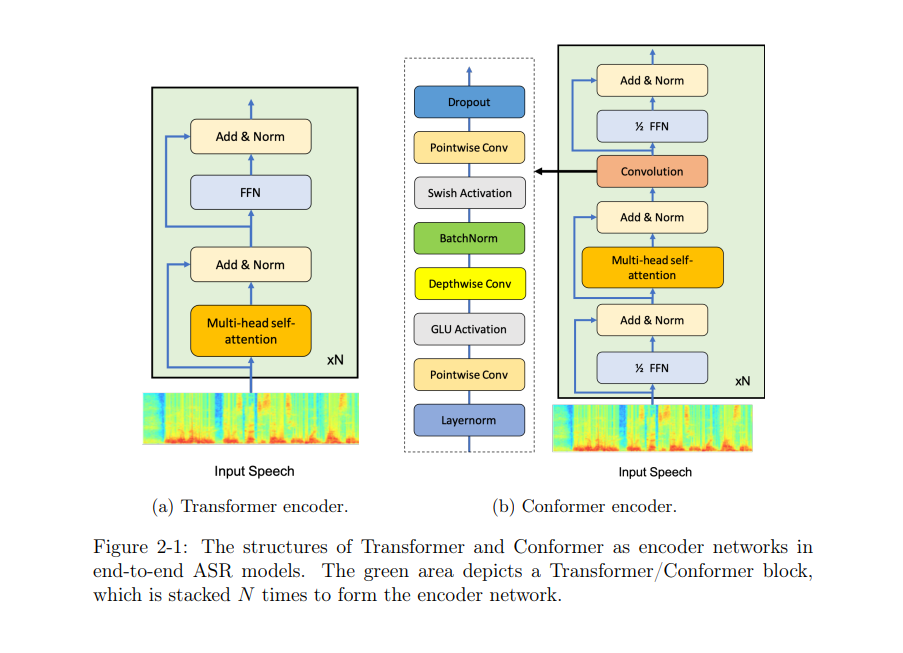
如今,深度神经网络或深度学习技术为最先进的人工智能系统提供了能力,用于各种数据类型的广泛应用——图像分类(He et al.,2016;Liu et al.,2022)、机器翻译(Vaswani et al.,2017)和语音识别(Gulati et al.,2020)等等。然而,训练这些系统的传统范式一直是监督学习,其中系统的性能随着用于训练它们的标记数据的大小大致呈对数增长(Sun et al.,2017)。获取这种带注释的数据的成本已经被证明是最先进系统持续开发的可扩展瓶颈,而且对于在数据和注释收集本来就很少、昂贵或耗时的应用领域部署深度神经网络来说,这是一个更根本的障碍。
上述情况激发了一波关于自监督表征学习的研究浪潮,其中,由精心设计的前置任务生成的免费标签被用作监督信号,以预训练深度神经网络。然后,从预训练的深度神经网络的参数全部或部分用于初始化任务特定的深度神经网络的参数,以解决下游的任务,使用比传统监督学习相对较少的注释数据。自监督指的是要求深度神经网络预测给定的输入数据的一部分(或通过编程派生的标签)的学习任务。
自监督学习技术已被成功地用于提高各种模式下学习的样本效率,包括图像(Chen et al., 2020; Grill et al., 2020; Caron et al., 2020),视频(Xu et al., 2019; Alwassel et al., 2020),语音和音频(Baevski et al., 2020b; Gong et al., 2022),文本(Mikolov et al., 2013; Peters et al., 2018b; Devlin et al., 2019; Liu et al., 2019),到图表(Velickovic et al.,2019年),举几个例子。一些结果表明,自监督表示的质量也是未标记训练前数据量的对数函数(Goyal等人,2019)。如果这一趋势保持不变,那么随着时间的推移,可实现的性能可能会“免费”提高,因为数据收集和计算能力的改进允许使用越来越大的预训练集,而不需要手动注释新数据。在本论文中,我们着重于将自监督学习策略应用于语音领域,目的是推动口语技术的最先进性能,并提高训练它们的数据效率。我们致力于开发新的自监督语音表征学习方法,并分析其学习表征的特性。
论文贡献:
1. 介绍了最早成功的自监督语音表征学习框架之一。我们利用了“未来预测”的思想,并提出了一个简单而有效的自监督目标,称为自回归预测编码(APC),用于训练深度神经网络。设计的未来帧预测任务能够利用未标记的语音数据学习表示,使语音的高级属性,如语音内容和说话人的特征更容易被下游任务访问(定义为线性可分性)。APC是最早展示自监督表征优于传统手工制作的声学特征(如Mel-frequency倒谱系数(MFCCs)和log Mel 声谱图)的工作之一,表明使用自监督学习来提高口语技术表现的潜力。
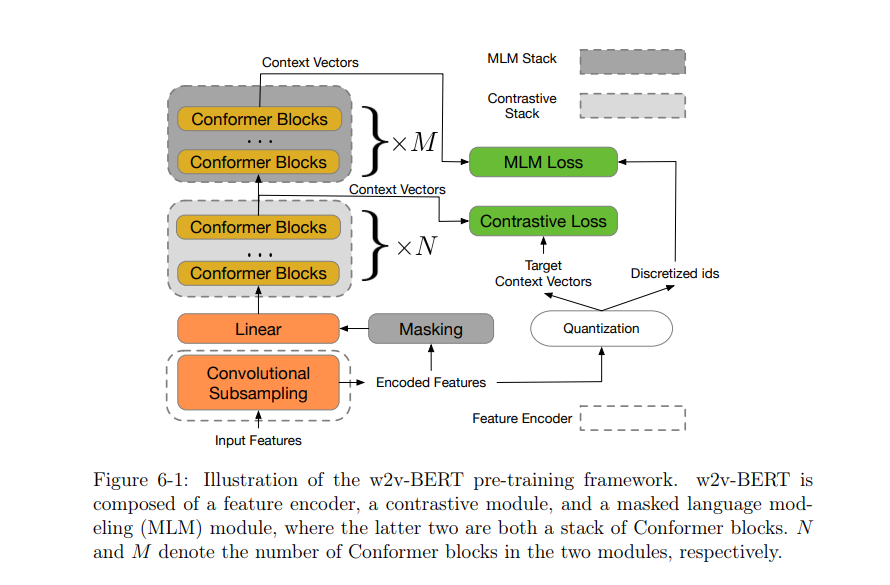
2. 介绍了目前最先进的自监督语音表示学习框架之一。我们利用了“从未掩码中预测掩码”的想法,并提出了w2v-BERT,这是目前最先进的框架之一,用于对语音应用的深度神经网络进行预训练。我们训练一个语音离散器(通过优化对比损失)来将连续语音信号表示为鉴别标记,并使用它们来训练一个类似BERT的模型。与vq-wav2vec和HuBERT等现有框架相比,w2v-BERT可以以端到端方式优化离散化器和上下文网络,避免了多个训练阶段之间的协调,这些阶段往往涉及脆弱的建模选择。我们展示了w2v-BERT的有效性,在基准良好的语音识别数据集和谷歌收集的语音搜索数据集上,它优于包括HuBERT和wav2vec 2.0在内的最新技术。
3.引入一种分析方法,能够在自监督的目标和他们学习表示的属性之间建立连接。我们探索使用矢量量化来控制深度神经网络内部的信息流量,以获得具有相同的自监督目标但模型容量下降的模型谱。我们将这种分析方法应用于APC的研究,并诊断了APC在模型容量受限时保存信息的偏好。我们的分析结果解释了为什么APC可以学习捕捉高级语音和说话人信息的表征。该分析方法具有普适性,也可用于其他自监督目标的分析。
4. 不同自监督模型的几个共享性质的演示。在分析我们自己和其他已有的自监督模型时,我们发现,尽管这些模型在训练目标和神经网络结构上存在差异,但它们都存在一些共同的特性。这类属性之一就是隐式发现有意义的声音单元库存的能力。我们发现,在自监督模型中通常存在一些层,其中表示与英语电话具有相当高的互信息(当模型在英语语料库上训练时),即使模型没有明确地训练以发现它们。大多数自监督模型共有的另一个特性是,不同层次的语音信息被捕获在不同的层中,尽管信息分布可能因模型而异。例如,在APC中,较低的层次往往对说话者更具辨别能力,而较高层提供更多的语音内容。意识到这一点有助于选择适当的层,从中提取表示,以便在感兴趣的任务中获得最佳性能。
5. 识别训练影响其表征相似性的自监督模型的建模因素的重要性顺序。我们在训练过程中比较了一组具有不同建模选择的自监督模型,并使用诸如典型相关分析(CCA)等措施来量化它们的两两相似性。我们考虑了三个建模因素: 训练目标、模型的方向性(即模型是单向的还是双向的)和神经网络构建块(CNN/RNN/Transformer),并表明这三个因素在使一个自监督表示不同于另一个方面具有不同的权重。具体而言,我们发现在所有因素中,训练目标对表征相似性的影响最大;在相同的训练目标下,模型的方向性对表征相似性的影响大于其神经网络构件。






